Introduction
Anomaly detection is broadly utilized throughout varied industries, taking part in a big position within the enterprise sector. This weblog focuses on its software in manufacturing, the place it yields appreciable enterprise advantages. We’ll discover a case examine centered on monitoring the well being of a simulated course of subsystem. The weblog will delve into dimension discount strategies like Principal Element Evaluation (PCA) and look at the real-world impression of implementing such techniques in a manufacturing setting. By analyzing a real-life instance, we’ll display how this method will be scaled as much as extract helpful insights from in depth sensor information, using Databricks as a software.
LP Constructing Options (LP) is a wood-based product manufacturing firm with an over 50-year observe report of shaping the constructing trade. With operations in North and South America, LP manufactures constructing product options with moisture, hearth, and termite resistance. At LP, petabytes of historic course of information have been collected for years together with environmental, well being, and security (EHS) information. Massive quantities of those historic information have been saved and maintained in a wide range of techniques equivalent to on-premise SQL servers, information historian databases, statistical course of management software program, and enterprise asset administration options. Each millisecond, sensor information is collected all through the manufacturing processes for all of their mills from dealing with uncooked supplies to packaging completed merchandise. By constructing lively analytical options throughout a wide range of information, the information staff has the flexibility to tell decision-makers all through the corporate on operational processes, conduct predictive upkeep, and achieve insights to make knowledgeable data-driven choices.
One of many largest data-driven use instances at LP was monitoring course of anomalies with time-series information from 1000’s of sensors. With Apache Spark on Databricks, giant quantities of knowledge will be ingested and ready at scale to help mill decision-makers in bettering high quality and course of metrics. To organize these information for mill information analytics, information science, and superior predictive analytics, it’s mandatory for firms like LP to course of sensor info sooner and extra reliably than on-premises information warehousing options alone
Structure
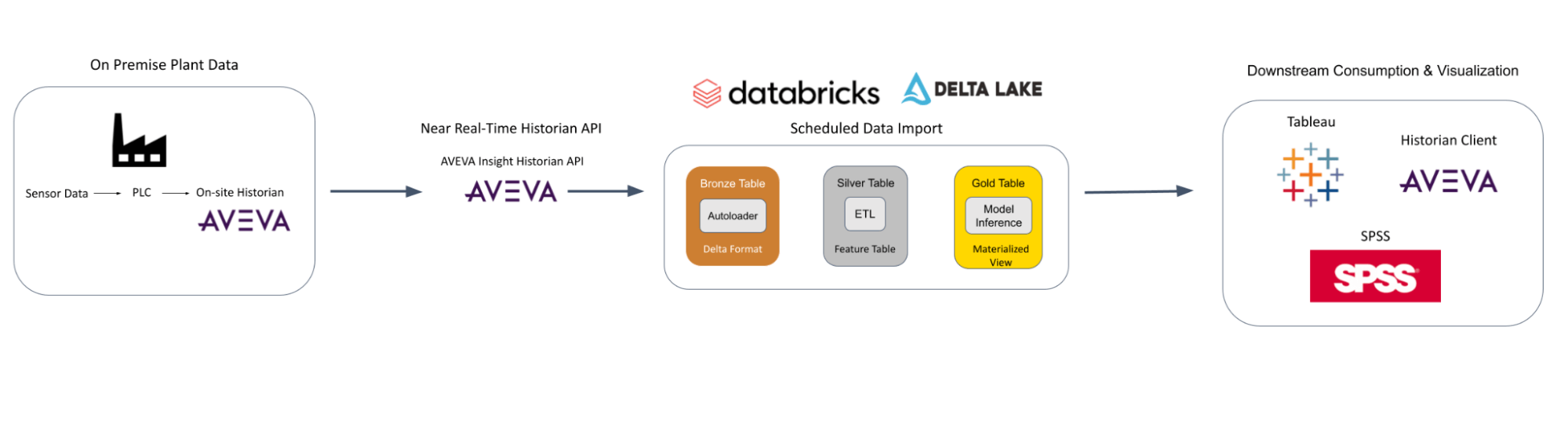
ML Modeling a Simulated Course of
For instance, let’s contemplate a situation the place small anomalies upstream in a course of for a specialty product develop into bigger anomalies in a number of techniques downstream. Let’s additional assume that these bigger anomalies within the downstream techniques have an effect on product high quality, and trigger a key efficiency attribute to fall under acceptable limits. Utilizing prior data in regards to the course of from mill-level consultants, together with modifications within the ambient setting and former product runs of this product, it is doable to foretell the character of the anomaly, the place it occurred, and the way it can have an effect on downstream manufacturing.

