
Iceberg is an rising open-table format designed for giant analytic workloads. The Apache Iceberg mission continues creating an implementation of Iceberg specification within the type of Java Library. A number of compute engines resembling Impala, Hive, Spark, and Trino have supported querying information in Iceberg desk format by adopting this Java Library offered by the Apache Iceberg mission.
Completely different question engines resembling Impala, Hive, and Spark can instantly profit from utilizing Apache Iceberg Java Library. A spread of Iceberg desk evaluation resembling itemizing desk’s information file, deciding on desk snapshot, partition filtering, and predicate filtering might be delegated by Iceberg Java API as a substitute, obviating the necessity for every question engine to implement it themself. Nonetheless, Iceberg Java API calls aren’t all the time low cost.
On this weblog, we are going to focus on efficiency enchancment that Cloudera has contributed to the Apache Iceberg mission with regard to Iceberg metadata reads, and we’ll showcase the efficiency profit utilizing Apache Impala because the question engine. Nonetheless, different question engines resembling Hive and Spark may also profit from this Iceberg enchancment as effectively.
Repeated metadata reads downside in Impala + Iceberg
Apache Impala is an open supply, distributed, massively parallel SQL question engine. There are two parts of Apache Impala: again finish executor and entrance finish planner. The Impala again finish executor is written in C++ to supply quick question execution. Alternatively, Impala entrance finish planner is written in Java and is answerable for analyzing SQL queries from customers and planning the question execution. Throughout question planning, Impala entrance finish will analyze desk metadata resembling partition info, information recordsdata, and statistics to provide you with an optimized execution plan. For the reason that Impala entrance finish is written in Java, Impala can immediately analyze many facets of the Iceberg desk metadata by the Java Library offered by Apache Iceberg mission.
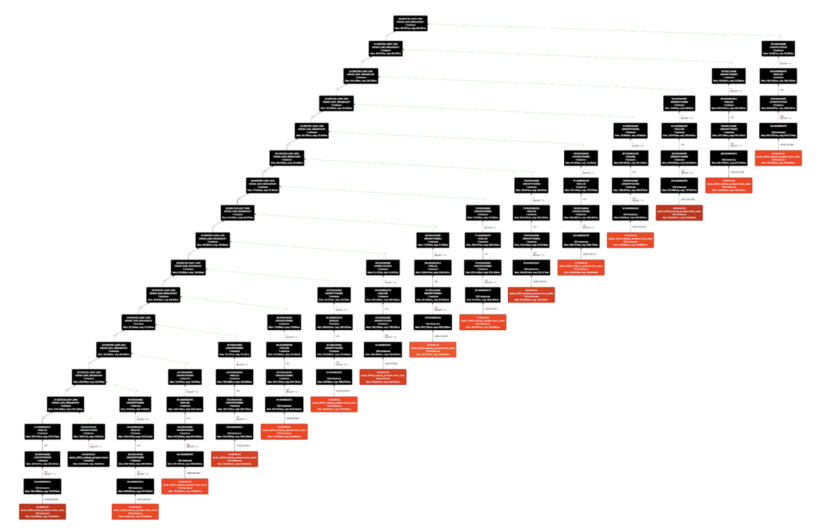
Determine 1. store_sales desk scanned 15 occasions with various filter predicates in TPC-DS Q9
In Hive desk format, the desk metadata resembling partition info and statistics are saved in Hive Metastore (HMS). Impala can entry Hive desk metadata quick as a result of HMS is backed by RDBMS, resembling mysql or postgresql. Impala additionally caches desk metadata in CatalogD and Coordinator’s native catalog, making desk metadata evaluation even quicker if the focused desk metadata and recordsdata had been beforehand accessed. This caching is essential for Impala since it might analyze the identical desk a number of occasions throughout concurrent question planning and likewise inside single question planning. Determine 1 reveals a TPC-DS Q9 plan the place one widespread desk, store_sales, is analyzed 15 occasions to plan 15 separate desk scan fragments.
