
Not too long ago, we introduced enhanced multi-function analytics help in Cloudera Information Platform (CDP) with Apache Iceberg. Iceberg is a high-performance open desk format for big analytic knowledge units. It permits a number of knowledge processing engines, reminiscent of Flink, NiFi, Spark, Hive, and Impala to entry and analyze knowledge in easy, acquainted SQL tables.
On this weblog submit, we’re going to share with you ways Cloudera Stream Processing (CSP) is built-in with Apache Iceberg and the way you should use the SQL Stream Builder (SSB) interface in CSP to create stateful stream processing jobs utilizing SQL. This permits you to maximise utilization of streaming knowledge at scale. We’ll discover find out how to create catalogs and tables and present examples of find out how to write and browse knowledge from these Iceberg tables. At present, Iceberg help in CSP is in technical preview mode.
The CSP engine is powered by Apache Flink, which is the best-in-class processing engine for stateful streaming pipelines. Let’s check out what options are supported from the Iceberg specification:
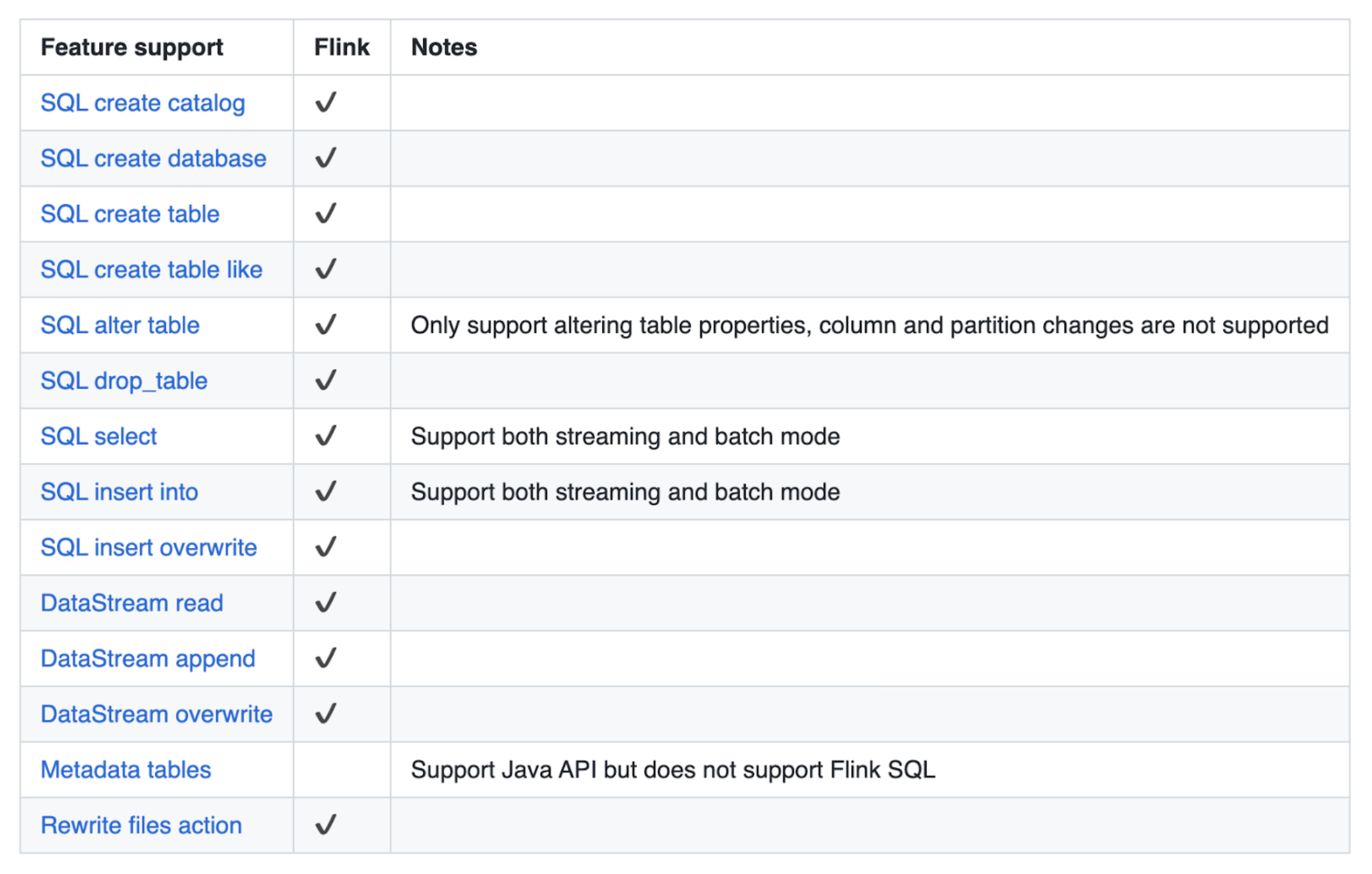
As proven within the desk above, Flink helps a variety of options with the next limitations:
- No DDL help for hidden partitioning
- Altering a desk is barely doable for desk properties (no schema/partition evolution)
- Flink SQL doesn’t help inspecting metadata tables
- No watermark help
CSP at the moment helps the v1 format options however v2 format help is coming quickly.
