
On this put up, I’ll show tips on how to use the Cloudera Information Platform (CDP) and its streaming options to arrange dependable knowledge trade in fashionable purposes between high-scale microservices, and be certain that the interior state will keep constant even beneath the very best load.
Introduction
Many fashionable software designs are event-driven. An event-driven structure permits minimal coupling, which makes it an optimum selection for contemporary, large-scale distributed programs. Microservices, as a part of their enterprise logic, generally don’t solely must persist knowledge into their very own native storage, however in addition they want to fireplace an occasion and notify different companies concerning the change of the interior state. Writing to a database and sending messages to a message bus shouldn’t be atomic, which signifies that if one among these operations fails, the state of the applying can change into inconsistent. The Transactional Outbox sample gives an answer for companies to execute these operations in a secure and atomic method, preserving the applying in a constant state.
On this put up I’m going to arrange a demo atmosphere with a Spring Boot microservice and a streaming cluster utilizing Cloudera Public Cloud.
The Outbox Sample
The final concept behind this sample is to have an “outbox” desk within the service’s knowledge retailer. When the service receives a request, it not solely persists the brand new entity, but additionally a document representing the message that will likely be revealed to the occasion bus. This fashion the 2 statements could be a part of the identical transaction, and since most fashionable databases assure atomicity, the transaction both succeeds or fails utterly.
The document within the “outbox” desk incorporates details about the occasion that occurred inside the applying, in addition to some metadata that’s required for additional processing or routing. Now there is no such thing as a strict schema for this document, however we’ll see that it’s value defining a standard interface for the occasions to have the ability to course of and route them in a correct method. After the transaction commits, the document will likely be obtainable for exterior customers.
This exterior client could be an asynchronous course of that scans the “outbox” desk or the database logs for brand spanking new entries, and sends the message to an occasion bus, resembling Apache Kafka. As Kafka comes with Kafka Join, we are able to leverage the capabilities of the pre-defined connectors, for instance the Debezium connector for PostgreSQL, to implement the change knowledge seize (CDC) performance.
Situation
Let’s think about a easy software the place customers can order sure merchandise. An OrderService receives requests with order particulars {that a} person simply despatched. This service is required to do the next operations with the information:
- Persist the order knowledge into its personal native storage.
- Ship an occasion to inform different companies concerning the new order. These companies is perhaps answerable for checking the stock (eg. InventoryService) or processing a cost (eg. PaymentService).
Because the two required steps should not atomic, it’s attainable that one among them is profitable whereas the opposite fails. These failures may end up in surprising situations, and ultimately corrupt the state of the purposes.
Within the first failure state of affairs, if the OrderService persists the information efficiently however fails earlier than publishing the message to Kafka, the applying state turns into inconsistent:
Equally, if the database transaction fails, however the occasion is revealed to Kafka, the applying state turns into inconsistent.
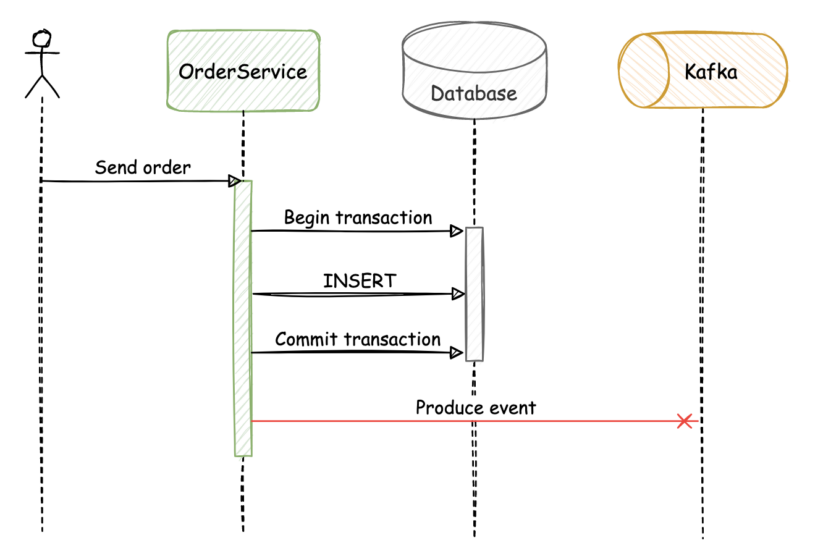
Fixing these consistency issues otherwise would add pointless complexity to the enterprise logic of the companies, and may require implementing a synchronous strategy. An vital draw back on this strategy is that it introduces extra coupling between the 2 companies; one other is that it doesn’t let new customers be a part of the occasion stream and skim the occasions from the start.