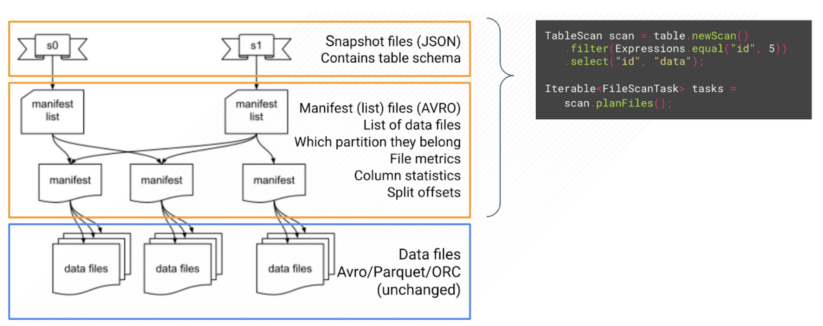
Determine 2. Iceberg desk metadata reads by Iceberg Java API
In distinction, Iceberg desk format shops its metadata as a set of recordsdata within the file system, subsequent to the info recordsdata. Determine 2 illustrates the three sorts of metadata recordsdata: snapshot recordsdata, manifest listing, and manifest recordsdata. The info recordsdata and metadata recordsdata in Iceberg format are immutable. New DDL/DML operation over the Iceberg desk will create a brand new set of recordsdata as a substitute of rewriting or changing prior recordsdata. Each desk metadata question by Iceberg Java API requires studying a subset of those metadata recordsdata. Subsequently, every of them additionally incurs a further storage latency and community latency overhead, even when a few of them are analyzing the identical desk. This downside is described in IMPALA-11171.
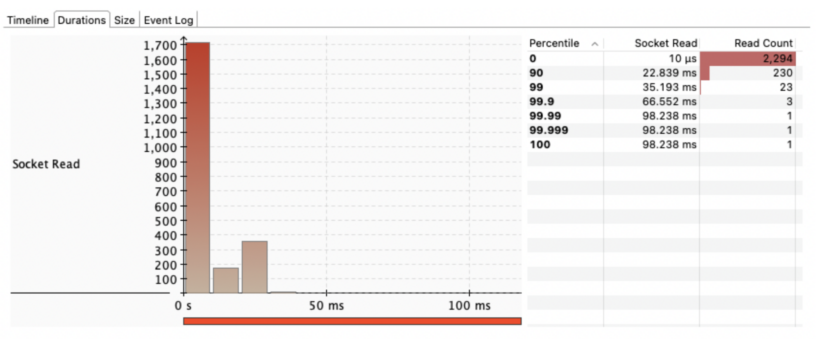
Determine 3. A number of socket learn actions throughout TPC-DS Q9 planning over Iceberg desk on S3.
Iceberg manifest file cache design
Impala entrance finish should be cautious in utilizing Iceberg Java API whereas nonetheless sustaining quick question planning efficiency. Decreasing the a number of distant reads of Iceberg metadata recordsdata requires implementing related caching methods as Impala does for Hive desk format, both in Impala entrance finish aspect or embedded in Iceberg Java Library. Finally, we decide to do the latter so we are able to contribute one thing that’s helpful for the entire group and all the compute engines can profit from it. Additionally it is essential to implement such a caching mechanism as much less intrusive as doable.
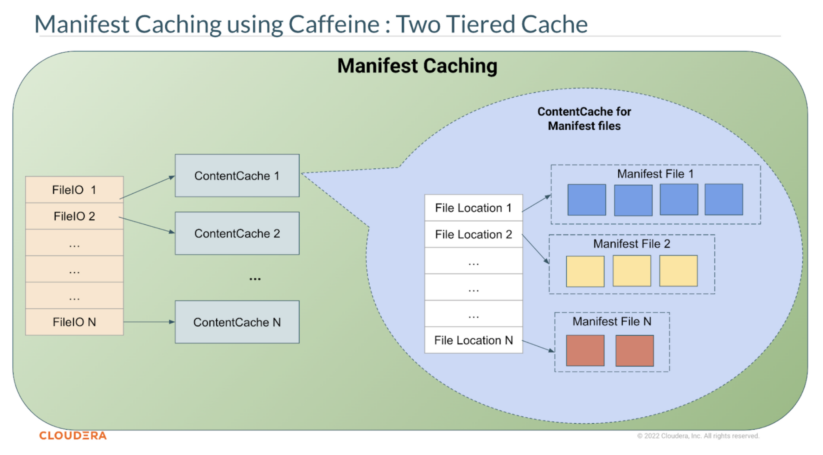
Determine 4. Iceberg manifest caching design.
We filed pull request 4518 within the Apache Iceberg mission to implement this caching mechanism. The concept is to cache the binary content material of manifest recordsdata (the bottom of Iceberg metadata recordsdata hierarchy) in reminiscence, and let Iceberg Java Library learn from the reminiscence if it exists as a substitute of studying once more from the file system. That is made doable by the truth that Iceberg metadata recordsdata, together with the manifest recordsdata, are immutable. If an Iceberg desk evolves, new manifest recordsdata can be written as a substitute of modifying the previous manifest recordsdata. Thus, Iceberg Java Library will nonetheless learn any new further manifest recordsdata that it wants from the file system, populating manifest cache with new content material and expiring the previous ones within the course of.
