Within the dynamic realm of language mannequin growth, a current groundbreaking paper titled “Direct Desire Optimization (DPO)” by Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Chris Manning, and Chelsea Finn, has captured the eye of AI luminaries like Andrew Ng. This text delves into the revolutionary points of DPO and its potential to redefine the way forward for language fashions.
Andrew Ng, not too long ago expressed his profound admiration for DPO. In his view, this analysis represents a major simplification over conventional strategies like Reinforcement Studying from Human Suggestions (RLHF) for aligning language fashions to human preferences. Ng lauds the paper for demonstrating that vital developments in AI can stem from deep algorithmic and mathematical insights, even with out immense computational sources.

Key Ideas
Understanding the Complexity of Conventional Language Fashions
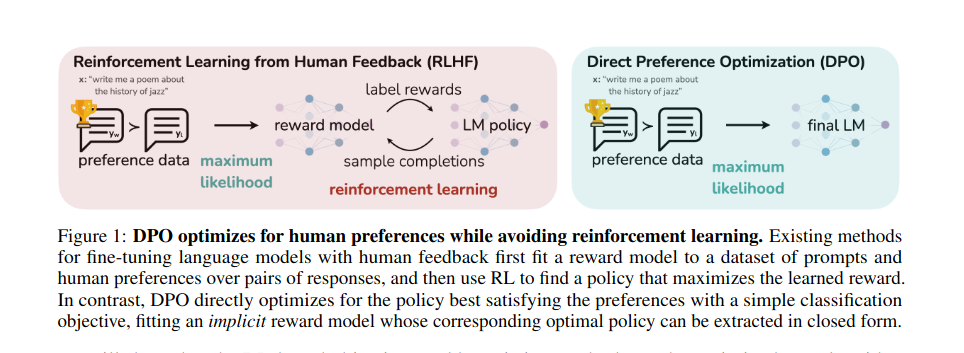
Historically, the alignment of language fashions with human preferences has been achieved by way of a fancy course of often known as Reinforcement Studying from Human Suggestions (RLHF). This methodology entails a multi-stage course of:
- Supervised High quality-Tuning (SFT): RLHF begins with a pre-trained language mannequin, which is then fine-tuned on high-quality datasets for particular purposes.
- Desire Sampling and Reward Studying: This part entails accumulating human preferences between pairs of language mannequin outputs and utilizing these preferences to be taught a reward perform, sometimes using the Bradley-Terry mannequin.
- Reinforcement Studying Optimization: The ultimate part makes use of the discovered reward perform to additional fine-tune the language mannequin, specializing in maximizing the reward for the outputs whereas sustaining proximity to its unique coaching.
Direct Desire Optimization (DPO)
The paper introduces DPO, a brand new parameterization of the reward mannequin in RLHF, which allows the extraction of the corresponding optimum coverage in a closed kind. This strategy simplifies the RLHF drawback to a easy classification loss, making the algorithm secure, performant, and computationally light-weight. DPO innovates by combining the reward perform and language mannequin right into a single transformer community. This simplification means solely the language mannequin wants coaching, aligning it with human preferences extra immediately and effectively. The class of DPO lies in its capability to infer the reward perform the language mannequin is finest at maximizing, thereby streamlining your complete course of.
I requested ChatGPT to clarify the above to a 5 yr previous and right here is the outcome (hope you get a greater understanding, let me know in feedback):
“Think about you've got an enormous field of crayons to attract an image, however you are unsure which colours to decide on to take advantage of stunning image. Earlier than, you had to strive each single crayon one after the other, which took lots of time. However now, with one thing known as Direct Desire Optimization (DPO), it is like having a magical crayon that already is aware of your favourite colours and methods to make the prettiest image. So, as an alternative of attempting all of the crayons, you utilize this one particular crayon, and it helps you draw the proper image a lot quicker and simpler. That is how DPO works; it helps computer systems be taught what individuals like shortly and simply, similar to the magical crayon helps you make a phenomenal drawing.”
Comparability with RLHF
DPO is proven to fine-tune LMs to align with human preferences as effectively or higher than present strategies, together with PPO-based RLHF. It excels in controlling the sentiment of generations and matches or improves response high quality in summarization and single-turn dialogue duties. DPO is easier to implement and practice in comparison with conventional RLHF strategies.
Technical Particulars
- DPO’s Mechanism: DPO immediately optimizes for the coverage finest satisfying the preferences with a easy binary cross-entropy goal, becoming an implicit reward mannequin whose corresponding optimum coverage might be extracted in closed kind.