SQL Stream Builder integration
Hive Metastore
To make use of the Hive Metastore with Iceberg in SSB, step one is to register a Hive catalog, which we are able to do utilizing the UI:
Within the Challenge Explorer open the Information Sources folder and right-click on Catalog, which can deliver up the context menu.
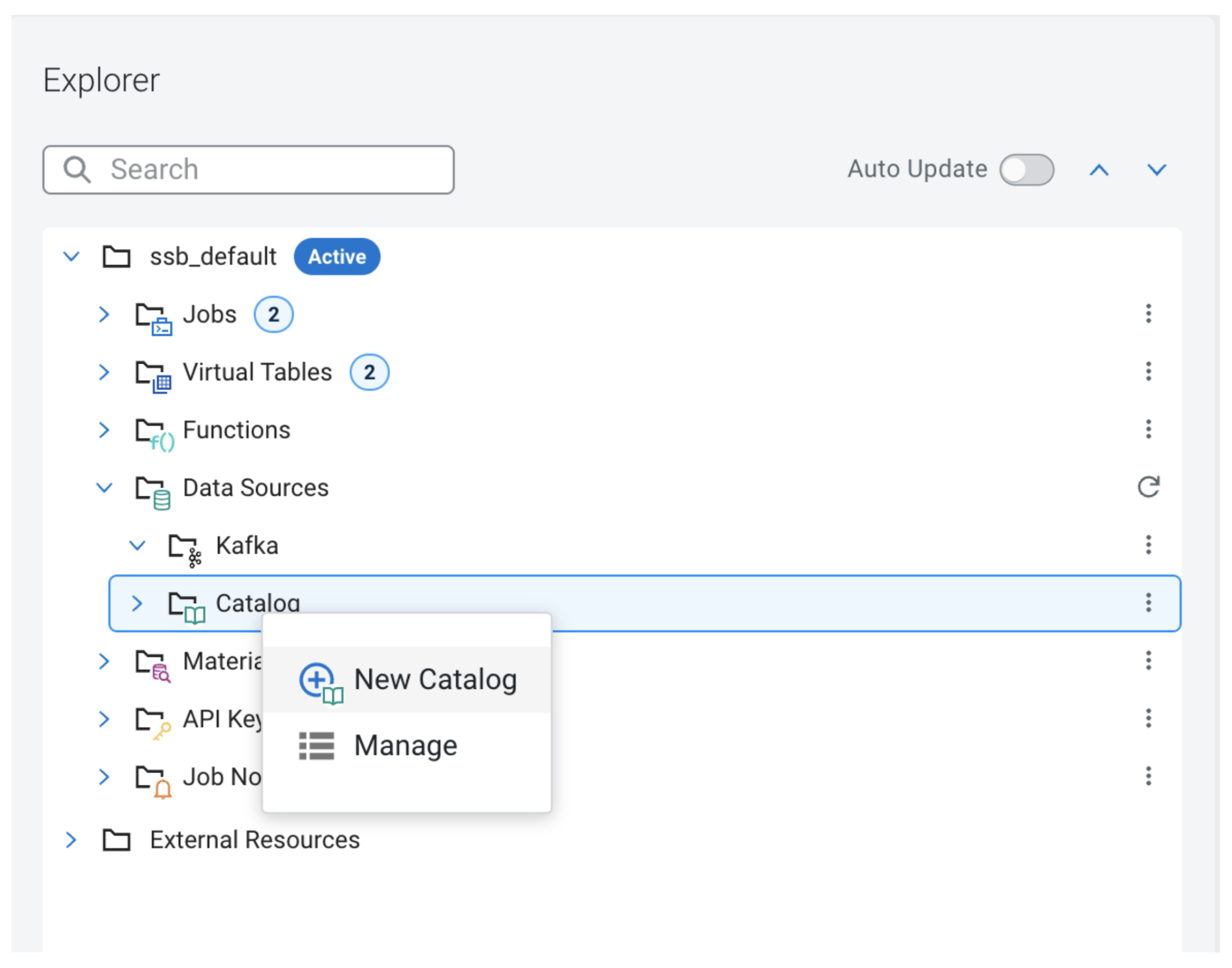
Clicking “New Catalog” will open up the catalog creation modal window.
