
Companies all over the place have engaged in modernization initiatives with the objective of constructing their information and utility infrastructure extra nimble and dynamic. By breaking down monolithic apps into microservices architectures, for instance, or making modularized information merchandise, organizations do their finest to allow extra speedy iterative cycles of design, construct, check, and deployment of revolutionary options. The benefit gained from growing the pace at which a company can transfer via these cycles is compounded with regards to information apps – information apps each execute enterprise processes extra effectively and facilitate organizational studying/enchancment.
SQL Stream Builder streamlines this course of by managing your information sources, digital tables, connectors, and different assets your jobs may want, and permitting non technical area specialists to to shortly run variations of their queries.
Within the 1.9 launch of Cloudera’s SQL Stream Builder (out there on CDP Public Cloud 7.2.16 and within the Neighborhood Version), we now have redesigned the workflow from the bottom up, organizing all assets into Tasks. The discharge features a new synchronization characteristic, permitting you to trace your mission’s variations by importing and exporting them to a Git repository. The newly launched Environments characteristic means that you can export solely the generic, reusable elements of code and assets, whereas managing environment-specific configuration individually. Cloudera is due to this fact uniquely in a position to decouple the event of enterprise/occasion logic from different features of utility improvement, to additional empower area specialists and speed up improvement of actual time information apps.
On this weblog publish, we are going to check out how these new ideas and options can assist you develop advanced Flink SQL initiatives, handle jobs’ lifecycles, and promote them between totally different environments in a extra strong, traceable and automatic method.
What’s a Mission in SSB?
Tasks present a method to group assets required for the duty that you’re attempting to resolve, and collaborate with others.
In case of SSB initiatives, you may need to outline Information Sources (reminiscent of Kafka suppliers or Catalogs), Digital tables, Person Outlined Capabilities (UDFs), and write varied Flink SQL jobs that use these assets. The roles might need Materialized Views outlined with some question endpoints and API keys. All of those assets collectively make up the mission.
An instance of a mission is likely to be a fraud detection system applied in Flink/SSB. The mission’s assets could be considered and managed in a tree-based Explorer on the left aspect when the mission is open.
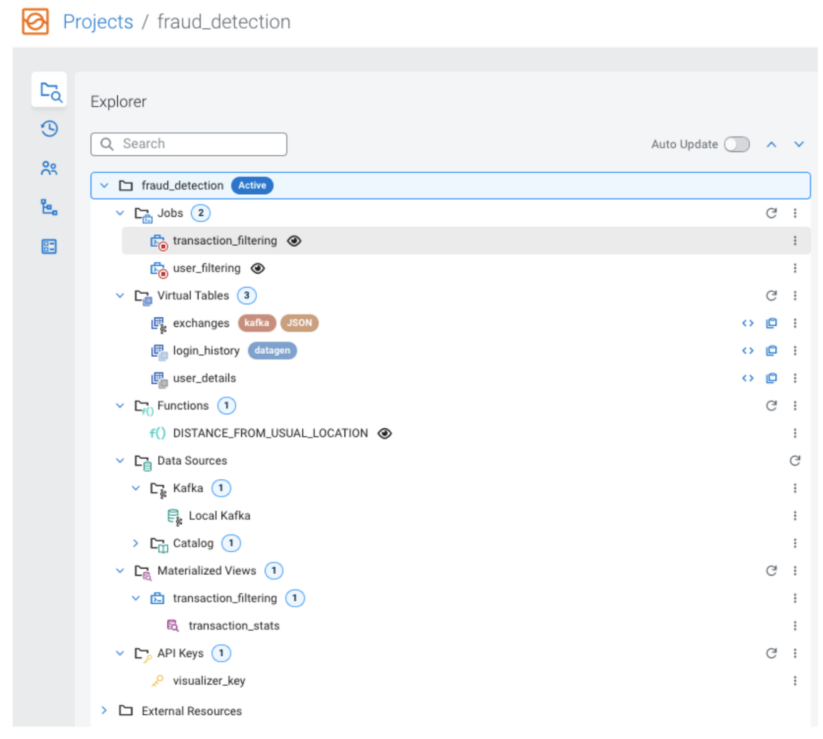
You may invite different SSB customers to collaborate on a mission, wherein case they will even be capable to open it to handle its assets and jobs.