- Theoretical Framework: DPO depends on a theoretical desire mannequin, just like the Bradley-Terry mannequin, that measures how effectively a given reward perform aligns with empirical desire information. In contrast to present strategies that practice a coverage to optimize a discovered reward mannequin, DPO defines the desire loss as a perform of the coverage immediately.
- Benefits: DPO simplifies the desire studying pipeline considerably. It eliminates the necessity for sampling from the LM throughout fine-tuning or performing vital hyperparameter tuning.
Experimental Analysis
- Efficiency on Duties: Experiments reveal DPO’s effectiveness in duties equivalent to sentiment modulation, summarization, and dialogue. It reveals comparable or superior efficiency to PPO-based RLHF whereas being considerably less complicated.
- Theoretical Evaluation: The paper additionally offers a theoretical evaluation of DPO, relating it to points with actor-critic algorithms used for RLHF and demonstrating its benefits.
DPO vs RLHF
1. Methodology
- DPO: Direct Desire Optimization focuses on immediately optimizing language fashions to stick to human preferences. It operates with out express reward modeling or reinforcement studying, simplifying the coaching course of. DPO optimizes the identical goals as RLHF however with a simple binary cross-entropy loss. It will increase the relative log chance of most well-liked responses and makes use of a dynamic significance weight to forestall mannequin degeneration.
- RLHF: Reinforcement Studying from Human Suggestions sometimes entails a fancy process that features becoming a reward mannequin based mostly on human preferences and fine-tuning the language mannequin utilizing reinforcement studying to maximise this estimated reward. This course of is extra computationally intensive and might be unstable.
2. Implementation Complexity
- DPO: Simpler to implement attributable to its simplicity and direct strategy. It doesn’t require vital hyperparameter tuning or sampling from the language mannequin throughout fine-tuning.
- RLHF: Entails a extra advanced and sometimes unstable coaching course of with reinforcement studying, requiring cautious hyperparameter tuning and doubtlessly sampling from the language mannequin.
3. Effectivity and Efficiency
- DPO: Demonstrates at the least equal or superior efficiency to RLHF strategies, together with PPO-based RLHF, in duties like sentiment modulation, summarization, and dialogue. It is usually computationally light-weight and offers a secure coaching surroundings.
- RLHF: Whereas efficient in aligning language fashions with human preferences, it may be much less environment friendly and secure in comparison with DPO, particularly in large-scale implementations.
4. Theoretical Basis
- DPO: Leverages an analytical mapping from reward capabilities to optimum insurance policies, enabling a metamorphosis of a loss perform over reward capabilities right into a loss perform over insurance policies. This avoids becoming an express standalone reward mannequin whereas nonetheless optimizing underneath present fashions of human preferences.
- RLHF: Usually depends on a extra conventional reinforcement studying strategy, the place a reward mannequin is educated based mostly on human preferences, after which a coverage is educated to optimize this discovered reward mannequin.
5. Empirical Outcomes:
- DPO: In empirical evaluations, DPO has proven to supply extra environment friendly frontiers when it comes to reward/KL tradeoff in comparison with PPO, reaching increased rewards whereas sustaining low KL. It additionally demonstrates higher efficiency in fine-tuning duties like summarization and dialogue.
- RLHF: PPO and different RLHF strategies, whereas efficient, might not obtain as environment friendly a reward/KL tradeoff as DPO. They might require entry to floor fact rewards for optimum efficiency, which isn’t at all times possible.
Impression and Future Prospects
Andrew anticipates that DPO will considerably affect language fashions within the coming years. This methodology has already been built-in into high-performing fashions like Mistral’s Mixtral, indicating its fast applicability. Ng’s optimism is tempered with warning, acknowledging that the long-term impression stays to be seen.
This growth underscores the continued innovation throughout the discipline of AI. Ng emphasizes that groundbreaking work isn’t unique to organizations with huge sources; deep pondering and a modest computational setup can yield vital breakthroughs. He additionally notes a media bias in direction of massive tech firms, suggesting that analysis like DPO deserves broader recognition.
Remaining Thought
Direct Desire Optimization presents a robust and scalable framework for coaching language fashions aligned with human preferences, lowering the complexity historically related to RLHF algorithms. Its emergence is a transparent signal that the sphere of AI, significantly in language mannequin growth, is ripe for innovation and development. With DPO, the way forward for language fashions appears poised for vital developments, pushed by insightful algorithmic and mathematical analysis.
Further Useful Hyperlinks: