
Posted by Santiago Aboy Solanes – Software program Engineer

The Android Runtime (ART) executes Dalvik bytecode produced from apps and system providers written within the Java or Kotlin languages. We continuously enhance ART to generate smaller and extra performant code. Bettering ART makes the system and user-experience higher as an entire, as it’s the frequent denominator in Android apps. On this weblog publish we’ll speak about optimizations that cut back code dimension with out impacting efficiency.
Code dimension is without doubt one of the key metrics we take a look at, since smaller generated information are higher for reminiscence (each RAM and storage). With the brand new launch of ART, we estimate saving customers about 50-100MB per system. This may very well be simply the factor you want to have the ability to replace your favourite app, or obtain a brand new one. Since ART has been updateable from Android 12, these optimizations attain 1B+ gadgets for whom we’re saving 47-95 petabytes (47-95 hundreds of thousands of GB!) globally!
All of the enhancements talked about on this weblog publish are open supply. They’re obtainable by way of the ART mainline replace so that you don’t even want a full OS replace to reap the advantages. We will have our upside-down cake and eat it too!
Optimizing compiler 101
ART compiles purposes from the DEX format to native code utilizing the on-device dex2oat instrument. Step one is to parse the DEX code and generate an Intermediate Illustration (IR). Utilizing the IR, dex2oat performs quite a lot of code optimizations. The final step of the pipeline is a code technology part the place dex2oat converts the IR into native code (for instance, AArch64 meeting).
The optimization pipeline has phases that execute so that every focus on a selected set of optimizations. For instance, Fixed Folding is an optimization that tries to exchange directions with fixed values like folding the addition operation 2 + 3 right into a 5.
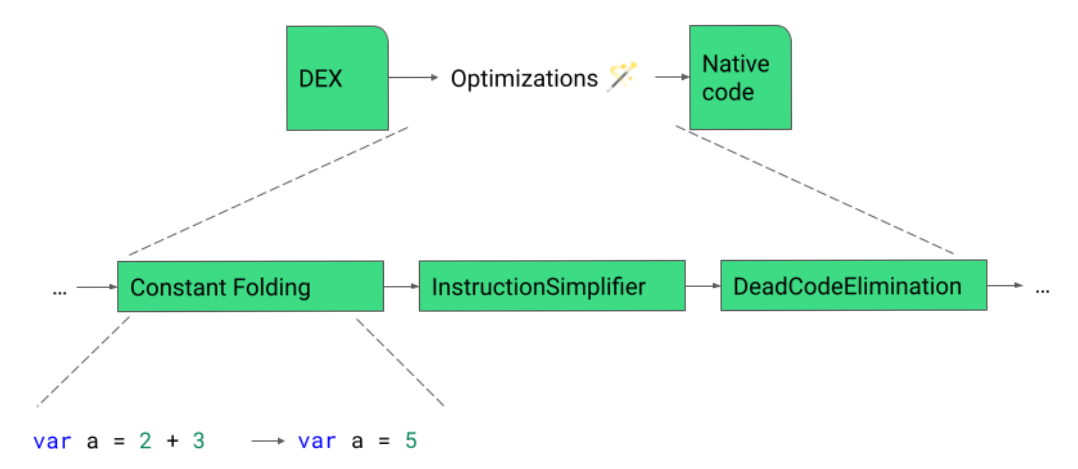
The IR will be printed and visualized, however could be very verbose in comparison with Kotlin language code. For the needs of this weblog publish, we’ll present what the optimizations do utilizing Kotlin language code, however know that they’re occurring to IR code.
Code dimension enhancements
For all code dimension optimizations, we examined our optimizations on over half one million APKs current within the Google Play Retailer and aggregated the outcomes.
Eliminating write boundaries
Now we have a new optimization move that we named Write Barrier Elimination. Write boundaries monitor modified objects because the final time they had been examined by the Rubbish Collector (GC) in order that the GC can revisit them. For instance, if we have now:
 Beforehand, we’d emit a write barrier for every object modification however we solely want a single write barrier as a result of: 1) the mark might be set in o itself (and never within the inside objects), and a pair of) a rubbish assortment cannot have interacted with the thread between these units.
