Retrieval Augmented Era (RAG) is an environment friendly mechanism to offer related knowledge as context in Gen AI purposes. Most RAG purposes sometimes use vector indexes to seek for related context from unstructured knowledge akin to documentation, wikis, and assist tickets. Yesterday, we introduced Databricks Vector Search Public Preview that helps with precisely that. Nonetheless, Gen AI response high quality will be enhanced by augmenting these text-based contexts with related and customized structured knowledge. Think about a Gen AI software on a retail web site the place prospects inquire, “The place’s my latest order?” This AI should perceive that the question is a couple of particular buy, then collect up-to-date cargo data for line objects, earlier than utilizing LLMs to generate a response. Growing these scalable purposes calls for substantial work, integrating applied sciences for dealing with each structured and unstructured knowledge with Gen AI capabilities.
We’re excited to announce the general public preview of Databricks Characteristic & Operate Serving, a low latency real-time service designed to serve structured knowledge from the Databricks Information Intelligence Platform. You possibly can immediately entry pre-computed ML options in addition to carry out real-time knowledge transformations by serving any Python operate from Unity Catalog. The retrieved knowledge can then be utilized in real-time rule engines, classical ML, and Gen AI purposes.
Utilizing Characteristic and Operate Serving (AWS)(Azure) for structured knowledge in coordination with Databricks Vector Search (AWS)(Azure) for unstructured knowledge considerably simplifies productionalization of Gen AI purposes. Customers can construct and deploy these purposes straight in Databricks and depend on present knowledge pipelines, governance, and different enterprise options. Databricks prospects throughout numerous industries are utilizing these applied sciences together with open supply frameworks to construct highly effective Gen AI purposes akin to those described within the desk beneath.
| Business | Use Case |
| Retail |
|
| Training |
|
| Monetary Providers |
|
| Journey and Hospitality |
|
| Healthcare and Life Sciences |
|
| Insurance coverage |
|
| Know-how and Manufacturing |
|
| Media and Leisure |
|
Serving structured knowledge to RAG purposes
To reveal how structured knowledge can assist improve the standard of a Gen AI software, we use the next instance for a journey planning chatbot. The instance reveals how consumer preferences (instance: “ocean view” or “household pleasant”) will be paired with unstructured data sourced about inns to seek for lodge matches. Sometimes lodge costs dynamically change based mostly on demand and seasonality. A worth calculator constructed into the Gen AI software ensures that the suggestions are inside the consumer’s funds. The Gen AI software that powers the bot makes use of Databricks Vector Search and Databricks Characteristic and Operate Serving as constructing blocks to serve the required customized consumer preferences and funds and lodge data utilizing LangChain’s brokers API.
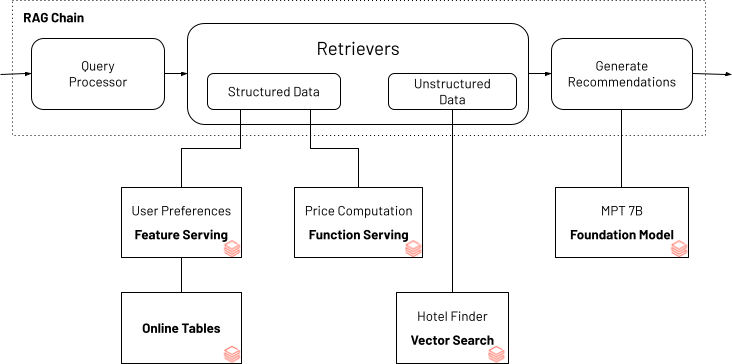
*Journey planning bot that accounts for consumer desire and funds
You’ll find the full pocket book for this RAG Chain software as depicted above. This software will be run domestically inside the pocket book or deployed as an endpoint accessible by a chatbot consumer interface.
Entry your knowledge and capabilities as real-time endpoints
With Characteristic Engineering in Unity Catalog you possibly can already use any desk with a major key to serve options for coaching and serving. Databricks Mannequin Serving helps utilizing Python capabilities to compute options on-demand. Constructed utilizing the identical expertise obtainable beneath the hood for Databricks Mannequin Serving, characteristic and performance endpoints can be utilized to entry any pre-computed characteristic or compute them on-demand. With a easy syntax you possibly can outline a characteristic spec operate in Unity Catalog that may encode the directed acyclic graph to compute and serve options as a REST endpoint.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
options = [
# Lookup columns `latitude` and `longitude` from `restaurants` table in UC using the input `restaurant_id` as key
FeatureLookup(
table_name="main.default.restaurants",
lookup_key="restaurant_id",
features=["latitude”, “longitude"]
),
# Calculate a brand new characteristic known as `distance` utilizing the restaurant and consumer's present location
FeatureFunction(
udf_name="essential.default.distance",
output_name="distance",
# bind the operate parameter with enter from different options or from request.
input_bindings={"user_latitude": "user_latitude", "user_longitude": "user_longitude",
"restaurant_latitude": "latitude", "restaurant_longitude": "longitude"},
),
]
fe = FeatureEngineeringClient()
