Adopting AI is existentially very important for many companies
Machine Studying (ML) and generative AI (GenAI) are revolutionizing the way forward for work. Organizations perceive that AI helps construct innovation, keep competitiveness, and enhance the productiveness of their staff. Equally, organizations perceive that their knowledge supplies a aggressive benefit for his or her AI purposes. Leveraging these applied sciences presents alternatives but additionally potential dangers to organizations, as embracing them with out correct safeguards may end up in important mental property and reputational loss.
In our conversations with prospects, they steadily cite dangers equivalent to knowledge loss, knowledge poisoning, mannequin theft, and compliance and regulation challenges. Chief Info Safety Officers (CISOs) are beneath stress to adapt to enterprise wants whereas mitigating these dangers swiftly. Nevertheless, if CISOs say no to the enterprise, they’re perceived as not being crew gamers and placing the enterprise first. Alternatively, they’re perceived as careless if they are saying sure to doing one thing dangerous. Not solely do CISOs must sustain with the enterprise’ urge for food for progress, diversification, and experimentation, however they should sustain with the explosion of applied sciences promising to revolutionize their enterprise.
Half 1 of this weblog sequence will focus on the safety dangers CISOs must know as their group evaluates, deploys, and adopts enterprise AI purposes.
Your knowledge platform ought to be an professional on AI safety
At Databricks, we imagine knowledge and AI are your most valuable non-human property, and that the winners in each trade will probably be knowledge and AI corporations. That is why safety is embedded within the Databricks Information Intelligence Platform. The Databricks Information Intelligence Platform permits your whole group to make use of knowledge and AI. It is constructed on a lakehouse to supply an open, unified basis for all knowledge and governance, and is powered by a Information Intelligence Engine that understands the distinctiveness of your knowledge.
Our Databricks Safety crew works with hundreds of consumers to securely deploy AI and machine studying on Databricks with the suitable safety features that meet their structure necessities. We’re additionally working with dozens of consultants internally at Databricks and within the bigger ML and GenAI neighborhood to determine safety dangers to AI techniques and outline the controls essential to mitigate these dangers. We’ve got reviewed quite a few AI and ML danger frameworks, requirements, suggestions, and steerage. In consequence, we now have sturdy AI safety tips to assist CISOs and safety groups perceive find out how to deploy their organizations’ ML and AI purposes securely. Nevertheless, earlier than discussing the dangers to ML and AI purposes, let’s stroll by means of the constituent parts of an AI and ML system used to handle the info, construct fashions, and serve purposes.
Understanding the core parts of an AI system for efficient safety
AI and ML techniques are comprised of information, code, and fashions. A typical system for such an answer has 12 foundational structure parts, broadly categorized into 4 main phases:
- Information operations encompass ingesting and reworking knowledge and making certain knowledge safety and governance. Good ML fashions depend upon dependable knowledge pipelines and safe infrastructure.
- Mannequin operations embody constructing customized fashions, buying fashions from a mannequin market, or utilizing SaaS LLMs (like OpenAI). Creating a mannequin requires a sequence of experiments and a strategy to monitor and evaluate the circumstances and outcomes of these experiments.
- Mannequin deployment and serving consists of securely constructing mannequin photos, isolating and securely serving fashions, automated scaling, charge limiting, and monitoring deployed fashions.
- Operations and platform embody platform vulnerability administration and patching, mannequin isolation and controls to the system, and approved entry to fashions with safety within the structure. It additionally consists of operational tooling for CI/CD. It ensures the entire lifecycle meets the required requirements by protecting the distinct execution environments – growth, staging, and manufacturing for safe MLOps.
MLOps is a set of processes and automatic steps to handle the AI and ML system’s code, knowledge, and fashions. MLOps ought to be mixed with safety operations (SecOps) practices to safe the whole ML lifecycle. This consists of defending knowledge used for coaching and testing fashions and deploying fashions and the infrastructure they run on from malicious assaults.