Beforehand, we’d emit a write barrier for every object modification however we solely want a single write barrier as a result of: 1) the mark might be set in o itself (and never within the inside objects), and a pair of) a rubbish assortment cannot have interacted with the thread between these units.If an instruction could set off a GC (for instance, Invokes and SuspendChecks), we would not have the ability to get rid of write boundaries. Within the following instance, we won’t assure a GC will not want to look at or modify the monitoring data between the modifications:
 Implementing this new move contributes to 0.8% code dimension discount.
Implementing this new move contributes to 0.8% code dimension discount.
Implicit droop checks
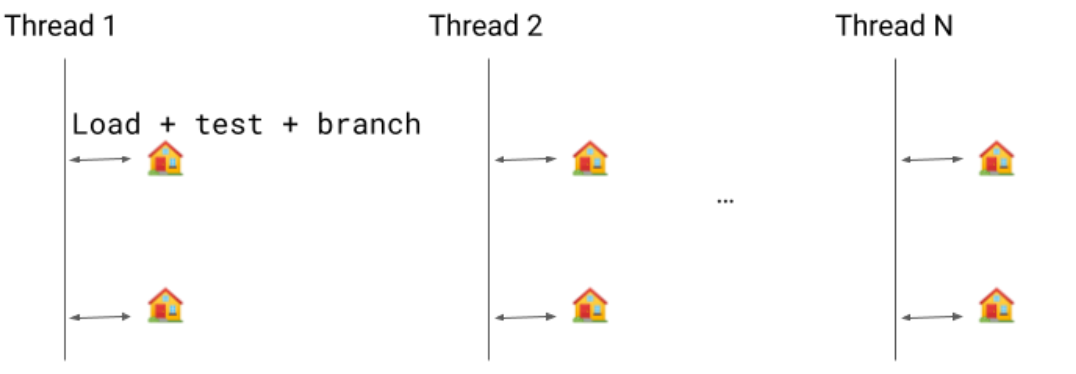
Let’s assume we have now a number of threads operating. Droop checks are safepoints (represented by the homes within the picture under) the place we will pause the thread execution. Safepoints are used for a lot of causes, a very powerful of them being Rubbish Assortment. When a safepoint name is issued, the threads should go right into a safepoint and are blocked till they’re launched.
The earlier implementation was an express boolean examine. We might load the worth, check it, and department into the safepoint if wanted.
Implicit droop checks is an optimization that eliminates the necessity for the check and department directions. As an alternative, we solely have one load: if the thread must droop, that load will entice and the sign handler will redirect the code to a droop examine handler as if the strategy made a name.
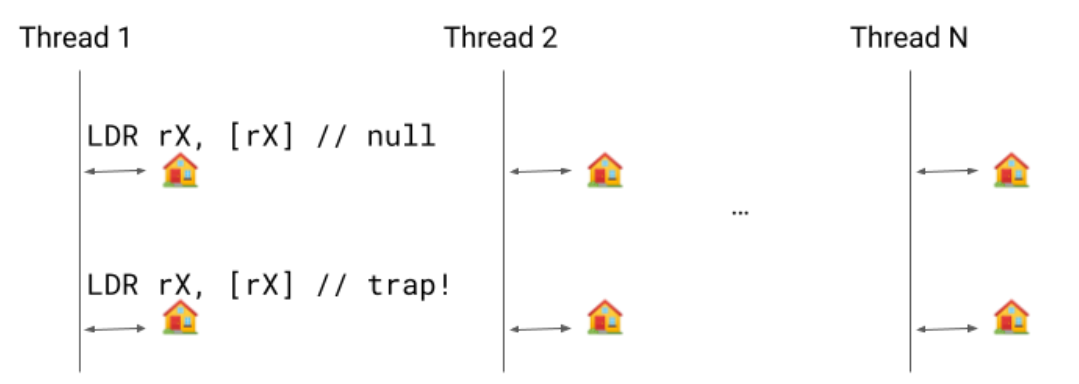
Going right into a bit extra element, a reserved register rX is pre-loaded with an tackle inside the thread the place we have now a pointer pointing to itself. So long as we needn’t do a droop examine, we hold that self-pointing pointer. When we have to do a droop examine, we clear the pointer and as soon as it turns into seen to the thread the primary LDR rX, [rX] will load null and the second will segfault.
The droop request is actually asking the thread to droop a while quickly, so the minor delay of getting to attend for the second load is okay.
This optimization reduces code dimension by 1.8%.
Coalescing returns
It’s common for compiled strategies to have an entry body. If they’ve it, these strategies should deconstruct it once they return, which is also referred to as an exit body. If a way has a number of return directions, it would generate a number of exit frames, one per return instruction.
By coalescing the return directions into one, we’re capable of have one return level and are capable of take away the additional exit frames. That is particularly helpful for swap circumstances with a number of return statements.

