The generative AI revolution embodied in instruments like ChatGPT, Midjourney, and plenty of others is at its core based mostly on a easy method: Take a really giant neural community, prepare it on an enormous dataset scraped from the Net, after which use it to satisfy a broad vary of consumer requests. Giant language fashions (LLMs) can reply questions, write code, and spout poetry, whereas image-generating techniques can create convincing cave work or up to date artwork.
So why haven’t these superb AI capabilities translated into the sorts of useful and broadly helpful robots we’ve seen in science fiction? The place are the robots that may clear off the desk, fold your laundry, and make you breakfast?
Sadly, the extremely profitable generative AI method—large fashions educated on numerous Web-sourced information—doesn’t simply carry over into robotics, as a result of the Web isn’t filled with robotic-interaction information in the identical approach that it’s filled with textual content and pictures. Robots want robotic information to be taught from, and this information is usually created slowly and tediously by researchers in laboratory environments for very particular duties. Regardless of large progress on robot-learning algorithms, with out plentiful information we nonetheless can’t allow robots to carry out real-world duties (like making breakfast) outdoors the lab. Essentially the most spectacular outcomes usually solely work in a single laboratory, on a single robotic, and infrequently contain solely a handful of behaviors.
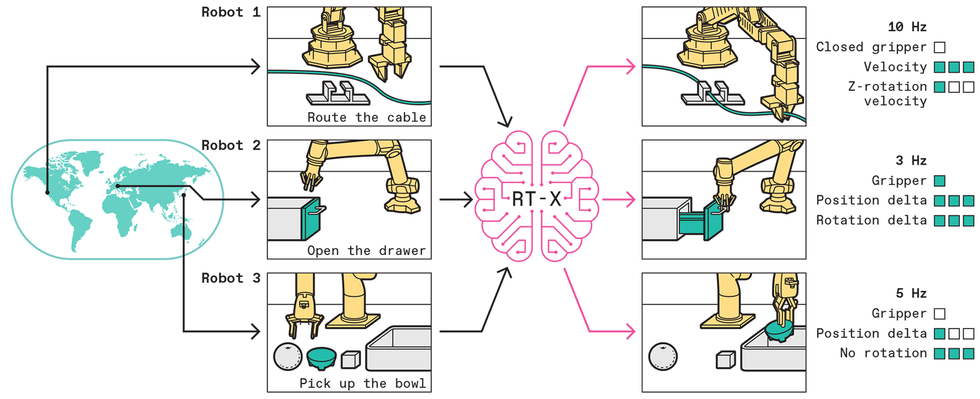
If the skills of every robotic are restricted by the effort and time it takes to manually train it to carry out a brand new job, what if we have been to pool collectively the experiences of many robots, so a brand new robotic might be taught from all of them without delay? We determined to offer it a strive. In 2023, our labs at Google and the College of California, Berkeley got here along with 32 different robotics laboratories in North America, Europe, and Asia to undertake the
RT-X challenge, with the purpose of assembling information, sources, and code to make general-purpose robots a actuality.
Here’s what we realized from the primary section of this effort.
The best way to create a generalist robotic
People are much better at this sort of studying. Our brains can, with just a little follow, deal with what are basically adjustments to our physique plan, which occurs after we choose up a device, trip a bicycle, or get in a automotive. That’s, our “embodiment” adjustments, however our brains adapt. RT-X is aiming for one thing comparable in robots: to allow a single deep neural community to manage many various sorts of robots, a functionality referred to as cross-embodiment. The query is whether or not a deep neural community educated on information from a sufficiently giant variety of completely different robots can be taught to “drive” all of them—even robots with very completely different appearances, bodily properties, and capabilities. In that case, this strategy might probably unlock the facility of enormous datasets for robotic studying.
The dimensions of this challenge could be very giant as a result of it must be. The RT-X dataset at present accommodates almost 1,000,000 robotic trials for 22 sorts of robots, together with most of the mostly used robotic arms in the marketplace. The robots on this dataset carry out an enormous vary of behaviors, together with choosing and inserting objects, meeting, and specialised duties like cable routing. In complete, there are about 500 completely different expertise and interactions with 1000’s of various objects. It’s the biggest open-source dataset of actual robotic actions in existence.