Determine 4 illustrates the two-tiered design of the Iceberg manifest cache. The primary tier is the FileIO degree cache, mapping a FileIO into its personal ContentCache. FileIO itself is the first interface between the core Iceberg library and underlying storage. Any file learn and write operation by the Iceberg library will undergo the FileIO interface. By default, this primary tier cache has a most of eight FileIO that may concurrently have ContentCache entries in reminiscence. This quantity might be elevated by Java system properties iceberg.io.manifest.cache.fileio-max.
The second tier cache is the ContentCache object, which is a mapping of file location path to the binary file content material of that file path. The binary file content material is saved in reminiscence as a ByteBuffer of 4MB chunks. Each of the tiers are applied utilizing the Caffeine library, a high-performance caching library that’s already in use by Iceberg Java Library, with a mixture of weak keys and smooth values. This mix permits automated cache entries elimination on the occasion of JVM reminiscence strain and rubbish assortment of the FileIO. This cache is applied within the core Iceberg Java Library (ManifestFiles.java), making it obtainable for rapid use by totally different FileIO implementations with out altering their code.
Impala Coordinator and CatalogD can do a quick file itemizing and information file pruning over an Iceberg desk utilizing this Iceberg manifest cache. Observe that Iceberg manifest caching doesn’t eradicate the function of CatalogD and Coordinator’s native catalog. Some desk metadata resembling desk schema, file descriptors, and block places (for HDFS backed tables) are nonetheless cached inside CatalogD. Collectively, CatalogD cache and Iceberg manifest cache assist obtain quick question planning in Impala.
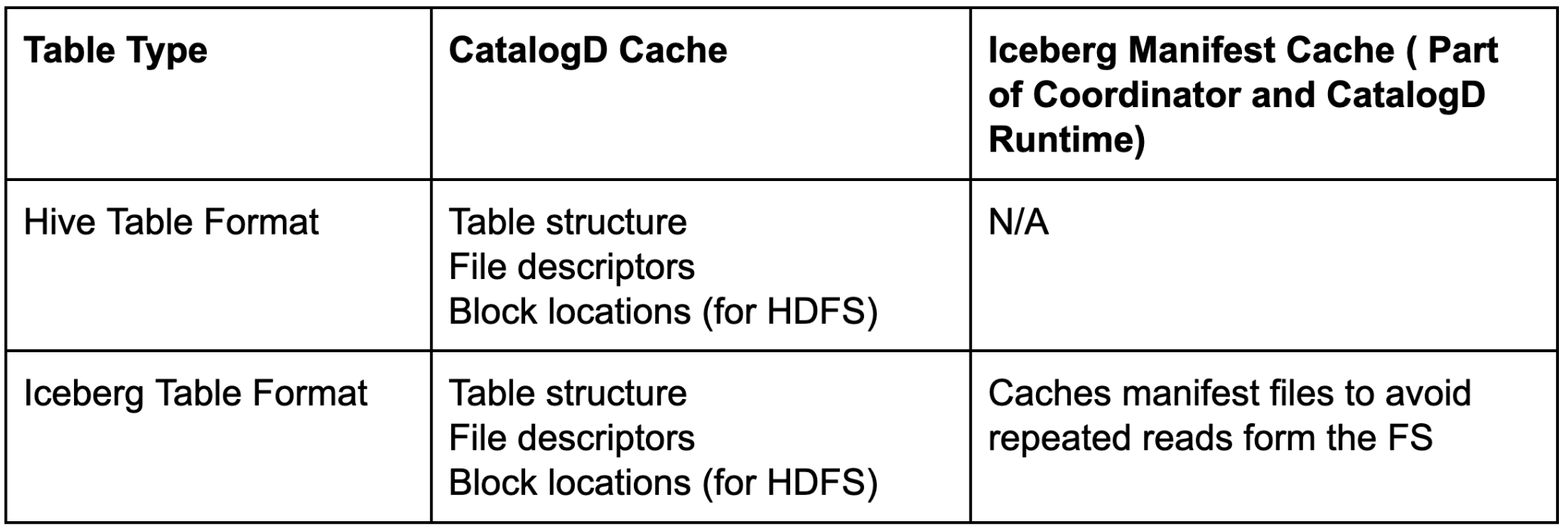
Desk 1. CatalogD and Iceberg Manifest Cache function throughout desk codecs.