Another customers is likely to be engaged on a unique, unrelated mission. Their assets is not going to collide with those in your mission, as they’re both solely seen when the mission is energetic, or are namespaced with the mission identify. Customers is likely to be members of a number of initiatives on the identical time, have entry to their assets, and change between them to pick out
the energetic one they need to be engaged on.
Assets that the person has entry to could be discovered beneath “Exterior Assets”. These are tables from different initiatives, or tables which can be accessed via a Catalog. These assets will not be thought of a part of the mission, they could be affected by actions outdoors of the mission. For manufacturing jobs, it is suggested to stay to assets which can be throughout the scope of the mission.
Monitoring adjustments in a mission
As any software program mission, SSB initiatives are consistently evolving as customers create or modify assets, run queries and create jobs. Tasks could be synchronized to a Git repository.
You may both import a mission from a repository (“cloning it” into the SSB occasion), or configure a sync supply for an present mission. In each instances, it’s worthwhile to configure the clone URL and the department the place mission recordsdata are saved. The repository comprises the mission contents (as json recordsdata) in directories named after the mission.
The repository could also be hosted wherever in your group, so long as SSB can hook up with it. SSB helps safe synchronization through HTTPS or SSH authentication.
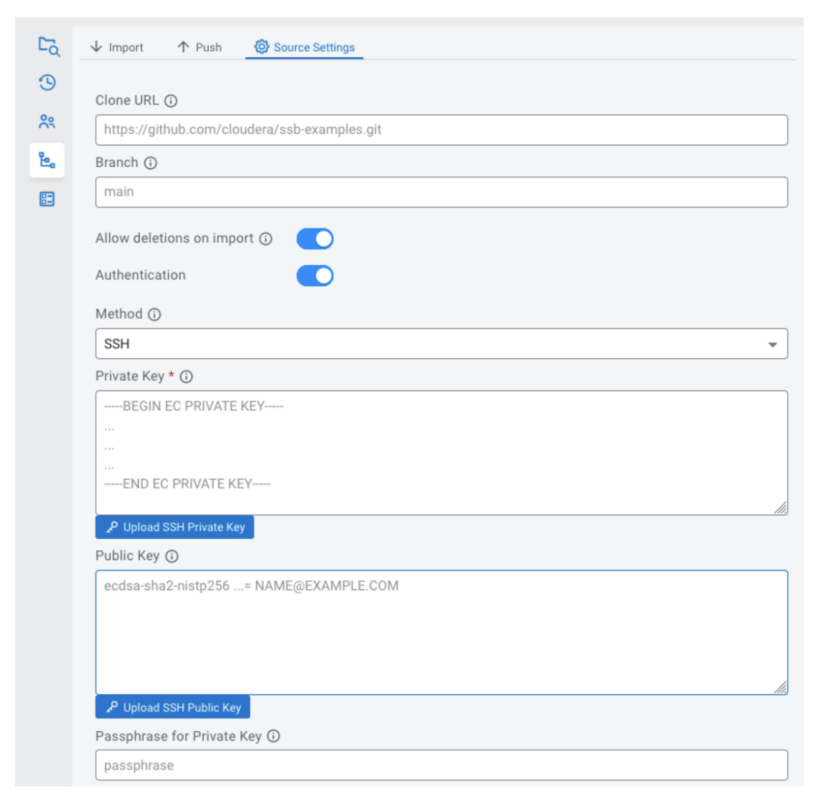
You probably have configured a sync supply for a mission, you possibly can import it. Relying on the “Enable deletions on import” setting, this may both solely import newly created assets and replace present ones; or carry out a “onerous reset”, making the native state match the contents of the repository solely.
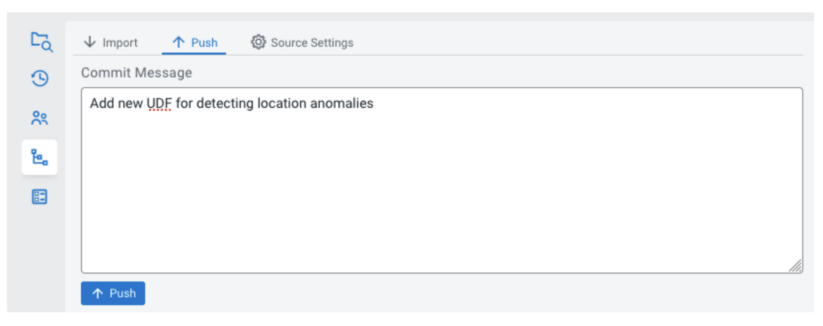
After making some adjustments to a mission in SSB, the present state (the assets within the mission) are thought of the “working tree”, a neighborhood model that lives within the database of the SSB occasion. Upon getting reached a state that you just wish to persist for the long run to see, you possibly can create a commit within the “Push” tab. After specifying a commit message, the present state will likely be pushed to the configured sync supply as a commit.