Coalescing returns reduces code dimension by 1%.
Different optimization enhancements
We improved a variety of our present optimization passes. For this weblog publish, we’ll group them up in the identical part, however they’re unbiased of one another. All of the optimizations within the following part contribute to a 5.7% code dimension discount.
Code Sinking
Code sinking is an optimization move that pushes down directions to unusual branches like paths that finish with a throw. That is achieved to scale back wasted cycles on directions which are doubtless not going for use.
We improved code sinking in graphs with attempt catches: we now permit sinking code so long as we do not sink it inside a special attempt than the one it began in (or inside any attempt if it wasn’t in a single to start with).

Within the first instance, we will sink the Object creation since it would solely be used within the if(flag) path and never the opposite and it’s inside the identical attempt. With this transformation, at runtime it would solely be run if flag is true. With out moving into an excessive amount of technical element, what we will sink is the precise object creation, however loading the Object class nonetheless stays earlier than the if. That is onerous to indicate with Kotlin code, as the identical Kotlin line turns into a number of directions on the ART compiler stage.
Within the second instance, we can’t sink the code as we’d be transferring an occasion creation (which can throw) inside one other attempt.
Code Sinking is usually a runtime efficiency optimization, however it will possibly assist cut back the register stress. By transferring directions nearer to their makes use of, we will use fewer registers in some circumstances. Utilizing fewer registers means fewer transfer directions, which finally ends up serving to code dimension.
Loop optimization
Loop optimization helps get rid of loops at compile time. Within the following instance, the loop in foo will multiply a by 10, 10 occasions. This is similar as multiplying by 100. We enabled loop optimization to work in graphs with attempt catches.

In foo, we will optimize the loop because the attempt catch is unrelated.
In bar or baz, nevertheless, we do not optimize it. It’s not trivial to know the trail the loop will take if we have now a attempt within the loop, or if the loop as an entire is inside a attempt.
Lifeless code elimination – Take away unneeded attempt blocks
We improved our useless code elimination part by implementing an optimization that removes attempt blocks that do not comprise throwing directions. We’re additionally capable of take away some catch blocks, so long as no dwell attempt blocks level to it.
Within the following instance, we inline bar into foo. After that, we all know that the division can’t throw. Later optimization passes can leverage this and enhance the code.
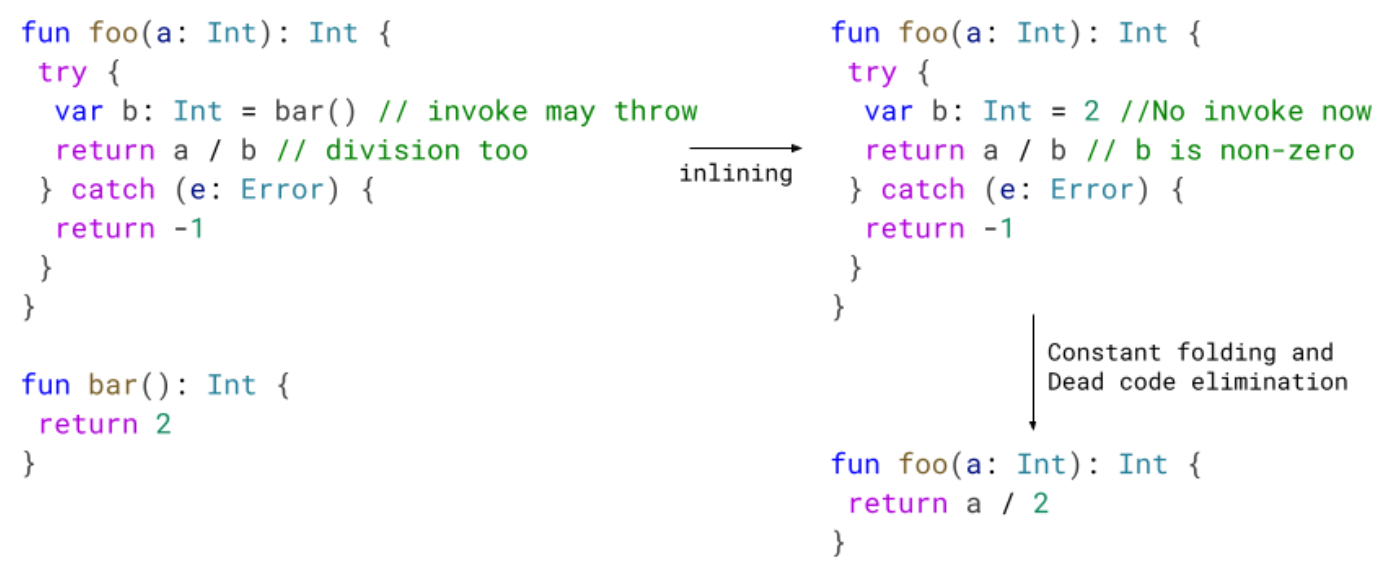
Simply eradicating the useless code from the attempt catch is sweet sufficient, however even higher is the truth that in some circumstances we permit different optimizations to happen. Should you recall, we do not do loop optimization when the loop has a attempt, or it is inside of 1. By eliminating this redundant attempt/catch, we will loop optimize producing smaller and sooner code.

