The Databricks / Mosaic R&D workforce launched the primary iteration of our inference service structure solely seven months in the past; since then, we’ve been making super strides in delivering a scalable, modular, and performant platform that is able to combine each new advance within the fast-growing generative AI panorama. In January 2024, we are going to begin utilizing a brand new inference engine for serving Giant Language Fashions (LLMs), constructed on NVIDIA TensorRT-LLM.
Introducing NVIDIA TensorRT-LLM
TensorRT-LLM is an open supply library for state-of-the-art LLM inference. It consists of a number of elements: first-class integration with NVIDIA’s TensorRT deep studying compiler, optimized kernels for key operations in language fashions, and communication primitives to allow environment friendly multi-GPU serving. These optimizations seamlessly work on inference companies powered by NVIDIA Tensor Core GPUs and are a key a part of how we ship state-of-the-art efficiency.
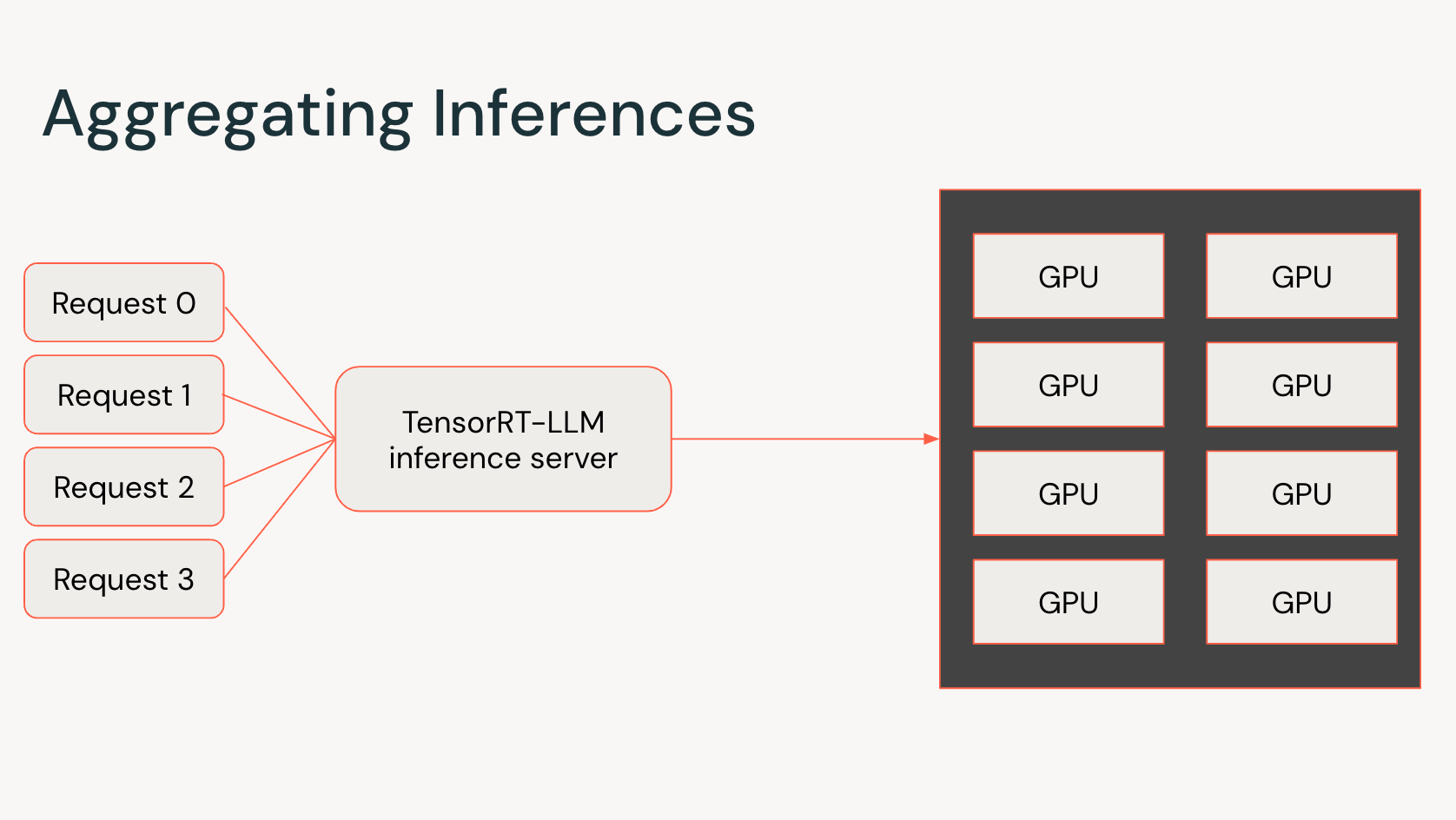
For the final six months, we’ve been collaborating with NVIDIA to combine TensorRT-LLM with our inference service, and we’re enthusiastic about what we’ve been in a position to accomplish. Utilizing TensorRT-LLM, we’re in a position to ship a big enchancment in each time to first token and time per output token. As we mentioned in an earlier publish, these metrics are key estimators for the standard of the consumer expertise when working with LLMs.