Environments and templating
Tasks include your online business logic, but it surely may want some customization relying on the place or on which circumstances you need to run it. Many functions make use of properties recordsdata to supply configuration at runtime. Environments had been impressed by this idea.
Environments (atmosphere recordsdata) are project-specific units of configuration: key-value pairs that can be utilized for substitutions into templates. They’re project-specific in that they belong to a mission, and also you outline variables which can be used throughout the mission; however impartial as a result of they don’t seem to be included within the synchronization with Git, they don’t seem to be a part of the repository. It is because a mission (the enterprise logic) may require totally different atmosphere configurations relying on which cluster it’s imported to.
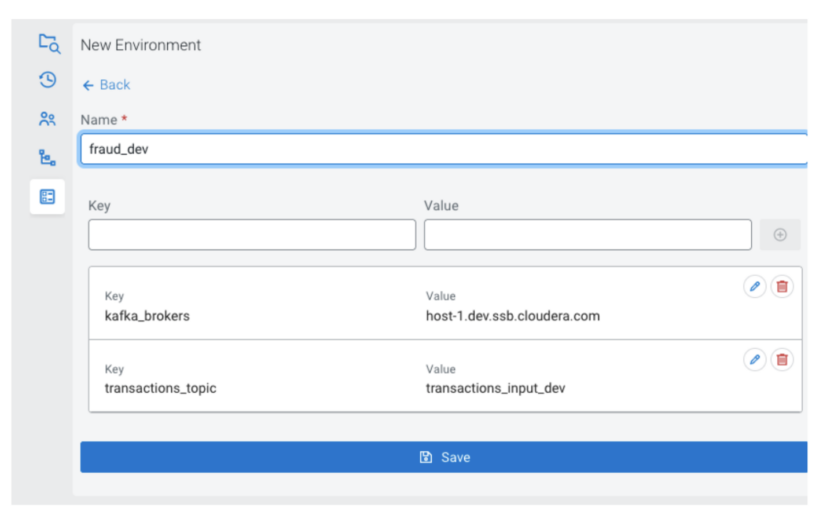
You may handle a number of environments for initiatives on a cluster, and they are often imported and exported as json recordsdata. There may be at all times zero or one energetic atmosphere for a mission, and it’s common among the many customers engaged on the mission. That signifies that the variables outlined within the atmosphere will likely be out there, regardless of which person executes a job.
For instance, one of many tables in your mission is likely to be backed by a Kafka matter. Within the dev and prod environments, the Kafka brokers or the subject identify is likely to be totally different. So you should utilize a placeholder within the desk definition, referring to a variable within the atmosphere (prefixed with ssb.env.):
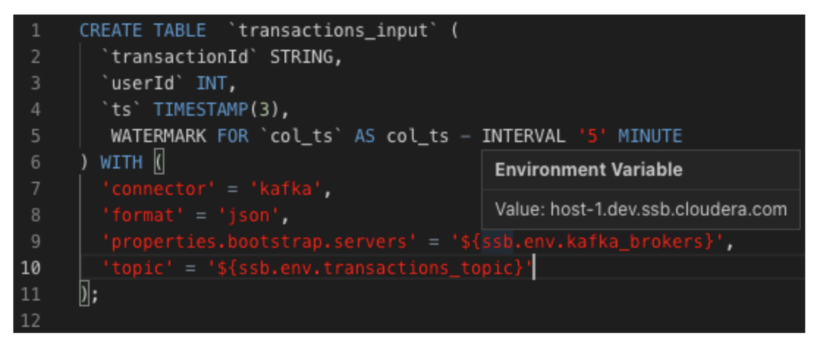
This manner, you should utilize the identical mission on each clusters, however add (or outline) totally different environments for the 2, offering totally different values for the placeholders.
Placeholders can be utilized within the values fields of:
- Properties of desk DDLs
- Properties of Kafka tables created with the wizard
- Kafka Information Supply properties (e.g. brokers, belief retailer)
- Catalog properties (e.g. schema registry url, kudu masters, customized properties)
SDLC and headless deployments
SQL Stream Builder exposes APIs to synchronize initiatives and handle atmosphere configurations. These can be utilized to create automated workflows of selling initiatives to a manufacturing atmosphere.
