
Introduction
For greater than a decade now, the Hive desk format has been a ubiquitous presence within the massive information ecosystem, managing petabytes of information with outstanding effectivity and scale. However as the info volumes, information selection, and information utilization grows, customers face many challenges when utilizing Hive tables due to its antiquated directory-based desk format. Among the widespread points embrace constrained schema evolution, static partitioning of information, and lengthy planning time due to S3 listing listings.
Apache Iceberg is a contemporary desk format that not solely addresses these issues but additionally provides further options like time journey, partition evolution, desk versioning, schema evolution, robust consistency ensures, object retailer file format (the flexibility to distribute recordsdata current in a single logical partition throughout many prefixes to keep away from object retailer throttling), hidden partitioning (customers don’t need to be intimately conscious of partitioning), and extra. Due to this fact, Apache Iceberg desk format is poised to interchange the normal Hive desk format within the coming years.
Nonetheless, as there are already 25 million terabytes of information saved within the Hive desk format, migrating present tables within the Hive desk format into the Iceberg desk format is critical for efficiency and price. Relying on the dimensions and utilization patterns of the info, a number of completely different methods might be pursued to realize a profitable migration. On this weblog, I’ll describe a couple of methods one may undertake for varied use instances. Whereas these directions are carried out for Cloudera Information Platform (CDP), Cloudera Information Engineering, and Cloudera Information Warehouse, one can extrapolate them simply to different companies and different use instances as nicely.
There are few situations that one would possibly encounter. A number of of those use instances would possibly suit your workload and also you would possibly have the ability to combine and match the potential options supplied to fit your wants. They’re meant to be a basic information. In all of the use instances we try emigrate a desk named “occasions.”
Method 1
You may have the flexibility to cease your shoppers from writing to the respective Hive desk through the period of your migration. That is supreme as a result of this would possibly imply that you just don’t have to change any of your consumer code. Generally that is the one selection out there if in case you have lots of of shoppers that may probably write to a desk. It might be a lot simpler to easily cease all these jobs slightly than permitting them to proceed through the migration course of.
In-place desk migration
Answer 1A: utilizing Spark’s migrate process
Iceberg’s Spark extensions present an in-built process known as “migrate” emigrate an present desk from Hive desk format to Iceberg desk format. Additionally they present a “snapshot” process that creates an Iceberg desk with a special identify with the identical underlying information. You possibly can first create a snapshot desk, run sanity checks on the snapshot desk, and be certain that every little thing is so as.
 As soon as you’re happy you’ll be able to drop the snapshot desk and proceed with the migration utilizing the migrate process. Remember the fact that the migrate process creates a backup desk named “events__BACKUP__.” As of this writing, the “__BACKUP__” suffix is hardcoded. There may be an effort underway to let the consumer move a customized backup suffix sooner or later.
As soon as you’re happy you’ll be able to drop the snapshot desk and proceed with the migration utilizing the migrate process. Remember the fact that the migrate process creates a backup desk named “events__BACKUP__.” As of this writing, the “__BACKUP__” suffix is hardcoded. There may be an effort underway to let the consumer move a customized backup suffix sooner or later.