Lifeless code elimination – SimplifyAlwaysThrows
In the course of the useless code elimination part, we have now an optimization we name SimplifyAlwaysThrows. If we detect that an invoke will all the time throw, we will safely discard no matter code we have now after that methodology name since it would by no means be executed.
We additionally up to date SimplifyAlwaysThrows to work in graphs with attempt catches, so long as the invoke itself shouldn’t be inside a attempt. Whether it is inside a attempt, we’d soar to a catch block, and it will get tougher to determine the precise path that might be executed.

We additionally improved:
- Detection when an invoke will all the time throw by taking a look at their parameters. On the left, we’ll mark divide(1, 0) as all the time throwing even when the generic methodology would not all the time throw.
- SimplifyAlwaysThrows to work on all invokes. Beforehand we had restrictions for instance do not do it for invokes resulting in an if, however we may take away the entire restrictions.

Load Retailer Elimination – Working with attempt catch blocks
Load retailer elimination (LSE) is an optimization move that removes redundant hundreds and shops.
We improved this move to work with attempt catches within the graph. In foo, we will see that we will do LSE usually if the shops/hundreds aren’t instantly interacting with the attempt. In bar, we will see an instance the place we both undergo the traditional path and do not throw, wherein case we return 1; or we throw, catch it and return 2. Because the worth is thought for each path, we will take away the redundant load.

Load Retailer Elimination – Working with launch/purchase operations
We improved our load retailer elimination move to work in graphs with launch/purchase operations. These are risky hundreds, shops, and monitor operations. To make clear, which means that we permit LSE to work in graphs which have these operations, however we do not take away stated operations.
Within the instance, i and j are common ints, and vi is a risky int. In foo, we will skip loading the values since there’s not a launch/purchase operation between the units and the hundreds. In bar, the risky operation occurs between them so we won’t get rid of the traditional hundreds. Notice that it would not matter that the risky load outcome shouldn’t be used—we can’t get rid of the purchase operation.

This optimization works equally with risky shops and monitor operations (that are synchronized blocks in Kotlin).
New inliner heuristic
Our inliner move has a variety of heuristics. Typically we determine to not inline a way as a result of it’s too massive, or generally to pressure inlining of a way as a result of it’s too small (for instance, empty strategies like Object initialization).
We applied a brand new inliner heuristic: Do not inline invokes resulting in a throw. If we all know we’re going to throw we’ll skip inlining these strategies, as throwing itself is expensive sufficient that inlining that code path shouldn’t be price it.
We had three households of strategies that we’re skipping to inline:
- Calculating and printing debug data earlier than a throw.
- Inlining the error constructor itself.
- Lastly blocks are duplicated in our optimizing compiler. Now we have one for the traditional case (i.e. the attempt would not throw), and one for the distinctive case. We do that as a result of within the distinctive case we have now to: catch, execute the lastly block, and rethrow. The strategies within the distinctive case will not be inlined, however the ones within the regular case will.

Fixed folding
Fixed folding is the optimization move that adjustments operations into constants if doable. We applied an optimization that propagates variables recognized to be fixed when utilized in if guards. Having extra constants within the graph permits us to carry out extra optimizations later.
In foo, we all know that a has the worth 2 within the if guard. We will propagate that data and deduce that b have to be 4. In an analogous vein, in bar we all know that cond have to be true within the if case and false within the else case (simplifying the graphs).

Placing all of it collectively
If we take note of all code dimension optimizations on this weblog publish we achieved a 9.3% code dimension discount!
To place issues into perspective, a median cellphone can have 500MB-1GB in optimized code (The precise quantity will be greater or decrease, relying on what number of apps you’ve put in, and which explicit apps you put in), so these optimizations save about 50-100MB per system. Since these optimizations attain 1B+ gadgets, we’re saving 47-95 petabytes globally!
Additional studying
In case you are within the code adjustments themselves, be at liberty to have a look. All of the enhancements talked about on this weblog publish are open supply. If you wish to assist Android customers worldwide, contemplate contributing to the Android Open Supply Challenge!
- Write barrier elimination: 1
- Implicit droop checks: 1
- Coalescing returns: 1
- Code sinking: 1, 2
- Loop optimization: 1
- Lifeless code elimination: 1, 2, 3, 4
- Load retailer elimination: 1, 2, 3, 4
- New inlining heuristic: 1
- Fixed folding: 1
Java is a trademark or registered trademark of Oracle and/or its associates