In a typical setup, new options or upgrades to present jobs are developed and examined on a dev cluster. Your workforce would use the SSB UI to iterate on a mission till they’re happy with the adjustments. They’ll then commit and push the adjustments into the configured Git repository.
Some automated workflows is likely to be triggered, which use the Mission Sync API to deploy these adjustments to a staging cluster, the place additional checks could be carried out. The Jobs API or the SSB UI can be utilized to take savepoints and restart present operating jobs.
As soon as it has been verified that the roles improve with out points, and work as supposed, the identical APIs can be utilized to carry out the identical deployment and improve to the manufacturing cluster. A simplified setup containing a dev and prod cluster could be seen within the following diagram:
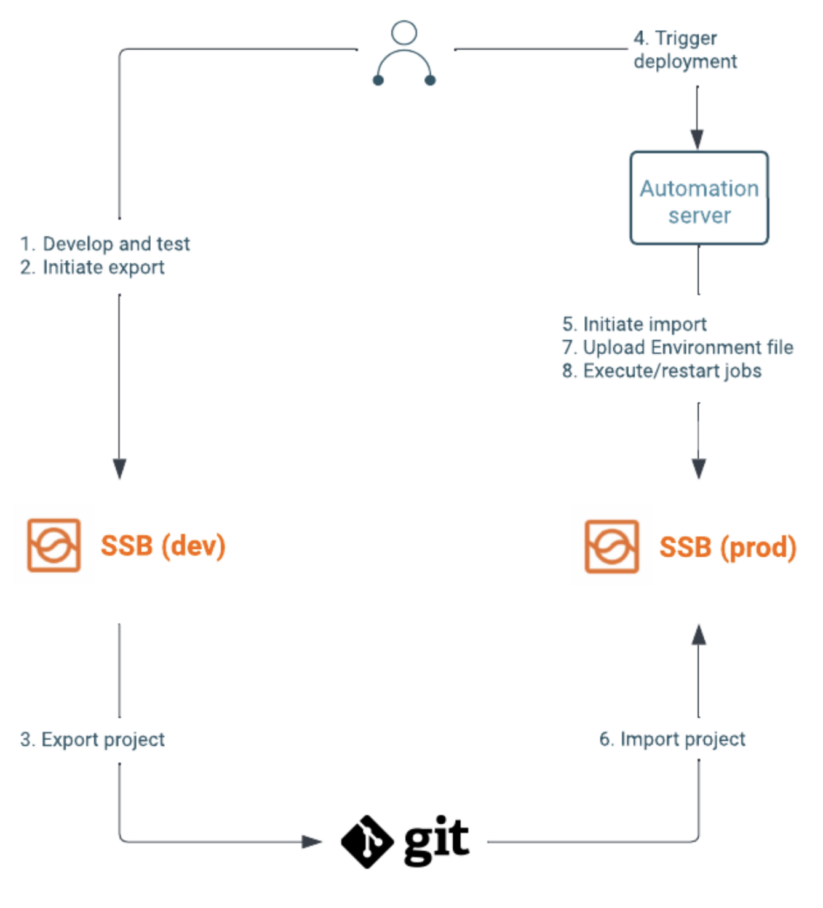
If there are configurations (e.g. kafka dealer urls, passwords) that differ between the clusters, you should utilize placeholders within the mission and add atmosphere recordsdata to the totally different clusters. With the Setting API this step can be a part of the automated workflow.
Conclusion
The brand new Mission-related options take growing Flink SQL initiatives to the following degree, offering a greater group and a cleaner view of your assets. The brand new git synchronization capabilities permit you to retailer and model initiatives in a strong and commonplace means. Supported by Environments and new APIs, they permit you to construct automated workflows to advertise initiatives between your environments.
Anyone can check out SSB utilizing the Stream Processing Neighborhood Version (CSP-CE). CE makes growing stream processors simple, as it may be achieved proper out of your desktop or some other improvement node. Analysts, information scientists, and builders can now consider new options, develop SQL-based stream processors domestically utilizing SQL Stream Builder powered by Flink, and develop Kafka Shoppers/Producers and Kafka Join Connectors, all domestically earlier than transferring to manufacturing in CDP.