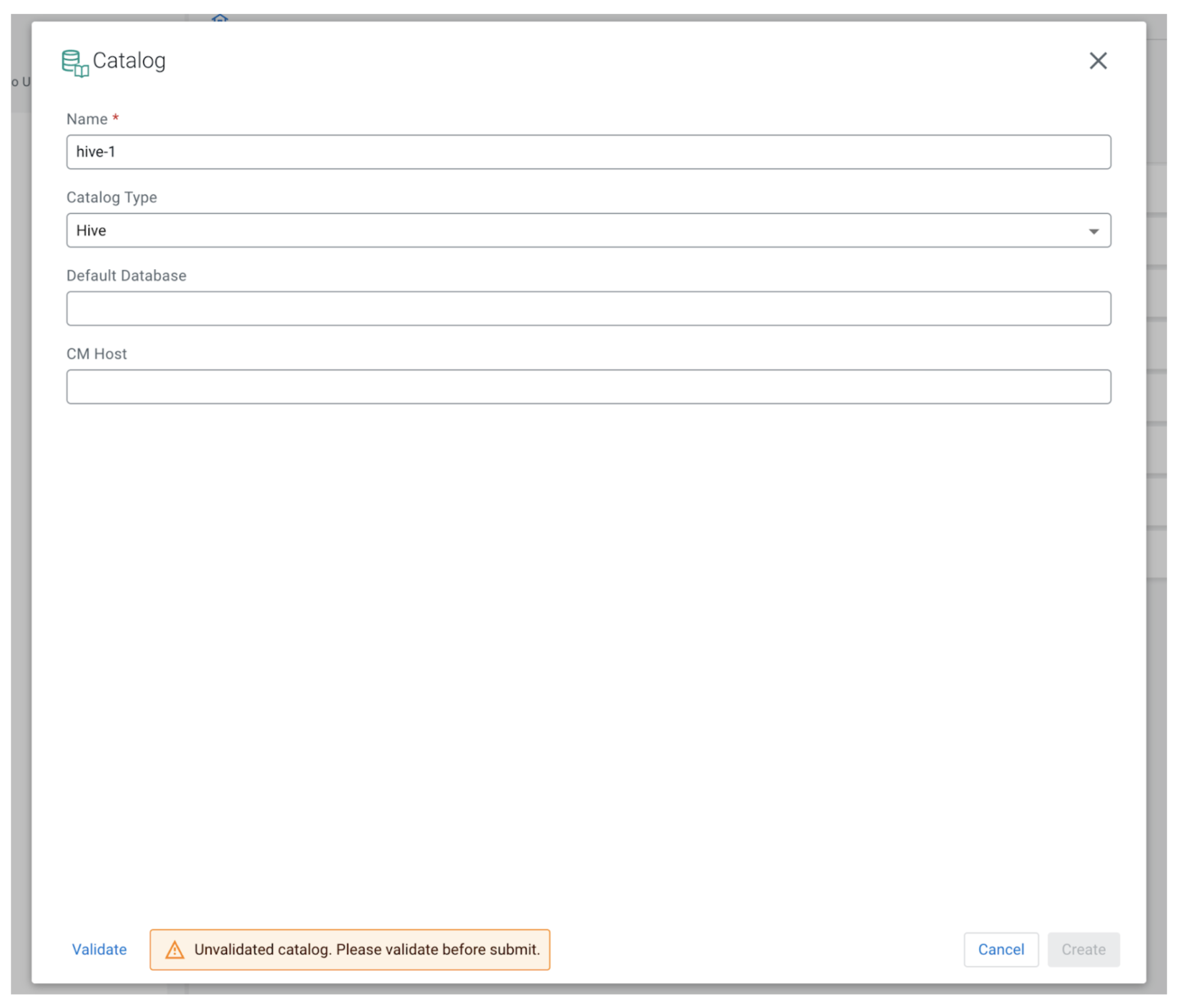
To register a Hive catalog we are able to enter any distinctive title for the catalog in SSB. The Catalog Sort must be set to Hive. The Default Database is an optionally available discipline so we are able to depart it empty for now.