The identical circulate with an outbox implementation would look one thing like this:
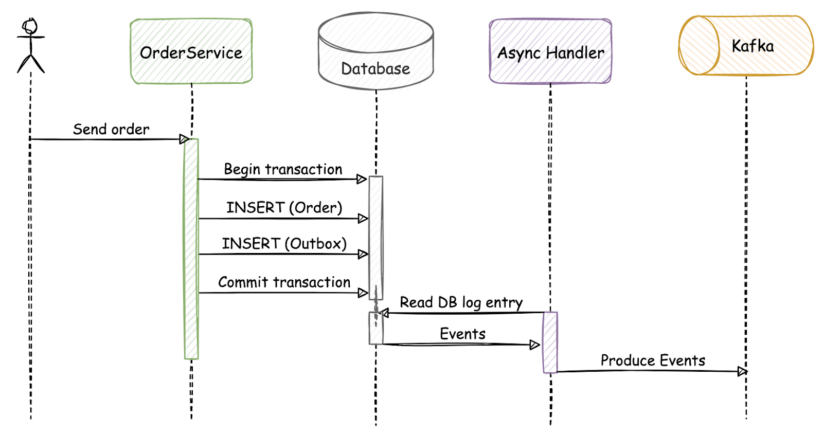
On this state of affairs, the “order” and “outbox” tables are up to date in the identical atomic transaction. After a profitable commit, the asynchronous occasion handler that constantly displays the database will discover the row-level adjustments, and ship the occasion to Apache Kafka by Kafka Join.
The supply code of the demo software is on the market on github. Within the instance, an order service receives new order requests from the person, saves the brand new order into its native database, then publishes an occasion, which can ultimately find yourself in Apache Kafka. It’s carried out in Java utilizing the Spring framework. It makes use of a Postgres database as a neighborhood storage, and Spring Information to deal with persistence. The service and the database run in docker containers.
For the streaming half, I’m going to make use of the Cloudera Information Platform with Public Cloud to arrange a Streams Messaging DataHub, and join it to our software. This platform makes it very simple to provision and arrange new workload clusters effectively.
NOTE: Cloudera Information Platform (CDP) is a hybrid knowledge platform designed for unmatched freedom to decide on—any cloud, any analytics, any knowledge. CDP delivers quicker and simpler knowledge administration and knowledge analytics for knowledge wherever, with optimum efficiency, scalability, safety, and governance.
The structure of this resolution seems to be like this on a excessive stage:
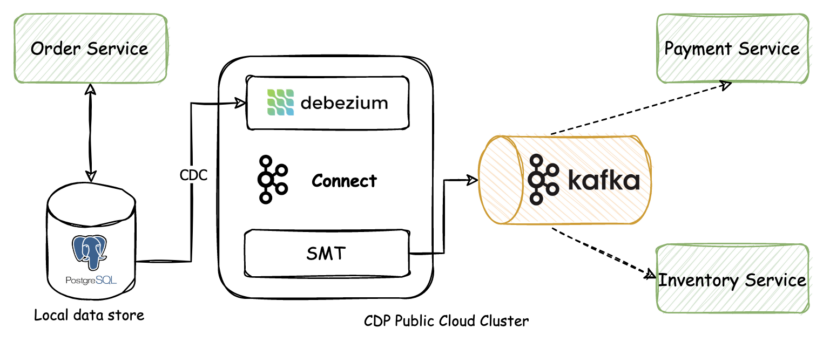
The outbox desk
The outbox desk is a part of the identical database the place the OrderService saves its native knowledge. When defining a schema for our database desk, it is very important take into consideration what fields are wanted to course of and route the messages to Kafka. The next schema is used for the outbox desk:
| Column | Sort |
| uuid | uuid |
| aggregate_type | character various(255) |
| created_on | timestamp with out time zone |
| event_type | character various(255) |
| payload | character various(255) |
The fields signify these:
- uuid: The identifier of the document.
- aggregate_type: The combination kind of the occasion. Associated messages could have the identical mixture kind, and it may be used to route the messages to the proper Kafka subject. For instance, all information associated to orders can have an mixture kind “Order,” which makes it simple for the occasion router to route these messages to the “Order” subject.
- created_on: The timestamp of the order.
- event_type: The kind of the occasion. It’s required so that buyers can resolve whether or not to course of and tips on how to course of a given occasion.
- payload: The precise content material of the occasion. The dimensions of this area ought to be adjusted primarily based on the necessities and the utmost anticipated measurement of the payload.
