Apache Impala and Apache Kudu make a terrific mixture for real-time analytics on streaming knowledge for time collection and real-time knowledge warehousing use instances. Greater than 200 Cloudera clients have applied Apache Kudu with Apache Spark for ingestion and Apache Impala for real-time BI use instances efficiently over the past decade, with 1000’s of nodes operating Apache Kudu. These use instances have diversified from telecom 4G/5G analytics to real-time oil and fuel reporting and alerting, to provide chain use instances for pharmaceutical corporations or core banking and inventory buying and selling analytics techniques.
The multitude of use instances that Apache Kudu can serve is pushed by its efficiency, a columnar C++ backed storage engine that permits knowledge to be ingested and served inside seconds of ingestion. Together with its pace, consistency, and atomicity, Apache Kudu additionally helps transactional properties for updates and deletes, enabling use instances that historically write as soon as and skim a number of instances, one thing distributed file techniques had been unable to assist. Apache Impala is a distributed C++ backed SQL engine that integrates with Kudu to serve BI outcomes over hundreds of thousands of rows assembly sub-second service-level agreements.
Cloudera presents Apache Kudu to run in Actual Time DataMart Clusters, and Apache Impala to run in Kubernetes within the Cloudera Knowledge Warehouse kind issue. With a scalable Impala operating in CDW, clients needed a method to join CDW to Kudu service in DataHub clusters. On this weblog we’ll clarify combine them collectively to realize separation of compute (i.e. Impala) and storage (i.e. Kudu). Prospects can scale up each layers independently to deal with workloads as per demand. This additionally permits superior eventualities the place clients can join a number of CDW Digital Clusters to completely different real-time knowledge mart clusters to hook up with a Kudu cluster particular for his or her workloads.
Configuration Steps
Stipulations
- Create a Kudu DataHub cluster of model 7.2.15 or later
- Guarantee CDW atmosphere is upgraded to 1.6.1-b258 or later launch with run time 2023.0.13.20