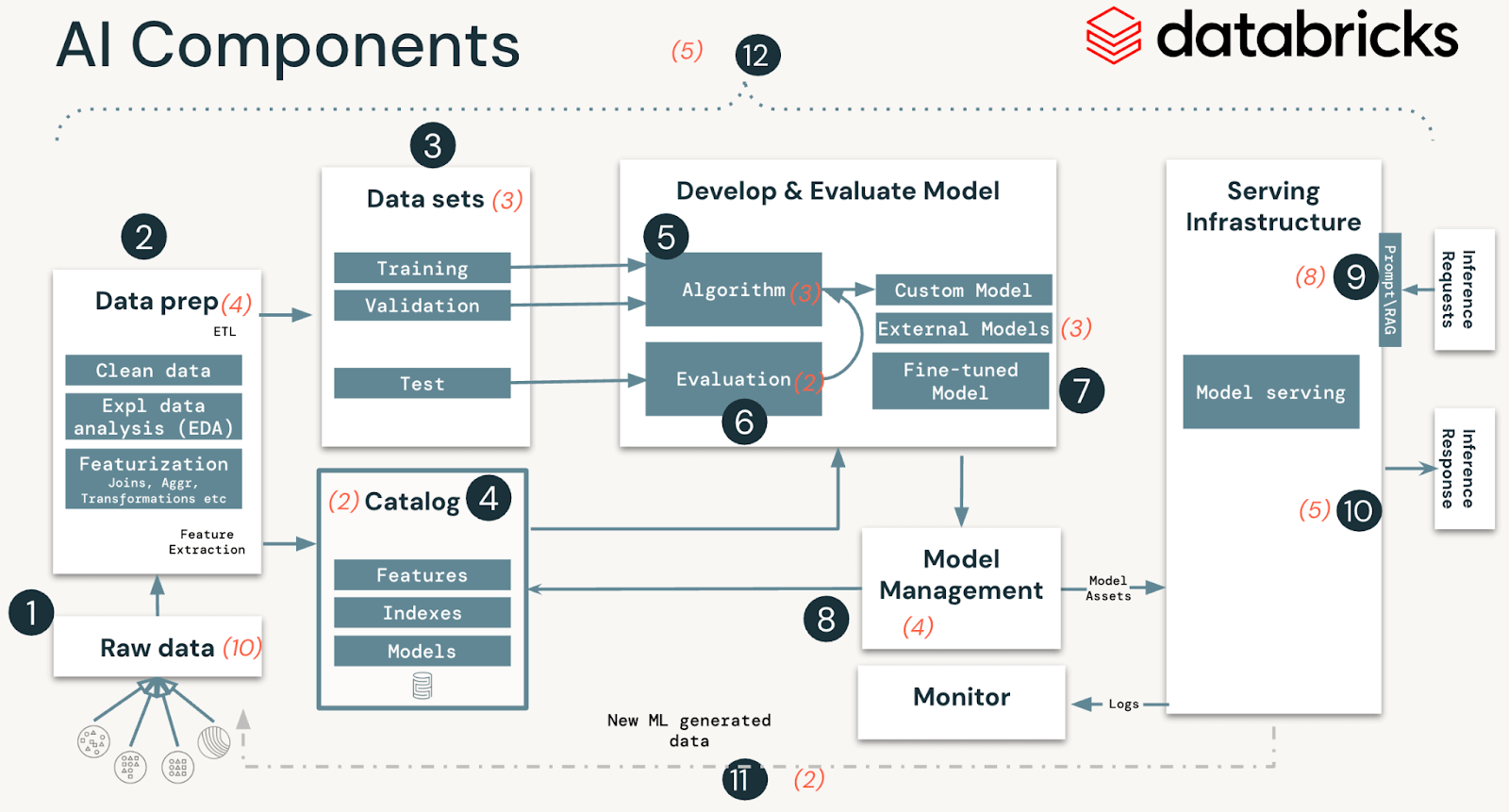
High safety dangers of AI and ML techniques
Technical Safety Dangers
In our evaluation of AI and ML techniques, we recognized 51 technical safety dangers throughout the 12 parts. Within the desk under, we define these primary parts that align with steps in any AI and ML system and spotlight the sorts of safety dangers our crew recognized:
| System stage | System parts (Determine 1) | Potential safety dangers |
|---|---|---|
| Information operations |
|
19 particular dangers, equivalent to
|
| Mannequin operations |
|
12 particular dangers, equivalent to
|
| Mannequin deployment and serving |
|
13 particular dangers, equivalent to
|
| Operations and Platform |
|
7 particular dangers, equivalent to
|
Databricks has mitigation controls for all the above-outlined dangers. In a future weblog and whitepaper, we are going to stroll by means of the entire listing of dangers in addition to our steerage on the related controls and out-of-the-box capabilities like Databricks Delta Lake, Databricks Managed MLflow, Unity Catalog, and Mannequin Serving that you should use as mitigation controls to the above dangers.