Remember the fact that each the migrate and snapshot procedures don’t modify the underlying information: they carry out in-place migration. They merely learn the underlying information (not even full learn, they only learn the parquet headers) and create corresponding Iceberg metadata recordsdata. Because the underlying information recordsdata usually are not modified, chances are you’ll not have the ability to take full benefit of the advantages supplied by Iceberg straight away. You possibly can optimize your desk now or at a later stage utilizing the “rewrite_data_files” process. This might be mentioned in a later weblog. Now let’s talk about the professionals and cons of this method.
PROS:
- Can do migration in levels: first do the migration after which perform the optimization later utilizing rewrite_data_files process (weblog to comply with).
- Comparatively quick because the underlying information recordsdata are saved in place. You don’t have to fret about creating a brief desk and swapping it later. The process will try this for you atomically as soon as the migration is completed.
- Since a Hive backup is obtainable one can revert the change completely by dropping the newly created Iceberg desk and by renaming the Hive backup desk (__backup__) desk to its unique identify.
CONS:
- If the underlying information isn’t optimized, or has a number of small recordsdata, these disadvantages might be carried ahead to the Iceberg desk as nicely. Question engines (Impala, Hive, Spark) would possibly mitigate a few of these issues through the use of Iceberg’s metadata recordsdata. The underlying information file areas is not going to change. So if the prefixes of the file path are widespread throughout a number of recordsdata we could proceed to undergo from S3 throttling (see Object Retailer File Layout to see easy methods to configure it correctly.) In CDP we solely assist migrating exterior tables. Hive managed tables can’t be migrated. Additionally, the underlying file format for the desk must be one among avro, orc, or parquet.
Observe: There may be additionally a SparkAction within the JAVA API.
Answer 1B: utilizing Hive’s “ALTER TABLE” command
Cloudera carried out a straightforward technique to do the migration in Hive. All it’s important to do is to change the desk properties to set the storage handler to “HiveIcebergStorageHandler.”

The professionals and cons of this method are basically the identical as Answer 1B. The migration is completed in place and the underlying information recordsdata usually are not modified. Hive creates Iceberg’s metadata recordsdata for a similar actual desk.
Shadow desk migration
Answer 1C: utilizing the CTAS assertion
This resolution is most generic and it may probably be used with any processing engine (Spark/Hive/Impala) that helps SQL-like syntax.


You possibly can run primary sanity checks on the info to see if the newly created desk is sound.


As soon as you’re happy along with your sanity checking you might rename your “occasions” desk to a “backup_events” desk after which rename your “iceberg_events” to “occasions.” Remember the fact that in some instances the rename operation would possibly set off a listing rename of the underlying information listing. If that’s the case and your underlying information retailer is an object retailer like S3, that can set off a full copy of your information and might be very costly. If whereas creating the Iceberg desk the situation clause is specified, then the renaming operation of the Iceberg desk is not going to trigger the underlying information recordsdata to maneuver. The identify will change solely within the Hive metastore. The identical applies for Hive tables as nicely. In case your unique Hive desk was not created with the situation clause specified, then the rename to backup will set off a listing rename. In that case, In case your filesystem is object retailer based mostly, then it may be greatest to drop it altogether. Given the nuances round desk rename it’s crucial to check with dummy tables in your system and test that you’re seeing your required conduct earlier than you carry out these operations on crucial tables.