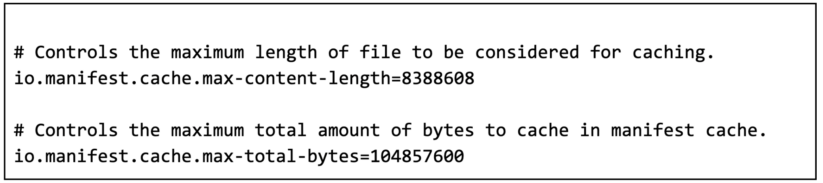
Particular person per-FileIO ContentCache might be tuned by their respective Iceberg Catalog properties. The outline and default values for every properties are following:

Efficiency enchancment in Impala
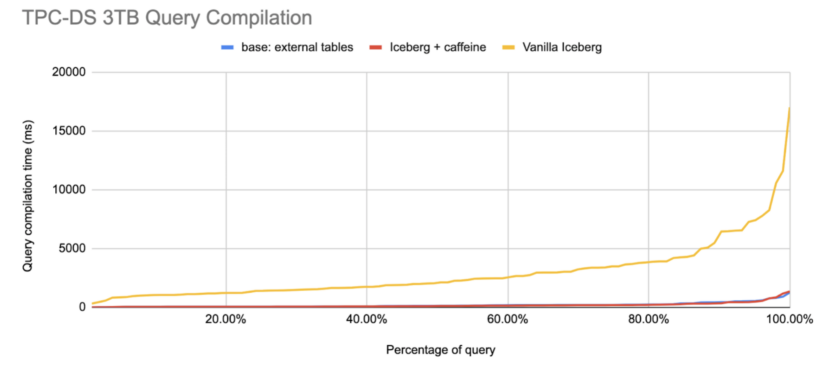
Determine 5. Inverse CDF of Impala question compilation time over TPC-DS queries 3TB scale
Impala and different question engines can leverage the manifest caching characteristic ranging from Apache Iceberg model 1.1.0. Determine 5 reveals the advance in compilation time by Impala entrance finish. The x-axis represents the share of queries in TPC-DS workload, and the y-axis represents the question compilation time in milliseconds. In comparison with Iceberg with out manifest caching (Vanilla Iceberg), enabling Iceberg manifest caching can enhance question compilation 12 occasions quicker (Iceberg + caffeine), virtually matching the efficiency over the Hive exterior desk. One caveat is that, in Impala, the io.manifest.cache.expiration-interval-ms config is elevated increased to 1 hour in Coordinator. That is helpful for Impala as a result of for the default Hive catalog, Impala entrance finish maintains a singleton of Iceberg’s HiveCatalog that’s lengthy lived. Setting a protracted expiration is ok since Iceberg recordsdata are immutable, as defined within the design part above. A protracted expiration time may even permit cache entries to reside longer and be utilized for a number of question planning concentrating on the identical tables.
Impala at the moment reads its default Iceberg catalog properties from core-site.xml. To allow Iceberg manifest caching with a one hour expiration interval, set the next configuration in Coordinator and CatalogD service core-site.xml:
 Abstract
Abstract
Apache Iceberg is an rising open-table format designed for giant analytic workloads. The Apache Iceberg mission continues creating the Iceberg Java Library, which has been adopted by many question engines resembling Impala, Hive, and Spark. Cloudera has contributed the Iceberg manifest caching characteristic to Apache Iceberg to cut back repeated manifest file reads issues. We showcase the good thing about Iceberg manifest caching through the use of Apache Impala because the question engine, and present that Impala is ready to acquire as much as 12 occasions speedup in question compilation time on Iceberg tables with Iceberg manifest caching enabled.
To be taught extra:
- For extra on Iceberg manifest caching configuration in In Cloudera Information Warehouse (CDW), please seek advice from https://docs.cloudera.com/cdw-runtime/cloud/iceberg-how-to/subjects/iceberg-manifest-caching.html.
- Watch our webinar Supercharge Your Analytics with Open Information Lakehouse Powered by Apache Iceberg. It features a reside demo recording of Iceberg capabilities.
Strive Cloudera Information Warehouse (CDW), Cloudera Information Engineering (CDE), and Cloudera Machine Studying (CML) by signing up for a 60 day trial, or check drive CDP. If you have an interest in chatting about Apache Iceberg in CDP, let your account group know.