- Create a Impala digital warehouse in CDW
Step 1: Get Kudu Grasp Node Particulars
1-Login to CDP, navigate to Knowledge Hub Clusters, and choose the Kudu Actual Time Knowledge Mart cluster that you simply need to question from CDW.
2-Click on on the cluster particulars and use the “Nodes” tab to seize the small print of the three Kudu grasp nodes as proven under.
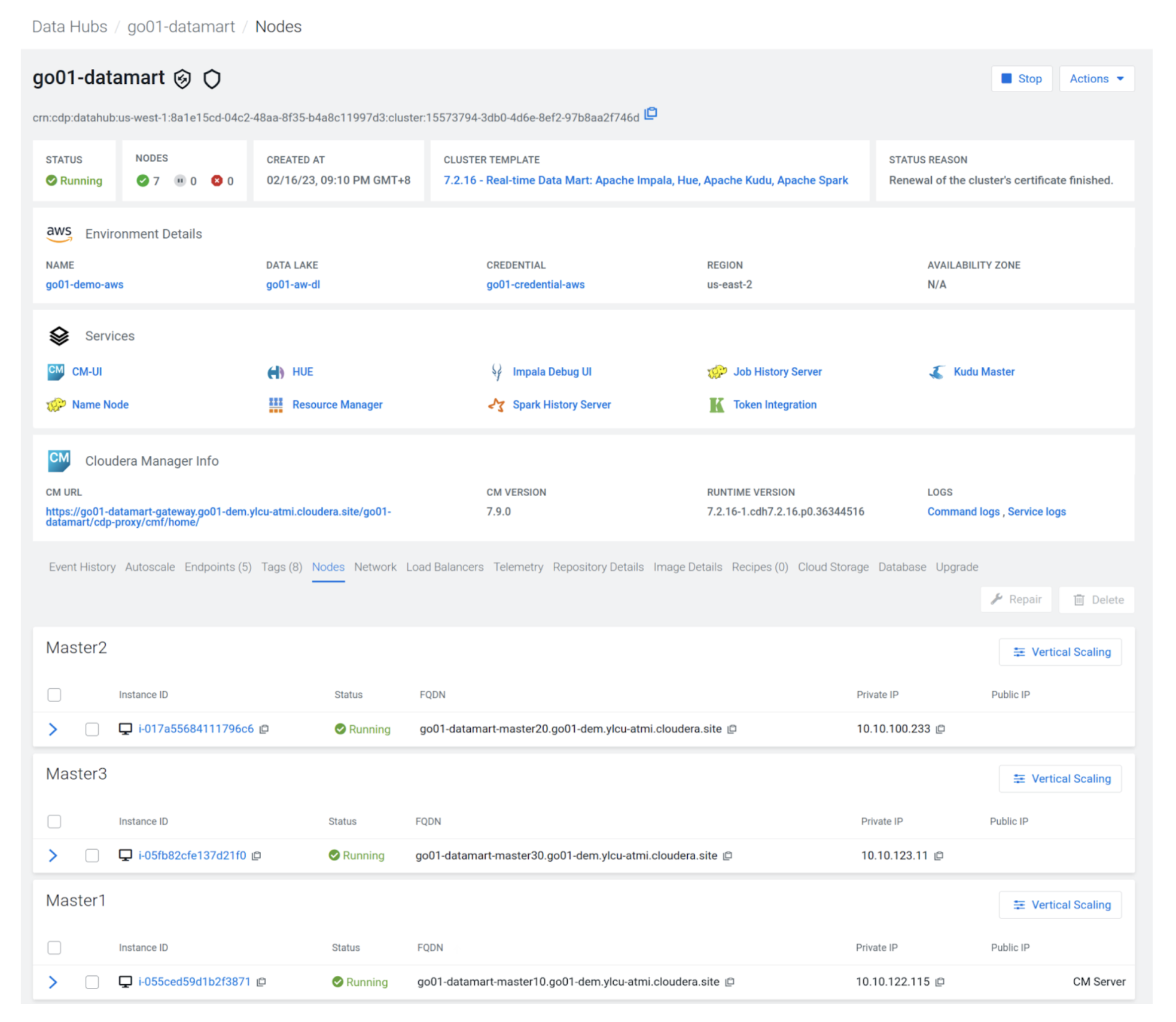
Within the under instance the grasp nodes are:
- go01-datamart-master20.go01-dem.ylcu-atmi.cloudera.website
- go01-datamart-master30.go01-dem.ylcu-atmi.cloudera.website
- Go01-datamart-master10.go01-dem.ylcu-atmi.cloudera.website
Step 2: Configure CDW Impala Digital Warehouse
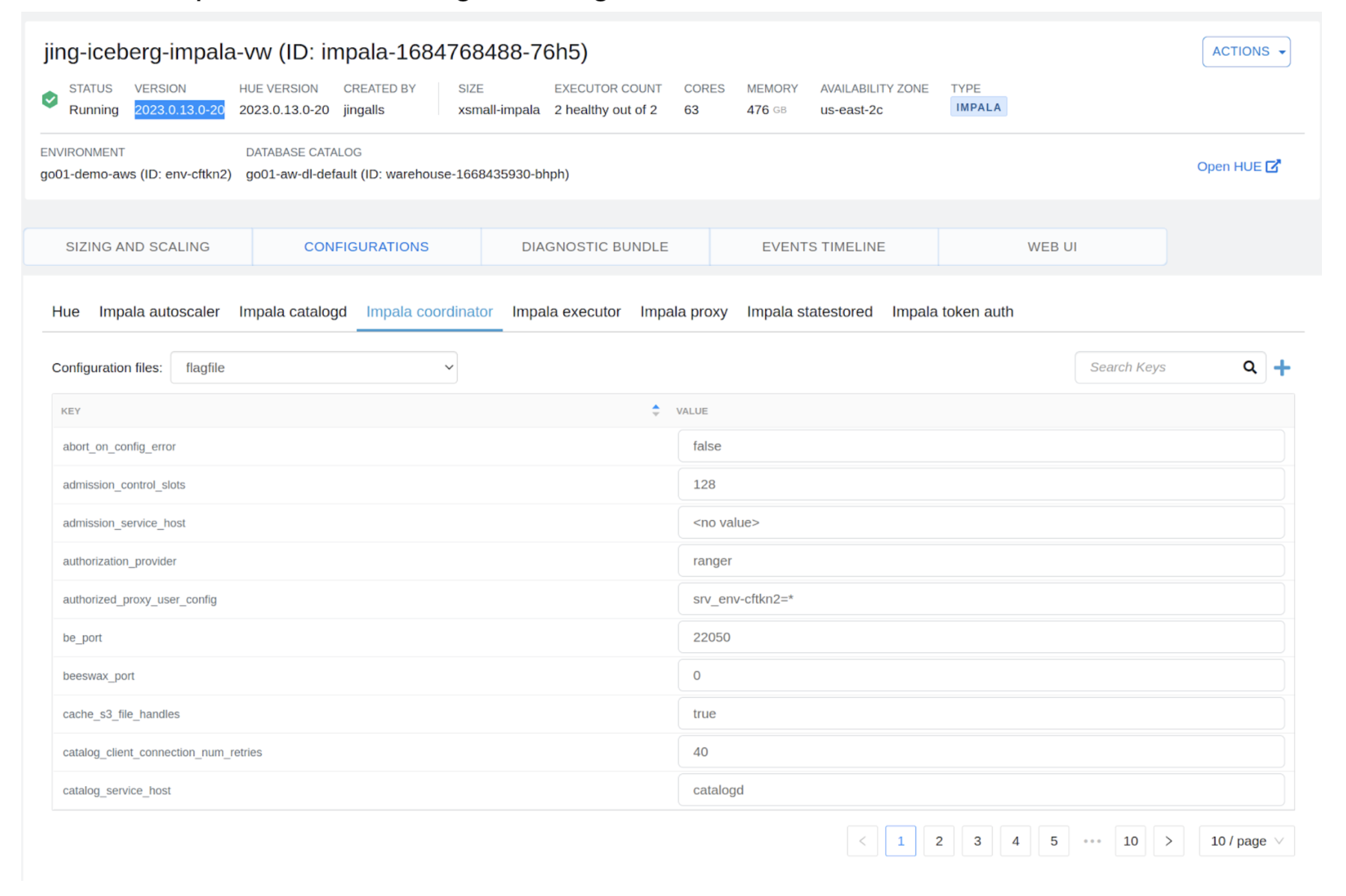
1- Navigate to CDW and choose the Impala digital warehouse that you simply want to configure to work with Kudu in a real-time knowledge mart cluster. Click on “Edit” and navigate to the configuration web page. Be sure that the Impala VW model is 2023.0.13-20 or greater.
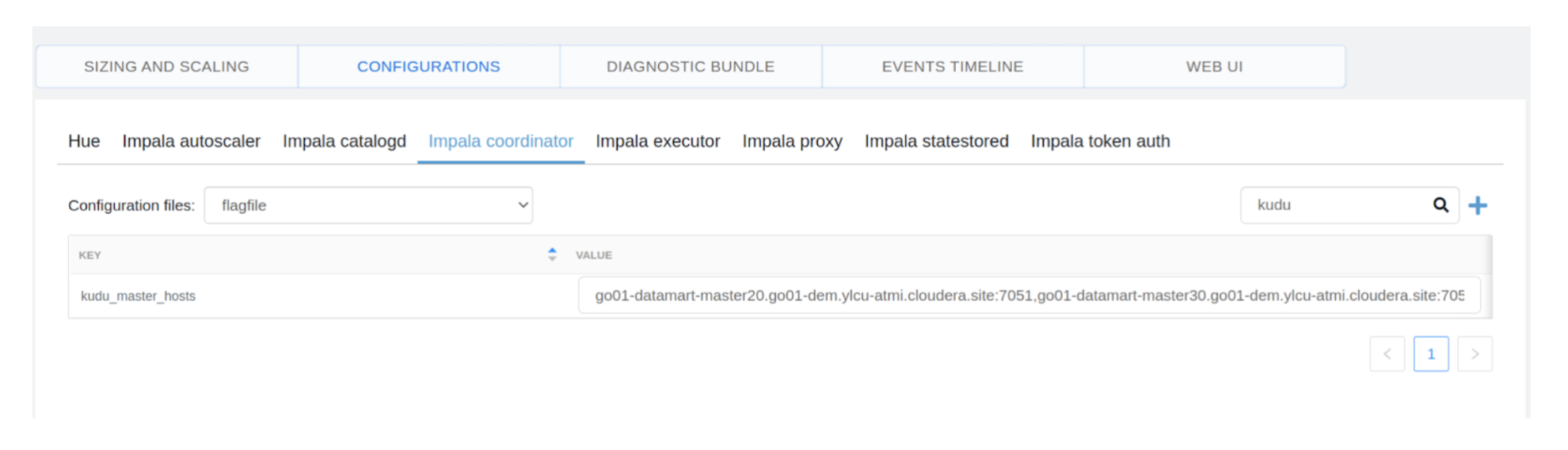
2- Choose the Impala coordinator flag file configuration to edit as proven under:
3- Seek for “kudu_master_hosts” configuration and edit the worth to the under:
Go01-datamart-master20.go01-dem.ylcu-atmi.cloudera.website:7051 ,go01-datamart-master30.go01-dem.ylcu-atmi.cloudera.website:7051, go01-datamart-master10.go01-dem.ylcu-atmi.cloudera.website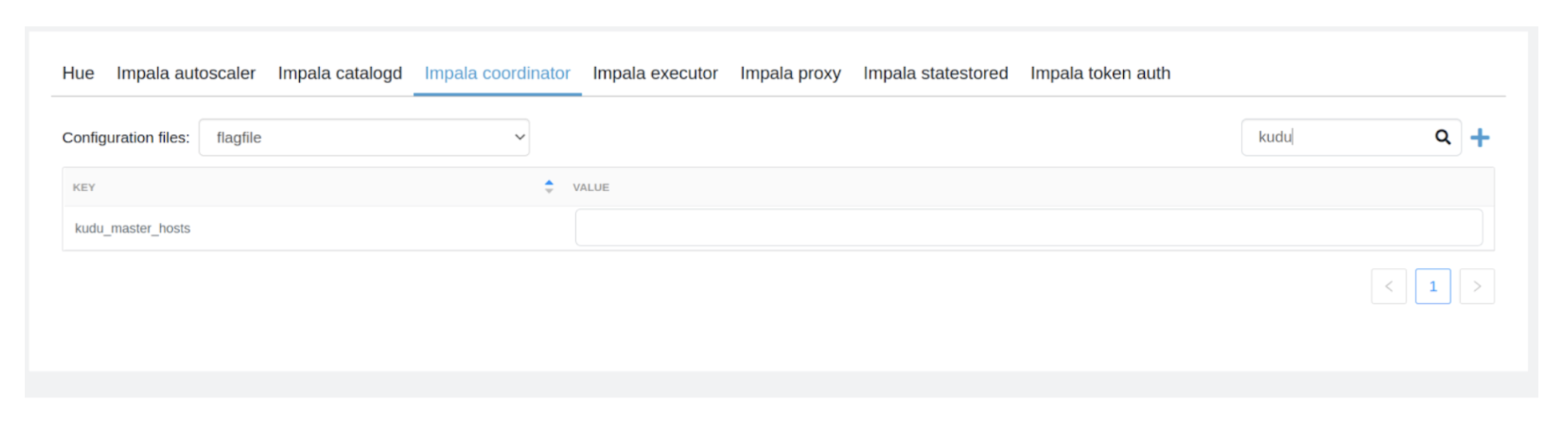
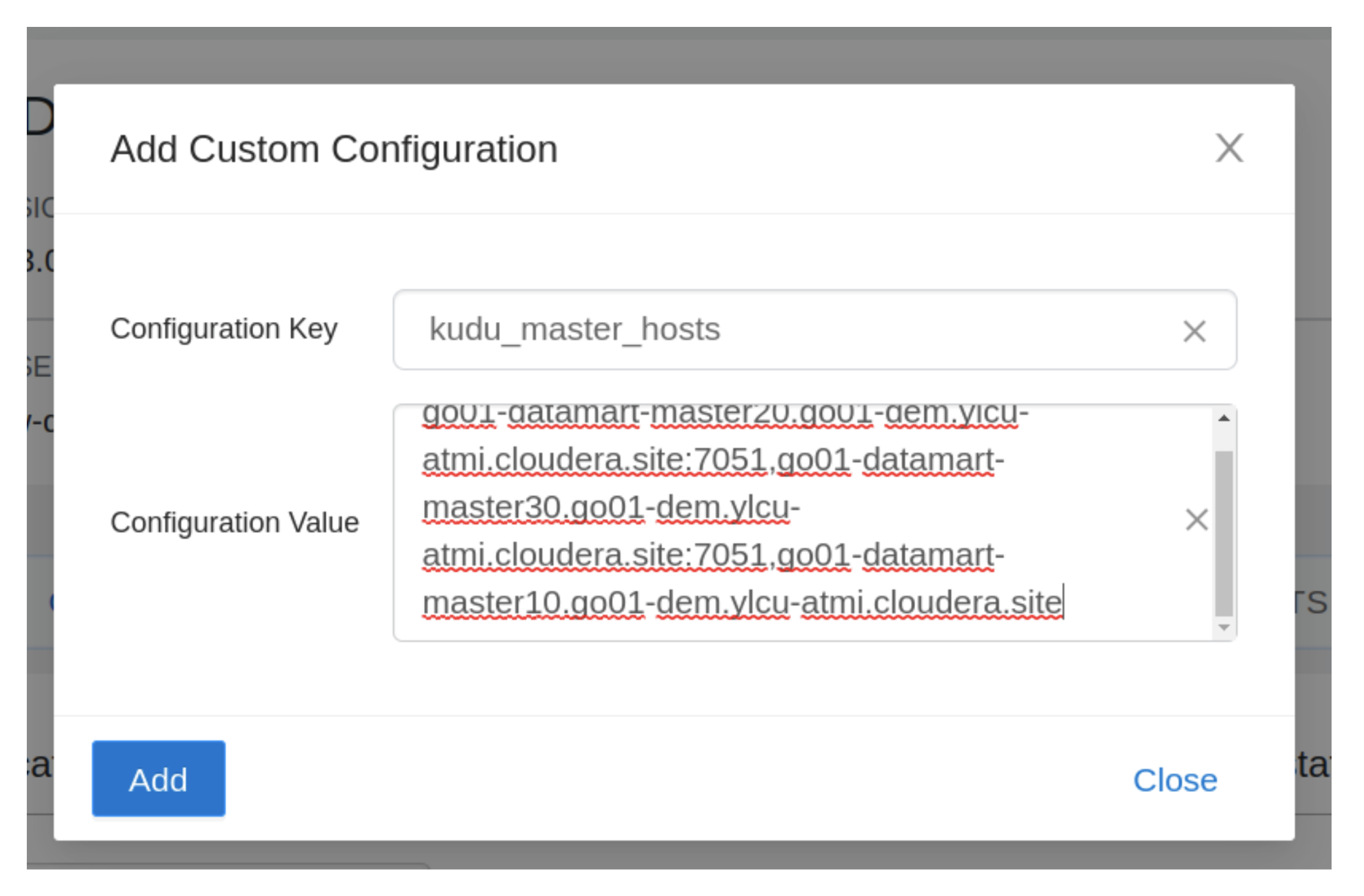
4- If the “kudu_master_hosts” configuration is just not discovered then click on the “+” icon and the configuration as under:
5- Click on on “apply modifications” and anticipate the VW to restart.
Step 3: Run Queries on Kudu Tables
As soon as the digital warehouse finishes updating, you’ll be able to question Kudu tables from Hue, an Impala shell, or an ODBC/JDBC consumer as proven under:

Abstract
With CDW and Kudu DataHub integration you at the moment are capable of scale up your compute assets on demand and dedicate the DataHub assets to solely operating Kudu. Working Kudu queries from an Impala digital warehouse offers advantages, equivalent to isolation from noisy neighbors, auto-scaling, and autosuspend.
You too can probably use Cloudera Knowledge Engineering to ingest knowledge into Kudu DH cluster, thereby utilizing the DH cluster only for storage. Superior customers may use the TBLPROPERTIES to set the Kudu cluster particulars to question knowledge from any Kudu DH cluster of alternative.

Amongst different options with this integration you are also in a position to make use of newest CDW options like:
- JWT authentication in CDW Impala.
- Utilizing a single Impala service for object retailer and Kudu tables that makes it straightforward for finish customers/BI instruments to not must configure multiple Impala service.
- Scale up and out Kudu in DH, solely once you run out of house. Ultimately you can even cease operating Impala in a real-time DM template and simply use CDW Impala to question Kudu in DH.
What’s Subsequent
- For full setup information check with CDW documentation on this subject. To know extra about Cloudera Knowledge Warehouse please click on right here.
- In case you are all for chatting about Cloudera Knowledge Warehouse (CDW) + Kudu in CDP, please attain out to your account staff.