Organizational Safety Dangers
Along with the technical dangers, our discussions with CISOs have highlighted the need of addressing 4 organizational danger areas to ease the trail to AI and ML adoption. These are key to aligning the safety operate with the wants, tempo, outcomes and danger urge for food of the enterprise they serve.
- Expertise: Safety organizations can lag the remainder of the group when adopting new applied sciences. CISOs want to know which roles of their expertise pool ought to upskill to AI and implement MLSecOps throughout departments.
- Working mannequin: Figuring out the important thing stakeholders, champions, and enterprise-wide processes to securely deploy new AI use instances is crucial to assessing danger ranges and discovering the correct path to deploying purposes.
- Change administration: Discovering hurdles for change, speaking expectations, and eroding inertia to speed up by leveraging an organizational change administration framework, e.g., ADKAR, and many others., helps organizations to allow new processes with minimal disruption.
- Determination help: Tying technical work to enterprise outcomes for prioritizing which technical efforts or enterprise use instances is essential to arriving at a single set of organization-wide priorities.
Mitigate AI safety dangers successfully with our CISO-driven workshop
CISOs are instinctive danger assessors. Nevertheless, this superpower fails most CISOs in the case of AI. The first purpose is that CISOs haven’t got a easy psychological mannequin of an AI and ML system that they will readily visualize to synthesize property, threats, impacts, and controls.
That can assist you with this, the Databricks Safety crew has designed a brand new machine studying and generative AI safety workshop for CISOs and safety leaders. The content material of those workshops is additional being developed right into a framework for managing AI Safety to render CISOs’ instinctive superpower of assessing danger to be operable and efficient concerning AI.
As a sneak peek, here is the top-line method we advocate for managing the technical safety dangers of ML and AI purposes at scale:
- Determine the ML Enterprise Use Case: Be certain there’s a well-defined use case with stakeholders you are attempting to safe adequately, whether or not already carried out or in planning phases.
- Decide ML Deployment Mannequin: Select an applicable mannequin (e.g., Customized, SaaS LLM, RAG, fine-tuned mannequin, and many others.) to find out how shared tasks (particularly for securing every part) are cut up throughout the 12 ML/GenAI parts between your group and any companions concerned.
- Choose Most Pertinent Dangers: From our documented listing of 51 ML dangers, pinpoint probably the most related to your group primarily based on the result of step #2.
- Enumerate Threats for Every Danger: Determine the particular threats linked to every danger and the focused ML/GenAI part for each risk.
- Select and Implement Controls: Choose controls that align along with your group’s danger urge for food. These controls are outlined generically for compatibility with any knowledge platform. Our framework additionally supplies tips on tailoring these controls particularly for the Databricks setting.
- Operationalize Controls: Decide management homeowners, lots of whom you would possibly inherit out of your knowledge platform supplier. Guarantee controls are carried out, monitored for effectiveness, and often reviewed. Changes could also be wanted primarily based on modifications in enterprise use instances, deployment fashions, or evolving risk landscapes.
Be taught extra and join with our crew
If you happen to’re all in favour of collaborating in one in all our CISO workshops or reviewing our upcoming Databricks AI Safety Framework whitepaper, contact [email protected].
If you’re interested by how Databricks approaches safety, please go to our Safety and Belief Middle.