First, a dimensionality discount method of the time-series sensor information would enable for identification of kit relationships that will have been missed by operators. The dimensionality discount serves as a information for validating relationships between items of kit that could be intuitive to operators who’re uncovered to this tools on daily basis. The first purpose right here is to cut back the variety of correlated time sequence overhead into comparatively unbiased and related time-based relationships as a substitute. Ideally, this could begin with course of information with as a lot variety in acceptable product SKUs and operational home windows as doable. These components will enable for a workable tolerance.
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
names=model_features.columns
x = model_features[names].dropna()
scaler = StandardScaler()
pca = PCA()
pipeline = make_pipeline(scaler, pca)
pipeline.match(x)Plotting
options = vary(pca.n_components_)
_ = plt.determine(figsize=(15, 5))
_ = plt.bar(options, pca.explained_variance_)
_ = plt.xlabel('PCA characteristic')
_ = plt.ylabel('Variance')
_ = plt.xticks(options)
_ = plt.title("Significance of the Principal Parts primarily based on inertia")
plt.present()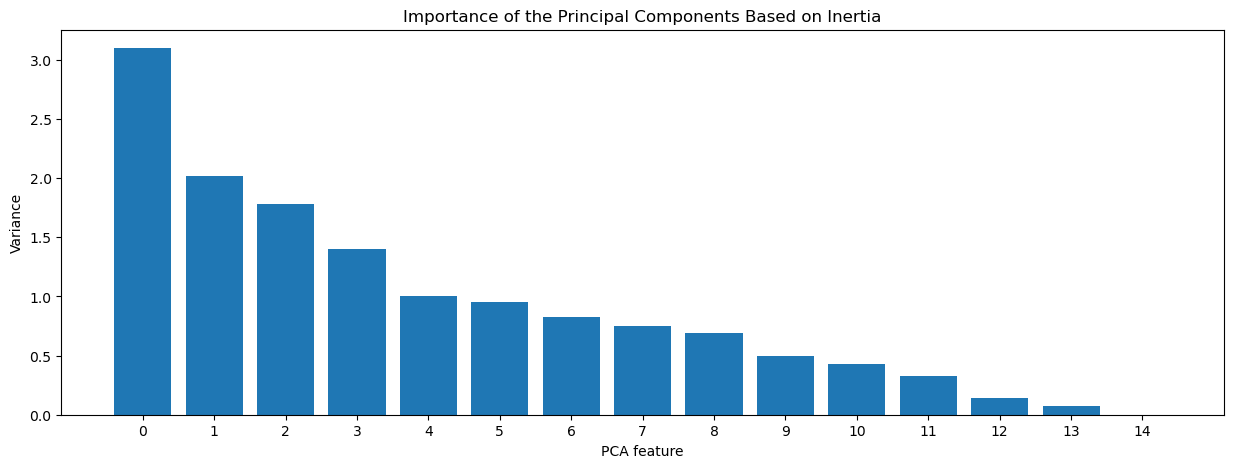
Subsequent, these time-based relationships will be fed into an anomaly detection mannequin to establish irregular behaviors. By detecting anomalies in these relationships, modifications in relationship patterns will be attributed to course of breakdown, downtime, or basic put on and tear of producing tools. This mixed method will use a mix of dimensionality discount and anomaly detection methods to establish system- and process-level failures. As an alternative of counting on anomaly detection strategies on each sensor individually, it may be much more highly effective to make use of a mixed method to establish holistic sub-system failures. There are various pre-built packages that may be mixed to establish relationships after which establish anomalies inside these relationships. One such instance of a pre-built package deal that may deal with that is pycaret.