The OrderService
The OrderService is a straightforward Spring Boot microservice, which exposes two endpoints. There’s a easy GET endpoint for fetching the checklist of orders, and a POST endpoint for sending new orders to the service. The POST endpoint’s handler not solely saves the brand new knowledge into its native database, but additionally fires an occasion inside the applying.

The strategy makes use of the transactional annotation. This annotation permits the framework to inject transactional logic round our methodology. With this, we are able to make it possible for the 2 steps are dealt with in an atomic method, and in case of surprising failures, any change will likely be rolled again. Because the occasion listeners are executed within the caller thread, they use the identical transaction because the caller.

Dealing with the occasions inside the applying is kind of easy: the occasion listener operate is known as for every fired occasion, and a brand new OutboxMessage entity is created and saved into the native database, then instantly deleted. The rationale for the short deletion is that the Debezium CDC workflow doesn’t study the precise content material of the database desk, however as a substitute it reads the append-only transaction log. The save() methodology name creates an INSERT entry within the database log, whereas the delete() name creates a DELETE entry. For each INSERT occasion, the message will likely be forwarded to Kafka. Different occasions resembling DELETE could be ignored now, because it doesn’t comprise helpful data for our use case. Another excuse why deleting the document is sensible is that no further disk house is required for the “Outbox” desk, which is very vital in high-scale streaming situations.
After the transaction commits, the document will likely be obtainable for Debezium.
Establishing a streaming atmosphere
To arrange a streaming atmosphere, I’m going to make use of CDP Public Cloud to create a workload cluster utilizing the 7.2.16 – Streams Messaging Mild Responsibility template. With this template, we get a working streaming cluster, and solely must arrange the Debezium associated configurations. Cloudera gives Debezium connectors from 7.2.15 (Cloudera Information Platform (CDP) public cloud launch, supported with Kafka 2.8.1+):
The streaming atmosphere runs the next companies:
- Apache Kafka with Kafka Join
- Zookeeper
- Streams Replication Supervisor
- Streams Messaging Supervisor
- Schema Registry
- Cruise Management
Now organising Debezium is value one other tutorial, so I can’t go into a lot element about tips on how to do it. For extra data discuss with the Cloudera documentation.
Making a connector
After the streaming atmosphere and all Debezium associated configurations are prepared, it’s time to create a connector. For this, we are able to use the Streams Messaging Supervisor (SMM) UI, however optionally there’s additionally a Relaxation API for registering and dealing with connectors.
The primary time our connector connects to the service’s database, it takes a constant snapshot of all schemas. After that snapshot is full, the connector constantly captures row-level adjustments that had been dedicated to the database. The connector generates knowledge change occasion information and streams them to Kafka subjects.
A pattern predefined json configuration in a Cloudera atmosphere seems to be like this:
{ "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "database.historical past.kafka.bootstrap.servers": "${cm-agent:ENV:KAFKA_BOOTSTRAP_SERVERS}", "database.hostname": "[***DATABASE HOSTNAME***]", "database.password": "[***DATABASE PASSWORD***]", "database.dbname": "[***DATABASE NAME***]", "database.person": "[***DATABASE USERNAME***]", "database.port": "5432", "duties.max": "1",, "producer.override.sasl.mechanism": "PLAIN", "producer.override.sasl.jaas.config": "org.apache.kafka.widespread.safety.plain.PlainLoginModule required username="[***USERNAME***]" password="[***PASSWORD***]";", "producer.override.safety.protocol": "SASL_SSL", "plugin.title": "pgoutput", "desk.whitelist": "public.outbox", "transforms": "outbox", "transforms.outbox.kind": "com.cloudera.kafka.join.debezium.transformer.CustomDebeziumTopicTransformer", "slot.title": "slot1" } |
Description of crucial configurations above:
- database.hostname: IP tackle or hostname of the PostgreSQL database server.
- database.person: Title of the PostgreSQL database person for connecting to the database.
- database.password: Password of the PostgreSQL database person for connecting to the database.
- database.dbname: The title of the PostgreSQL database from which to stream the adjustments.
- plugin.title: The title of the PostgreSQL logical decoding plug-in put in on the PostgreSQL server.
- desk.whitelist: The white checklist of tables that Debezium displays for adjustments.
- transforms: The title of the transformation.
- transforms.<transformation>.kind: The SMT plugin class that’s answerable for the transformation. Right here we use it for routing.
To create a connector utilizing the SMM UI:
- Go to the SMM UI house web page, choose “Join” from the menu, then click on “New Connector”, and choose PostgresConnector from the supply templates.
- Click on on “Import Connector Configuration…” and paste the predefined JSON illustration of the connector, then click on “Import.”
- To verify the configuration is legitimate, and our connector can log in to the database, click on on “Validate.”