# Create a characteristic spec with the options listed above.
# The FeatureSpec will be accessed in UC as a Operate.
fe.create_feature_spec(
title="essential.default.restaurant_features",
options=options,
)This characteristic spec operate will be served in real-time as a REST endpoint. All endpoints are accessible within the Serving left navigation tab together with options, operate, customized skilled fashions, and basis fashions. Provision the endpoint utilizing this API
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
title="restaurant-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="essential.default.restaurant_features",
workload_size="Small",
scale_to_zero_enabled=True
)
)
)The endpoint will also be created utilizing a UI workflow as proven beneath
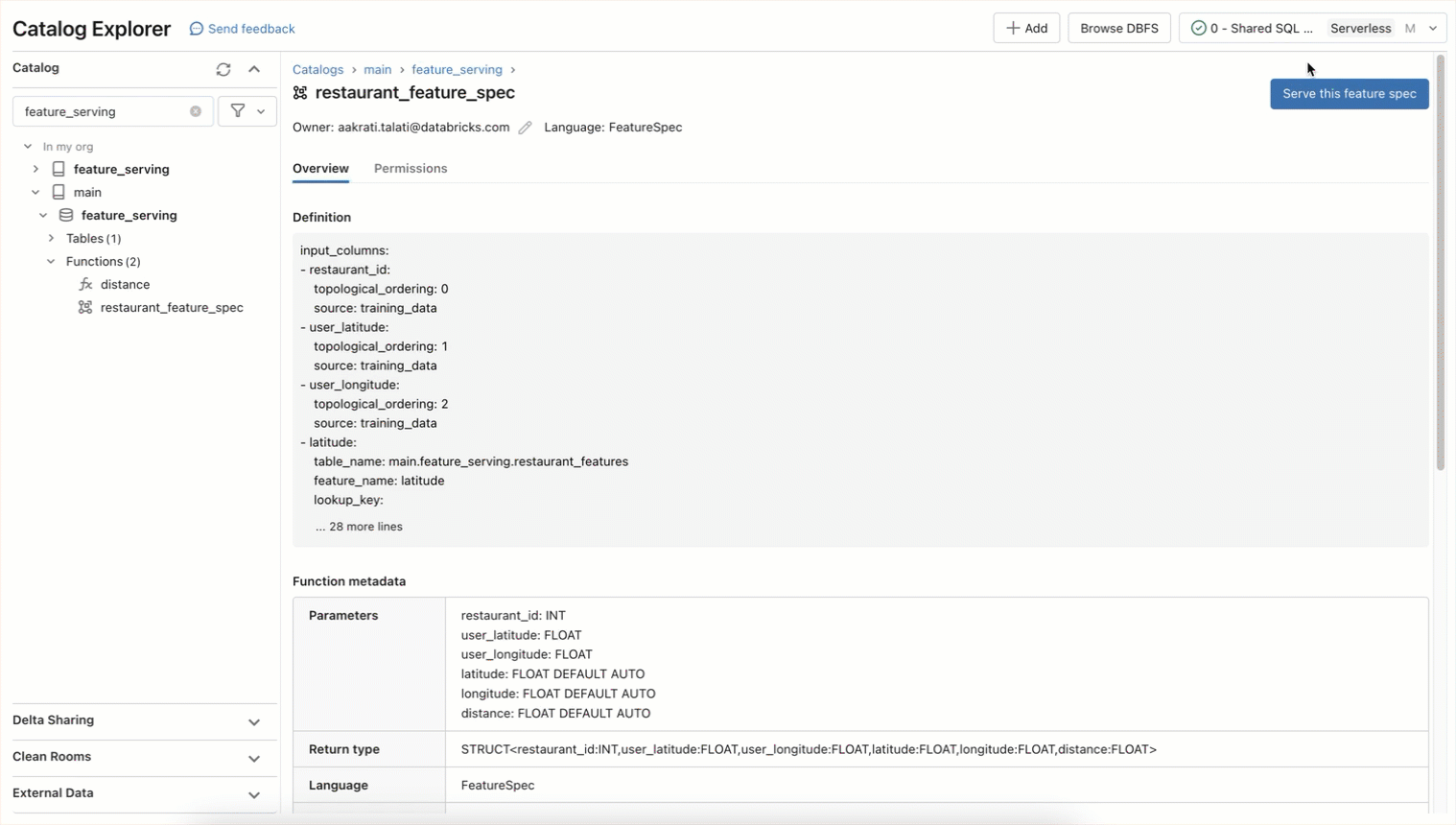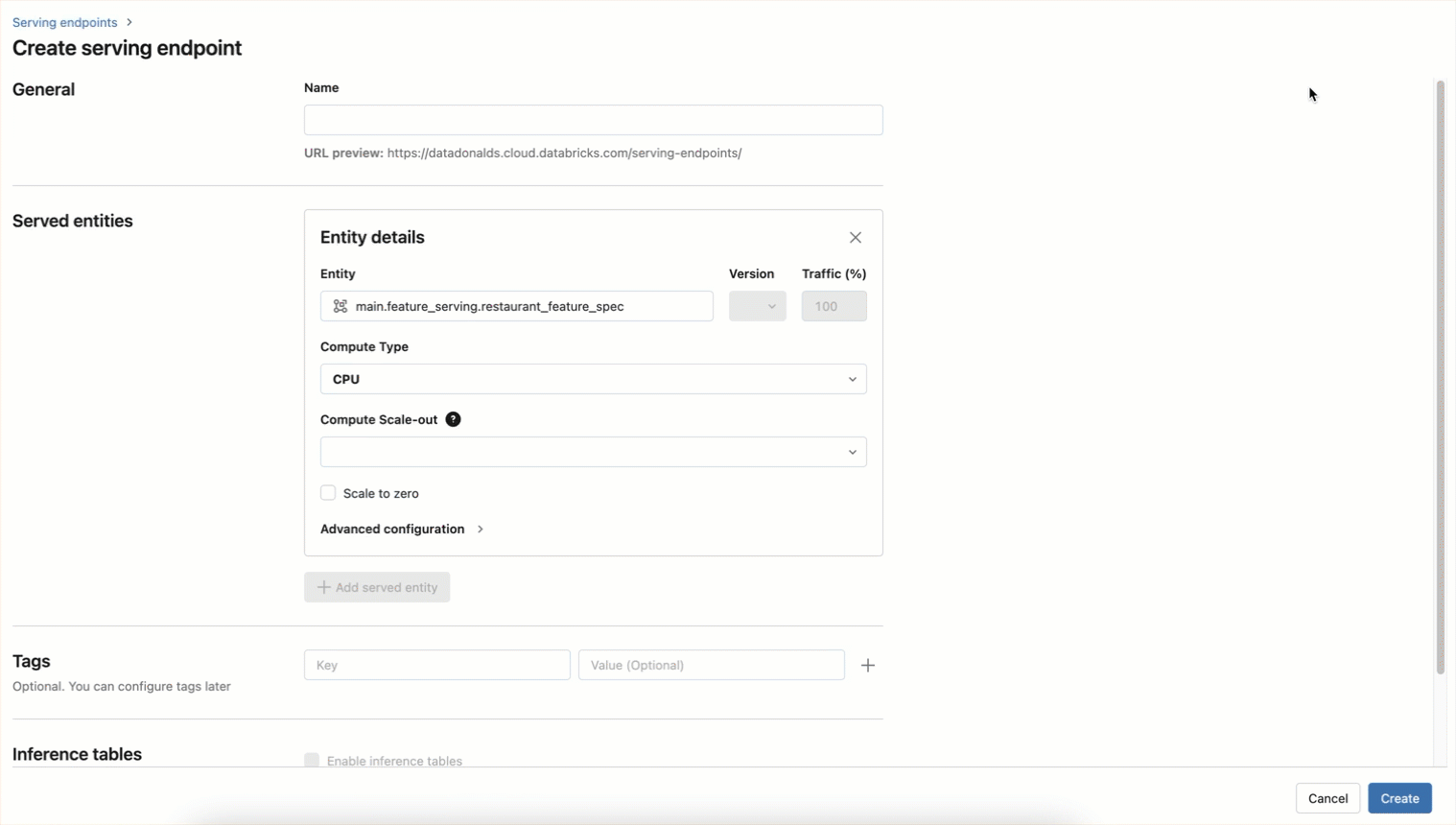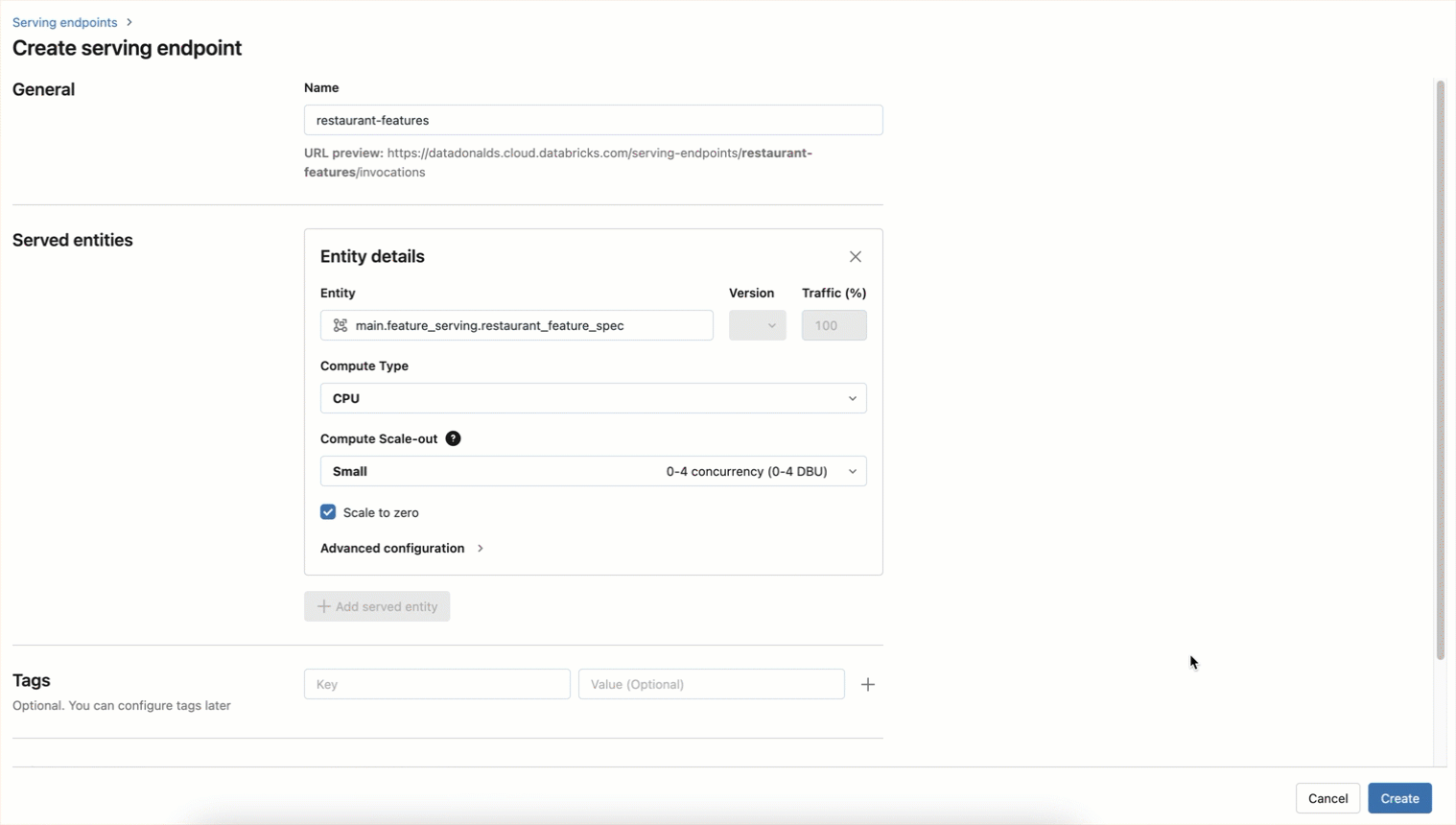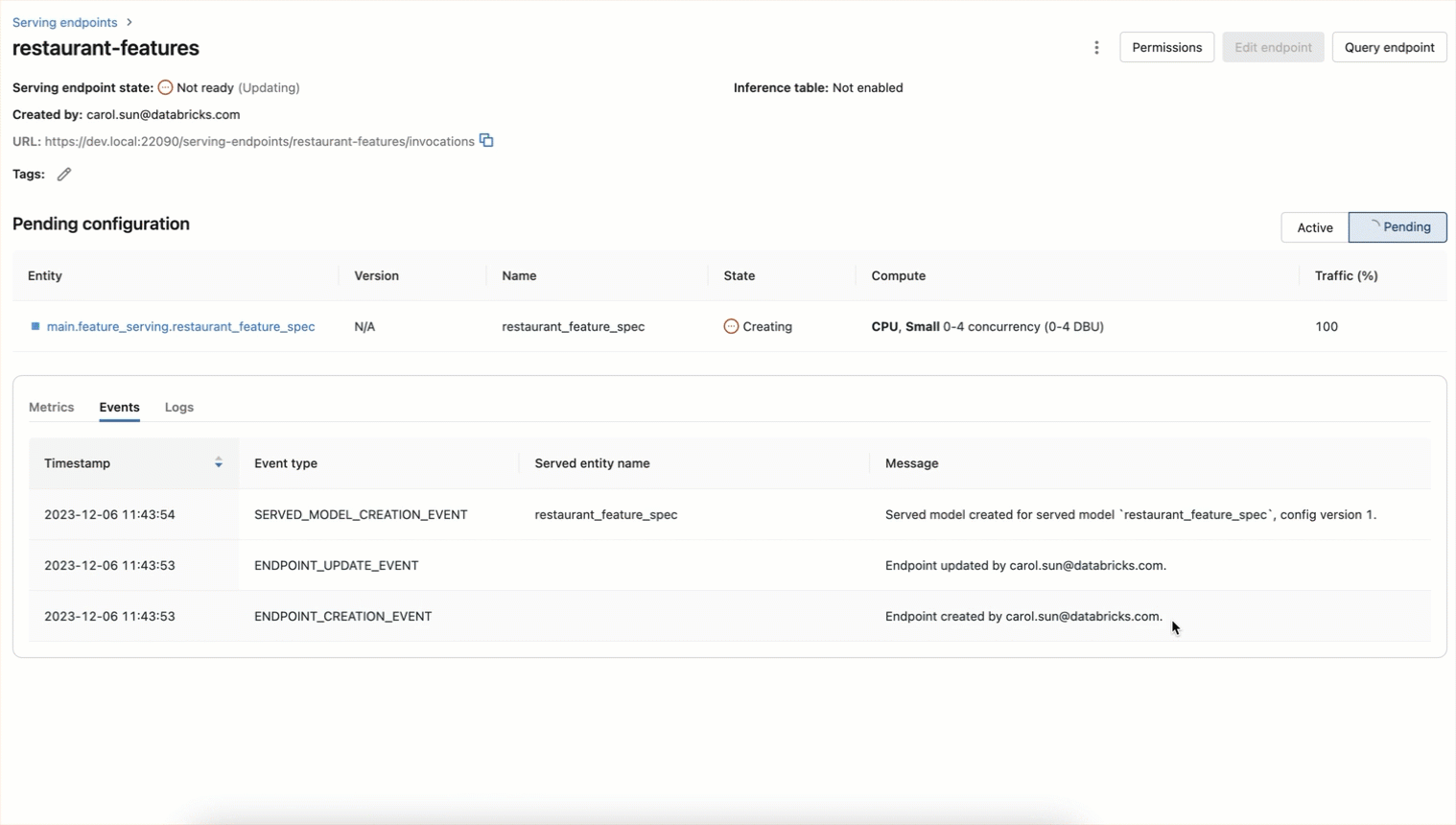
Now options be accessed in real-time by querying the endpoint:
curl
-u token:$DATABRICKS_TOKEN
-X POST
-H "Content material-Kind: software/json"
-d '{"dataframe_records": [{"user_latitude": 37.9711, "user_longitude": -122.3940, "restaurant_id": 5}]}'
https://<databricks-instance>/serving-endpoints/restaurant-features/invocationsTo serve structured knowledge to real-time AI purposes, precomputed knowledge must be deployed to operational databases. Customers can already use exterior on-line shops as a supply of precomputed features–for instance DynamoDB and Cosmos DB are generally used to serve options in Databricks Mannequin Serving. Databricks On-line Tables (AWS)(Azure) provides new performance that simplifies synchronization of precomputed options to a knowledge format optimized for low latency knowledge lookups. You possibly can sync any desk with a major key as a web-based desk and the system will arrange an automated pipeline to make sure knowledge freshness.