from pycaret.anomaly import *
db_ad = setup(information = databricks_df, pca = True,use_gpu = True)fashions()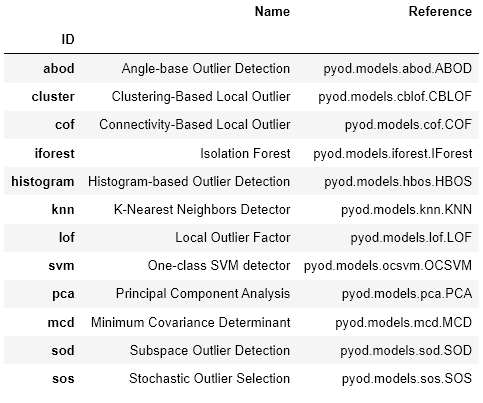
mannequin = create_model('cluster')
model_result = assign_model(mannequin)
print(model_result.Anomaly.value_counts(normalize=True))
model_resultFashions needs to be run at common intervals to establish doubtlessly critical course of disruptions earlier than the product is accomplished or results in extra critical downstream interruptions. If doable, all anomalies needs to be investigated by both a high quality supervisor, web site reliability engineer, upkeep supervisor, or environmental supervisor relying on the character and placement of the anomaly.
Whereas AI and information availability are the important thing to delivering fashionable manufacturing functionality, insights and course of simulations imply nothing if the plant flooring operators can’t act upon them. Transferring from information assortment from sensors to data-driven insights, traits, and alerts typically requires the talent set of cleansing, munging, modeling, and visualizing in real- or close to real-time timescales. This could enable plant decision-makers to reply to sudden course of upsets in the mean time earlier than product high quality is affected.
CI/CD and MLOps for Manufacturing Information Science
Finally, any anomaly detection mannequin educated on these information will change into much less correct over time. To handle this, a knowledge drift monitoring system can proceed to run as a test in opposition to intentional system modifications versus unintentional modifications. Moreover, intentional disruptions that contribute to modifications in course of response will happen that the mannequin won’t have seen earlier than. These disruptions can embody changed items of kit, new product SKUs, main tools restore, or modifications in uncooked materials. With these two factors in thoughts, information drift displays needs to be carried out to establish intentional disruptions from unintentional disruptions by checking in with plant-level consultants on the method. Upon verification, the outcomes will be integrated into the earlier dataset for retraining of the mannequin.
Mannequin growth and administration profit enormously from strong cloud compute and deployment sources. MLOps, as a apply, presents an organized method to managing information pipelines, addressing information shifts, and facilitating mannequin growth via DevOps greatest practices. At the moment, at LP, the Databricks platform is used for MLOps capabilities for each real-time and close to real-time anomaly predictions along with Azure Cloud-native capabilities and different inner tooling. This built-in method has allowed the information science staff to streamline the mannequin growth processes, which has led to extra environment friendly manufacturing timelines. This method permits the staff to focus on extra strategic duties, making certain the continued relevance and effectiveness of their fashions.
Abstract
The Databricks platform has enabled us to make the most of petabytes of time sequence information in a manageable method. We used Databricks to do the next:
- Streamline the information ingestion course of from varied sources and effectively retailer the information utilizing Delta Lake.
- Rapidly rework and manipulate information to be used in ML in an environment friendly and distributed method.
- Observe ML fashions and automatic information pipelines for CI/CD MLOps deployment.
These have helped our group make environment friendly data-driven choices that improve success and productiveness for LP and our prospects.
To be taught extra about MLOps, please discuss with the massive e-book of MLOps and for a deeper dive into the technical intricacies of anomaly detection utilizing Databricks, please learn the linked weblog.