- If the configuration is legitimate, click on “Subsequent,” and after reviewing the properties once more, click on “Deploy.”
- The connector ought to begin working with out errors.
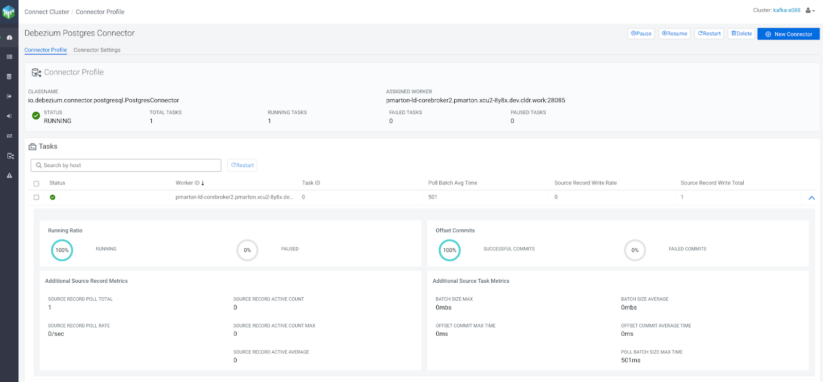
As soon as all the things is prepared, the OrderService can begin receiving requests from the person. These requests will likely be processed by the service, and the messages will ultimately find yourself in Kafka. If no routing logic is outlined for the messages, a default subject will likely be created:
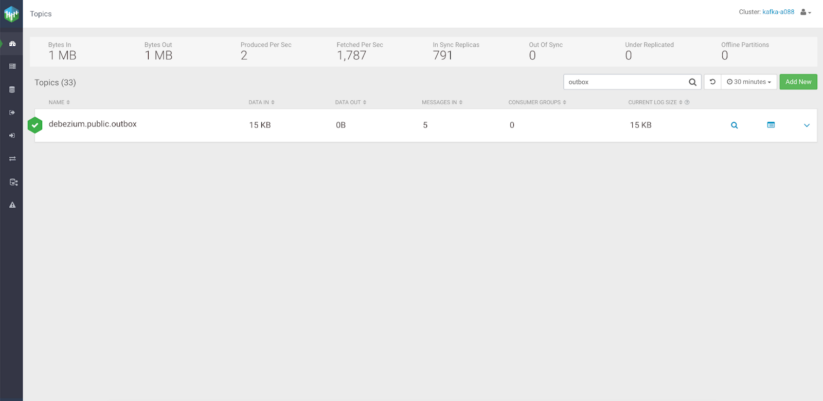
SMT plugin for subject routing
With out defining a logic for subject routing, Debezium will create a default subject in Kafka named “serverName.schemaName.tableName,” the place:
- serverName: The logical title of the connector, as specified by the “database.server.title” configuration property.
- schemaName: The title of the database schema wherein the change occasion occurred. If the tables should not a part of a particular schema, this property will likely be “public.”
- tableName: The title of the database desk wherein the change occasion occurred.
This auto generated title is perhaps appropriate for some use circumstances, however in a real-world state of affairs we would like our subjects to have a extra significant title. One other drawback with that is that it doesn’t allow us to logically separate the occasions into totally different subjects.
We are able to resolve this by rerouting messages to subjects primarily based on a logic we specify, earlier than the message reaches the Kafka Join converter. To do that, Debezium wants a single message remodel (SMT) plugin.
Single message transformations are utilized to messages as they circulate by Join. They remodel incoming messages earlier than they’re written to Kafka or outbound messages earlier than they’re written to the sink. In our case, we have to remodel messages which have been produced by the supply connector, however not but written to Kafka. SMTs have lots of totally different use circumstances, however we solely want them for subject routing.
The outbox desk schema incorporates a area referred to as “aggregate_type.” A easy mixture kind for an order associated message could be “Order.” Based mostly on this property, the plugin is aware of that the messages with the identical mixture kind should be written to the identical subject. As the mixture kind could be totally different for every message, it’s simple to resolve the place to route the incoming message.
A easy SMT implementation for subject routing seems to be like this:

The operation kind could be extracted from the Debezium change message. Whether it is delete, learn or replace, we merely ignore the message, as we solely care about create (op=c) operations. The vacation spot subject could be calculated primarily based on the “aggregate_type.” If the worth of “aggregate_type” is “Order,” the message will likely be despatched to the “orderEvents” subject. It’s simple to see that there are lots of potentialities of what we are able to do with the information, however for now the schema and the worth of the message is shipped to Kafka together with the vacation spot subject title.