Surprisingly, we discovered that our multirobot information could possibly be used with comparatively easy machine-learning strategies, supplied that we observe the recipe of utilizing giant neural-network fashions with giant datasets. Leveraging the identical sorts of fashions utilized in present LLMs like ChatGPT, we have been in a position to prepare robot-control algorithms that don’t require any particular options for cross-embodiment. Very like an individual can drive a automotive or trip a bicycle utilizing the identical mind, a mannequin educated on the RT-X dataset can merely acknowledge what sort of robotic it’s controlling from what it sees within the robotic’s personal digicam observations. If the robotic’s digicam sees a
UR10 industrial arm, the mannequin sends instructions acceptable to a UR10. If the mannequin as a substitute sees a low-cost WidowX hobbyist arm, the mannequin strikes it accordingly.
To check the capabilities of our mannequin, 5 of the laboratories concerned within the RT-X collaboration every examined it in a head-to-head comparability towards the very best management system they’d developed independently for their very own robotic. Every lab’s take a look at concerned the duties it was utilizing for its personal analysis, which included issues like choosing up and transferring objects, opening doorways, and routing cables via clips. Remarkably, the one unified mannequin supplied improved efficiency over every laboratory’s personal finest methodology, succeeding on the duties about 50 p.c extra typically on common.
Whereas this end result may appear stunning, we discovered that the RT-X controller might leverage the various experiences of different robots to enhance robustness in several settings. Even throughout the similar laboratory, each time a robotic makes an attempt a job, it finds itself in a barely completely different scenario, and so drawing on the experiences of different robots in different conditions helped the RT-X controller with pure variability and edge instances. Listed here are just a few examples of the vary of those duties:
Constructing robots that may cause
Inspired by our success with combining information from many robotic sorts, we subsequent sought to analyze how such information could be integrated right into a system with extra in-depth reasoning capabilities. Complicated semantic reasoning is difficult to be taught from robotic information alone. Whereas the robotic information can present a spread of
bodily capabilities, extra complicated duties like “Transfer apple between can and orange” additionally require understanding the semantic relationships between objects in a picture, primary widespread sense, and different symbolic information that’s not immediately associated to the robotic’s bodily capabilities.
So we determined so as to add one other large supply of knowledge to the combo: Web-scale picture and textual content information. We used an current giant vision-language mannequin that’s already proficient at many duties that require some understanding of the connection between pure language and pictures. The mannequin is much like those accessible to the general public reminiscent of ChatGPT or
Bard. These fashions are educated to output textual content in response to prompts containing photos, permitting them to unravel issues reminiscent of visible question-answering, captioning, and different open-ended visible understanding duties. We found that such fashions could be tailored to robotic management just by coaching them to additionally output robotic actions in response to prompts framed as robotic instructions (reminiscent of “Put the banana on the plate”). We utilized this strategy to the robotics information from the RT-X collaboration.
 The RT-X mannequin makes use of photos or textual content descriptions of particular robotic arms doing completely different duties to output a sequence of discrete actions that may permit any robotic arm to do these duties. By accumulating information from many robots doing many duties from robotics labs all over the world, we’re constructing an open-source dataset that can be utilized to show robots to be usually helpful.Chris Philpot
The RT-X mannequin makes use of photos or textual content descriptions of particular robotic arms doing completely different duties to output a sequence of discrete actions that may permit any robotic arm to do these duties. By accumulating information from many robots doing many duties from robotics labs all over the world, we’re constructing an open-source dataset that can be utilized to show robots to be usually helpful.Chris Philpot
To guage the mix of Web-acquired smarts and multirobot information, we examined our RT-X mannequin with Google’s cellular manipulator robotic. We gave it our hardest generalization benchmark checks. The robotic needed to acknowledge objects and efficiently manipulate them, and it additionally had to answer complicated textual content instructions by making logical inferences that required integrating data from each textual content and pictures. The latter is without doubt one of the issues that make people such good generalists. May we give our robots at the least a touch of such capabilities?
Even with out particular coaching, this Google analysis robotic is ready to observe the instruction “transfer apple between can and orange.” This functionality is enabled by RT-X, a big robotic manipulation dataset and step one in the direction of a common robotic mind.