You possibly can drop your “backup_events” if you want.
 Your shoppers can now resume their learn/write operations on the “occasions” they usually don’t even have to know that the underlying desk format has modified. Now let’s talk about the professionals and cons of this method.
Your shoppers can now resume their learn/write operations on the “occasions” they usually don’t even have to know that the underlying desk format has modified. Now let’s talk about the professionals and cons of this method.
PROS:
- The newly created information is nicely optimized for Iceberg and the info might be distributed nicely.
- Any present small recordsdata might be coalesced routinely.
- Widespread process throughout all of the engines.
- The newly created information recordsdata may benefit from Iceberg’s Object Retailer File Format, in order that the file paths have completely different prefixes, thus decreasing object retailer throttling. Please see the linked documentation to see easy methods to benefit from this function.
- This method isn’t essentially restricted to migrating a Hive desk. One may use the identical method emigrate tables out there in any processing engine like Delta, Hudi, and many others.
- You possibly can change the info format say from “orc” to “parquet.’’
CONS
- This may set off a full learn and write of the info and it may be an costly operation.
- Your whole information set might be duplicated. You’ll want to have ample space for storing out there. This shouldn’t be an issue in a public cloud backed by an object retailer.
Method 2
You don’t have the luxurious of lengthy downtime to do your migration. You need to let your shoppers or jobs proceed writing the info to the desk. This requires some planning and testing, however is feasible with some caveats. Right here is a method you are able to do it with Spark. You possibly can probably extrapolate the concepts introduced to different engines.
- Create an Iceberg desk with the specified properties. Remember the fact that it’s important to preserve the partitioning scheme the identical for this to work appropriately.
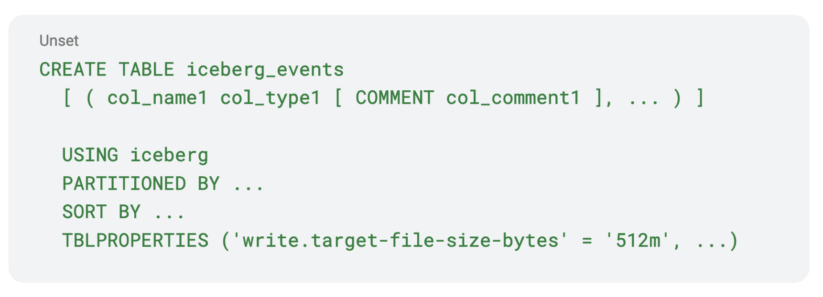
- Modify your shoppers or jobs to put in writing to each tables in order that they write to the “iceberg_events” desk and “occasions” desk. However for now, they solely learn from the “occasions” desk. Seize the timestamp from which your shoppers began writing to each of the tables.
- You programmatically record all of the recordsdata within the Hive desk that had been inserted earlier than the timestamp you captured in step 2.
- Add all of the recordsdata captured in step 3 to the Iceberg desk utilizing the “add_files” process. The “add_files” process will merely add the file to your Iceberg desk. You additionally would possibly have the ability to benefit from your desk’s partitioning scheme to skip step 3 completely and add recordsdata to your newly created Iceberg desk utilizing the “add_files” process.

- For those who don’t have entry to Spark you would possibly merely learn every of the recordsdata listed in step 3 and insert them into the “iceberg_events.”
- When you efficiently add all the info recordsdata, you’ll be able to cease your shoppers from studying/writing to the previous “occasions” and use the brand new “iceberg_events.”
Some caveats and notes
- In step 2, you’ll be able to management which tables your shoppers/jobs should write to utilizing some flag that may be fetched from exterior sources like atmosphere variables, some database (like Redis) pointer, and properties recordsdata, and many others. That method you solely have to change your consumer/job code as soon as and don’t need to preserve modifying it for every step.
- In step 2, you’re capturing a timestamp that might be used to calculate recordsdata wanted for step 3; this might be affected by clock drift in your nodes. So that you would possibly need to sync all of your nodes earlier than you begin the migration course of.
- In case your desk is partitioned by date and time (as most actual world information is partitioned), as in all new information coming will go to a brand new partition on a regular basis, then you definitely would possibly program your shoppers to start out writing to each the tables from a particular date and time. That method you simply have to fret about including the info from the previous desk (“occasions”) to the brand new desk (“Iceberg_events”) from that date and time, and you may benefit from your partitioning scheme and skip step 3 completely. That is the method that must be used at any time when attainable.
Conclusion
Any massive migration is hard and must be thought by fastidiously. Fortunately, as mentioned above there are a number of methods at our disposal to do it successfully relying in your use case. If in case you have the flexibility to cease all of your jobs whereas the migration is occurring it’s comparatively easy, however if you wish to migrate with minimal to no downtime then that requires some planning and cautious pondering by your information format. You need to use a mixture of the above approaches to greatest fit your wants.
To be taught extra:
- For extra on desk migration, please discuss with respective on-line documentations in Cloudera Information Warehouse (CDW) and Cloudera Information Engineering (CDE).
- Watch our webinar Supercharge Your Analytics with Open Information Lakehouse Powered by Apache Iceberg. It features a dwell demo recording of Iceberg capabilities.
- Attempt Cloudera Information Warehouse (CDW), Cloudera Information Engineering (CDE), and Cloudera Machine Studying (CML) by signing up for a 60 day trial, or check drive CDP. You may as well schedule a demo by clicking right here or if you have an interest in chatting about Apache Iceberg in CDP, contact your account group.