As soon as the SMT plugin is prepared it needs to be compiled and packaged as a jar file. The jar file must be current on the plugin path of Kafka Join, so will probably be obtainable for the connectors. Kafka Join will discover the plugins utilizing the plugin.path employee configuration property, outlined as a comma-separated checklist of listing paths.
To inform the connectors which transformation plugin to make use of, the next properties should be a part of the connector configuration:
| transforms | outbox |
| transforms.outbox.kind | com.cloudera.kafka.join.debezium.transformer.CustomDebeziumTopicTransformer |
After creating a brand new connector with the SMT plugin, as a substitute of the default subject the Debezium producer will create a brand new subject referred to as orderEvents, and route every message with the identical mixture kind there:
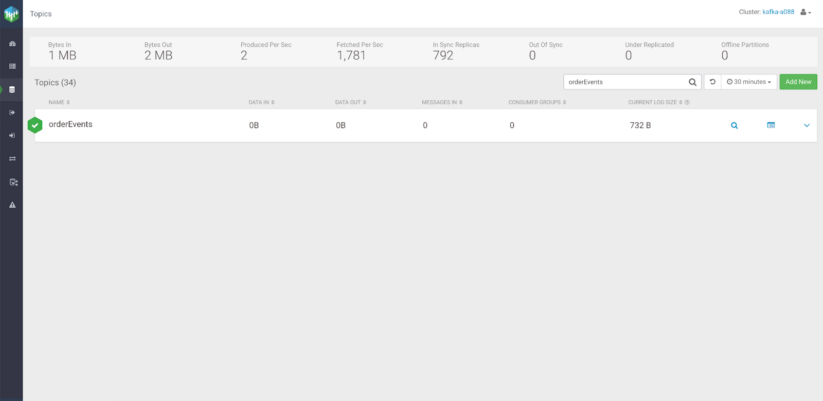
For present SMT plugins, verify the Debezium documentation on transformations.
Combination sorts and partitions
Earlier when creating the schema for the outbox desk, the aggregate_type area was used to indicate which mixture root the occasion is said to. It makes use of the identical concept as a domain-driven design: associated messages could be grouped collectively. This worth will also be used to route these messages to the proper subject.
Whereas sending messages which can be a part of the identical area to the identical subject helps with separating them, generally different, stronger ensures are wanted, for instance having associated messages in the identical partition to allow them to be consumed so as. For this objective the outbox schema could be prolonged with an aggregate_id. This ID will likely be used as a key for the Kafka message, and it solely requires a small change within the SMT plugin. All messages with the identical key will go to the identical partition. Which means that if a course of is studying solely a subset of the partitions in a subject, all of the information for a single key will likely be learn by the identical course of.
Not less than as soon as supply
When the applying is working usually, or in case of a swish shutdown, the customers can anticipate to see the messages precisely as soon as. Nevertheless, when one thing surprising occurs, duplicate occasions can happen.
In case of an surprising failure in Debezium, the system may not be capable to document the final processed offset. When they’re restarted, the final identified offset will likely be used to find out the beginning place. Comparable occasion duplication could be attributable to community failures.
Which means that whereas duplicate messages is perhaps uncommon, consuming companies must anticipate them when processing the occasions.
At this level, the outbox sample is totally carried out: the OrderService can begin receiving requests, persisting the brand new entities into its native storage and sending occasions to Apache Kafka in a single atomic transaction. Because the CREATE occasions should be detected by Debezium earlier than they’re written to Kafka, this strategy leads to eventual consistency. Which means that the patron companies could lag a bit behind the manufacturing service, which is okay on this use case. It is a tradeoff that must be evaluated when utilizing this sample.
Having Apache Kafka within the core of this resolution additionally permits asynchronous event-driven processing for different microservices. Given the fitting subject retention time, new customers are additionally able to studying from the start of the subject, and constructing a neighborhood state primarily based on the occasion historical past. It additionally makes the structure proof against single element failures: if one thing fails or a service shouldn’t be obtainable for a given period of time, the messages will likely be merely processed later—no must implement retries, circuit breaking, or related reliability patterns.
Strive it out your self!
Software builders can use the Cloudera Information Platform’s Information in Movement options to arrange dependable knowledge trade between distributed companies, and make it possible for the applying state stays constant even beneath excessive load situations. To start out, try how our Cloudera Streams Messaging elements work within the public cloud, and the way simple it’s to arrange a manufacturing prepared workload cluster utilizing our predefined cluster templates.
MySQL CDC with Kafka Join/Debezium in CDP Public Cloud
The utilization of safe Debezium connectors in Cloudera environments
Utilizing Kafka Join Securely within the Cloudera Information Platform