Our collaboration with NVIDIA has been mutually advantageous. Through the early entry part of the TensorRT-LLM challenge, our workforce contributed MPT mannequin conversion scripts, making it quicker and simpler to serve an MPT mannequin instantly from Hugging Face, or your individual pre-trained or fine-tuned mannequin utilizing the MPT structure. In flip, NVIDIA ’s workforce augmented MPT mannequin help by including set up directions, in addition to introducing quantization and FP8 help on H100 Tensor Core GPUs. We’re thrilled to have first-class help for the MPT structure in TensorRT-LLM, as this collaboration not solely advantages our workforce and clients, but in addition empowers the broader neighborhood to freely adapt MPT fashions for his or her particular wants with state-of-the-art inference efficiency.
Flexibility Via Plugins
Extending TensorRT-LLM with newer mannequin architectures has been a clean course of. The inherent flexibility of TensorRT-LLM and its capacity so as to add totally different optimizations via plugins enabled our engineers to shortly modify it to help our distinctive modeling wants. This flexibility has not solely accelerated our improvement course of but in addition alleviated the necessity for the NVIDIA workforce to single-handedly help all consumer necessities.
A Crucial Part for LLM Inference
We have performed complete benchmarks of TensorRT-LLM throughout all GPU fashions (A10G, A100, H100) on every cloud platform. To attain optimum latency at minimal price, we have optimized the TensorRT-LLM configuration reminiscent of steady batch sizes, tensor sharding, and mannequin pipelining which we’ve got coated earlier. We have deployed the optimum configuration for high LLM fashions together with LLAMA-2 and Mixtral for every cloud and occasion configuration and can proceed to take action as new fashions and {hardware} are launched. You’ll be able to all the time get the perfect LLM efficiency out of the field with Databricks mannequin serving!
Python API for Simpler Integration
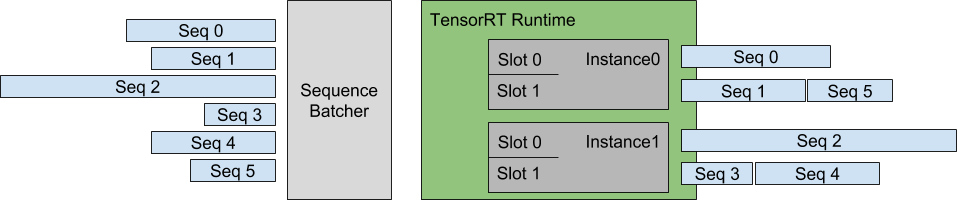
TensorRT-LLM’s offline inference efficiency turns into extra highly effective when utilized in tandem with its native in-flight (steady) batching help. We’ve discovered that in-flight batching is an important element of sustaining excessive request throughput in settings with a lot of site visitors. Lately, the NVIDIA workforce has been engaged on Python help for the batch supervisor written in C++, permitting TensorRT-LLM to be seamlessly built-in into our backend internet server.
Able to Start Experimenting?
In case you’re a Databricks buyer, you should utilize our inference server by way of our AI Playground (at present in public preview) at this time. Simply log in and discover the Playground merchandise within the left navigation bar beneath Machine Studying.
We wish to thank the workforce at NVIDIA for being terrific collaborators as we’ve labored via the journey of integrating TensorRT-LLM because the inference engine for internet hosting LLMs. We will be leveraging TensorRT-LLM as a foundation for our improvements in the upcoming releases of the Databricks Inference Engine. We’re trying ahead to sharing our platform’s efficiency enhancements over earlier implementations. (It’s additionally vital to notice that vLLM, a big open-source neighborhood effort for environment friendly LLM inference, offers one other nice choice and is gaining momentum.) Keep tuned for an upcoming weblog publish with a deeper dive into the efficiency particulars subsequent month.