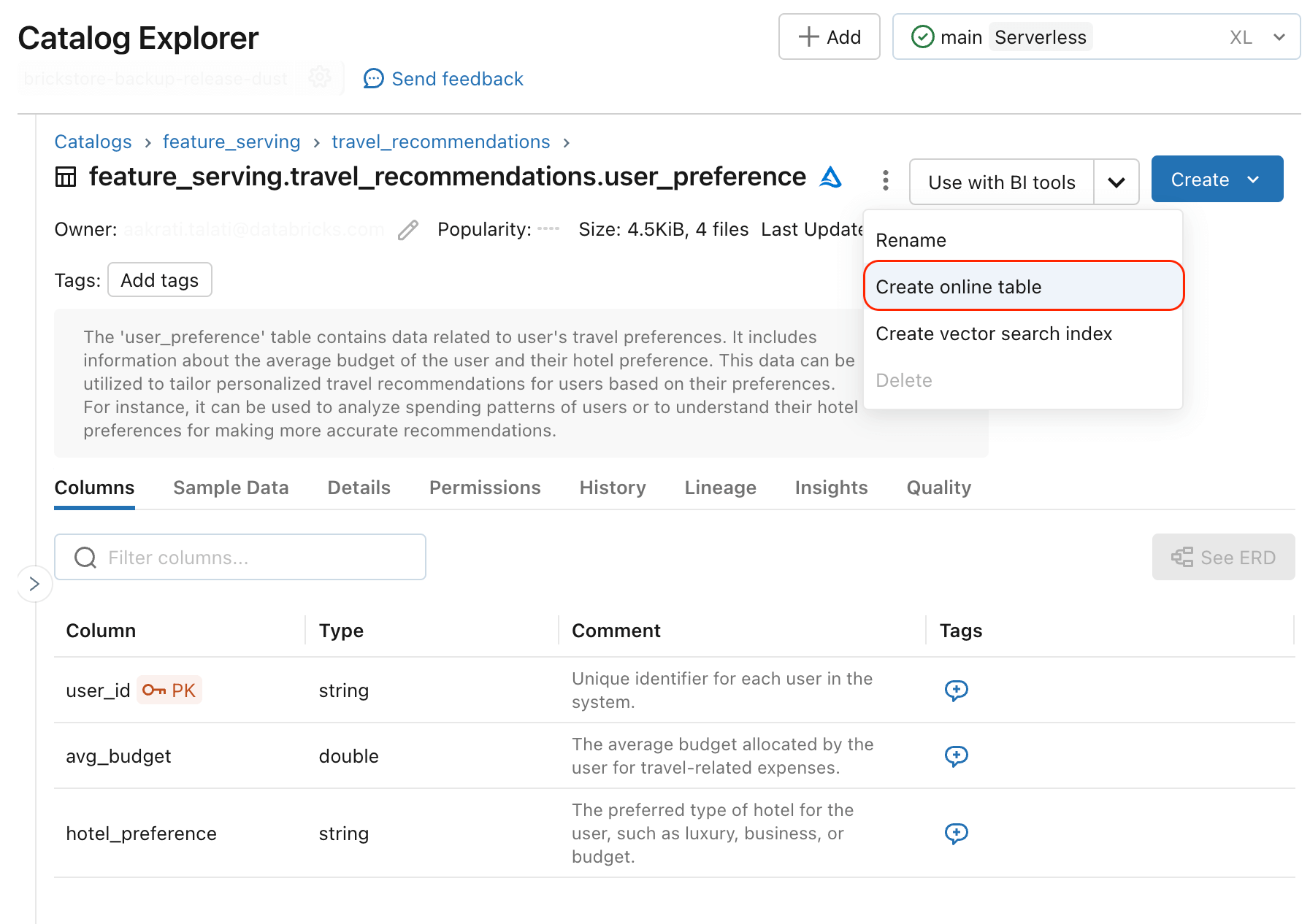
Any Unity Catalog desk with major keys can be utilized to serve options in Gen AI purposes utilizing Databricks On-line Tables.
Subsequent Steps
Use this pocket book instance illustrated above to customise your RAG purposes
Signal–up for a Databricks Generative AI Webinar obtainable on-demand
Characteristic and Operate Serving (AWS)(Azure) is obtainable in Public Preview. Confer with API documentation and extra examples.
Databricks On-line Tables (AWS)(Azure) can be found as Gated Public Preview. Use this type to join enablement.
Learn the abstract bulletins (making top quality RAG purposes) made earlier this week.
Have a use case you’d wish to share with Databricks? Contact us at [email protected]