We carried out two units of evaluations. As a baseline, we used a mannequin that excluded the entire generalized multirobot RT-X information that didn’t contain Google’s robotic. Google’s robot-specific dataset is in actual fact the biggest a part of the RT-X dataset, with over 100,000 demonstrations, so the query of whether or not all the opposite multirobot information would truly assist on this case was very a lot open. Then we tried once more with all that multirobot information included.
In one of the tough analysis situations, the Google robotic wanted to perform a job that concerned reasoning about spatial relations (“Transfer apple between can and orange”); in one other job it needed to clear up rudimentary math issues (“Place an object on prime of a paper with the answer to ‘2+3’”). These challenges have been meant to check the essential capabilities of reasoning and drawing conclusions.
On this case, the reasoning capabilities (such because the which means of “between” and “on prime of”) got here from the Net-scale information included within the coaching of the vision-language mannequin, whereas the power to floor the reasoning outputs in robotic behaviors—instructions that really moved the robotic arm in the precise path—got here from coaching on cross-embodiment robotic information from RT-X. Some examples of evaluations the place we requested the robots to carry out duties not included of their coaching information are proven under.Whereas these duties are rudimentary for people, they current a serious problem for general-purpose robots. With out robotic demonstration information that clearly illustrates ideas like “between,” “close to,” and “on prime of,” even a system educated on information from many various robots wouldn’t have the ability to determine what these instructions imply. By integrating Net-scale information from the vision-language mannequin, our full system was in a position to clear up such duties, deriving the semantic ideas (on this case, spatial relations) from Web-scale coaching, and the bodily behaviors (choosing up and transferring objects) from multirobot RT-X information. To our shock, we discovered that the inclusion of the multirobot information improved the Google robotic’s capability to generalize to such duties by an element of three. This end result means that not solely was the multirobot RT-X information helpful for buying a wide range of bodily expertise, it might additionally assist to raised join such expertise to the semantic and symbolic information in vision-language fashions. These connections give the robotic a level of widespread sense, which might in the future allow robots to know the which means of complicated and nuanced consumer instructions like “Convey me my breakfast” whereas finishing up the actions to make it occur.
The subsequent steps for RT-X
The RT-X challenge exhibits what is feasible when the robot-learning neighborhood acts collectively. Due to this cross-institutional effort, we have been in a position to put collectively a various robotic dataset and perform complete multirobot evaluations that wouldn’t be attainable at any single establishment. For the reason that robotics neighborhood can’t depend on scraping the Web for coaching information, we have to create that information ourselves. We hope that extra researchers will contribute their information to the
RT-X database and be a part of this collaborative effort. We additionally hope to supply instruments, fashions, and infrastructure to assist cross-embodiment analysis. We plan to transcend sharing information throughout labs, and we hope that RT-X will develop right into a collaborative effort to develop information requirements, reusable fashions, and new strategies and algorithms.
Our early outcomes trace at how giant cross-embodiment robotics fashions might rework the sector. A lot as giant language fashions have mastered a variety of language-based duties, sooner or later we would use the identical basis mannequin as the idea for a lot of real-world robotic duties. Maybe new robotic expertise could possibly be enabled by fine-tuning and even prompting a pretrained basis mannequin. In an identical solution to how one can immediate ChatGPT to inform a narrative with out first coaching it on that exact story, you might ask a robotic to write down “Completely happy Birthday” on a cake with out having to inform it use a piping bag or what handwritten textual content appears like. After all, way more analysis is required for these fashions to tackle that form of common functionality, as our experiments have targeted on single arms with two-finger grippers doing easy manipulation duties.
As extra labs interact in cross-embodiment analysis, we hope to additional push the frontier on what is feasible with a single neural community that may management many robots. These advances may embody including various simulated information from generated environments, dealing with robots with completely different numbers of arms or fingers, utilizing completely different sensor suites (reminiscent of depth cameras and tactile sensing), and even combining manipulation and locomotion behaviors. RT-X has opened the door for such work, however probably the most thrilling technical developments are nonetheless forward.
That is only the start. We hope that with this primary step, we are able to collectively create the way forward for robotics: the place common robotic brains can energy any robotic, benefiting from information shared by all robots all over the world.
From Your Website Articles
Associated Articles Across the Net