The CM Host discipline is barely obtainable within the CDP Public Cloud model of SSB as a result of the streaming analytics cluster templates don’t embody Hive, so to be able to work with Hive we are going to want one other cluster in the identical surroundings, which makes use of a template that has the Hive element. To offer the CM host we are able to copy the FQDN of the node the place Cloudera Supervisor is operating. This data may be obtained from the Cloudera Administration Console by first deciding on the Information Hub cluster that has Hive put in and belongs to the identical surroundings. Subsequent, go to the Nodes tab:

Search for the node marked “CM Server” on the fitting facet of the desk. After the shape is crammed out, click on Validate after which the Create button to register the brand new catalog.
Within the subsequent instance, we are going to discover find out how to create a desk utilizing the Iceberg connector and Hive Metastore.
Let’s create our new desk:
CREATE TABLE `ssb`.`ssb_default`.`iceberg_hive_example` ( `column_int` INT, `column_str` VARCHAR(2147483647) ) WITH ( 'connector' = 'iceberg', 'catalog-database' = 'default', 'catalog-type' = 'hive', 'catalog-name' = 'hive-catalog', 'ssb-hive-catalog' = 'your-hive-data-source', 'engine.hive.enabled' = 'true' )
As we are able to see within the code snippet, SSB supplies a customized comfort property ssb-hive-catalog to simplify configuring Hive. With out this property, we would wish to know the hive-conf location on the server or the thrift URI and warehouse path. The worth of this property must be the title of the beforehand registered Hive catalog. By offering this feature, SSB will routinely configure all of the required Hive-specific properties, and if it’s an exterior cluster in case of CDP Public Cloud it’ll additionally obtain the Hive configuration information from the opposite cluster. The catalog-database property defines the Iceberg database title within the backend catalog, which by default makes use of the default Flink database (“default_database”). The catalog-name is a user-specified string that’s used internally by the connector when creating the underlying iceberg catalog. This selection is required because the connector doesn’t present a default worth.
After the desk is created we are able to insert and question knowledge utilizing acquainted SQL syntax:
INSERT INTO `iceberg_hive_example` VALUES (1, 'a'); SELECT * FROM `iceberg_hive_example`;
Querying knowledge utilizing Time Journey:
SELECT * FROM `iceberg_hive_example` /*+OPTIONS('as-of-timestamp'='1674475871165')*/;
Or:
SELECT * FROM `iceberg_hive_example` /*+OPTIONS('snapshot-id'='901544054824878350')*/
In streaming mode, we have now the next capabilities obtainable:
We will learn all of the information from the present snapshot, after which learn incremental knowledge ranging from that snapshot:
SELECT * FROM `iceberg_hive_example` /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/
Moreover, we are able to learn all incremental knowledge ranging from the supplied snapshot-id (information from this snapshot will likely be excluded):
SELECT * FROM `iceberg_hive_example` /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
Conclusion
Now we have lined find out how to entry the facility of Apache Iceberg in SQL Stream Builder and its prospects and limitations in Flink. We additionally explored find out how to create and entry Iceberg tables utilizing a Hive catalog and the comfort choices in SSB to facilitate the mixing, so you’ll be able to spend much less time on configuration and focus extra on the information.
Anyone can check out SSB utilizing the Stream Processing Group Version (CSP-CE). CE makes creating stream processors straightforward, out of your desktop or some other improvement node. Analysts, knowledge scientists, and builders can now consider new options, develop SQL-based stream processors regionally utilizing SQL Stream Builder powered by Flink, and develop Kafka Customers/Producers and Kafka Join Connectors, all regionally earlier than shifting to manufacturing in CDP.