Quantization is a way for making machine studying fashions smaller and sooner. We quantize Llama2-70B-Chat, producing an equivalent-quality mannequin that generates 2.2x extra tokens per second.
The bigger the language mannequin, the slower (and costlier) it’s to question: the GPU has to load extra parameters from reminiscence and carry out extra computations. Our group has developed and adopted quite a few methods to optimize LLM efficiency. On this weblog put up, we’ll focus on quantization, a well-liked approach that lowers the numerical precision of a mannequin with the intention to cut back its reminiscence footprint and make it run sooner. Making use of quantization to LLMs equivalent to Llama2-70B-Chat results in a mannequin that generates 2.2 occasions extra tokens per second than when operating at full 16-bit precision. Critically, to make sure that the mannequin high quality is maintained, we rigorously check the quantized mannequin on dozens of benchmarks in our Gauntlet mannequin analysis suite.
A Temporary Primer on Quantization
Fashionable LLMs are largely skilled utilizing 16-bit precision. As soon as the mannequin is skilled, practitioners typically quantize mannequin weights to a decrease precision, decreasing the variety of bits required to retailer the mannequin or run computations, which hurries up inference. We will quantize a number of of the parts of the mannequin:
- Mannequin parameters (i.e. the weights).
- Key-value (KV) cache. That is the state related to the eye keys and values, that are saved to scale back repetitive computations as we generate output tokens sequentially.
- Activations. These are the outputs of every layer of the mannequin, that are used as inputs to the subsequent layer. Once we quantize the activations, we’re performing the precise computation (like matrix multiplications) with a decrease precision.
Quantization produces a smaller and sooner mannequin. Decreasing the dimensions of the mannequin permits us to make use of much less GPU reminiscence and/or enhance the utmost batch measurement. A smaller mannequin additionally reduces the bandwidth required to maneuver weights from reminiscence. That is particularly vital at low batch sizes, after we are bandwidth-bound—in low batch settings, there are a small variety of operations per byte of the mannequin loaded, so we’re bottlenecked by the dimensions of the mannequin weights. As well as, if we quantize the activations, we will make the most of {hardware} assist for quick low-precision operations: NVIDIA A100 and H100 Tensor Core GPUs can carry out 8-bit integer (INT8) math 2x sooner than 16-bit floating level math. The H100 Tensor Core GPU options the Transformer Engine, which helps 8-bit floating level (FP8) operations on the identical pace as 8-bit integer operations. To learn extra about challenges in LLM inference, please discuss with our earlier weblog on this matter.
On this work, we focus on two completely different quantization setups:
- INT8 weights + KV cache quantization. On this setup, our mannequin weights and KV cache are diminished, however our activations stay in 16 bits.
- FP8. Our weights, KV cache, and activations are all diminished to 8-bit floating level values. Eight-bit floating level operations are solely supported by NVIDIA H100 Tensor Core GPUs, and never by NVIDIA A100 Tensor Core GPUs.
Integer vs. Floating Level Quantization
What’s the distinction between INT8 and FP8?
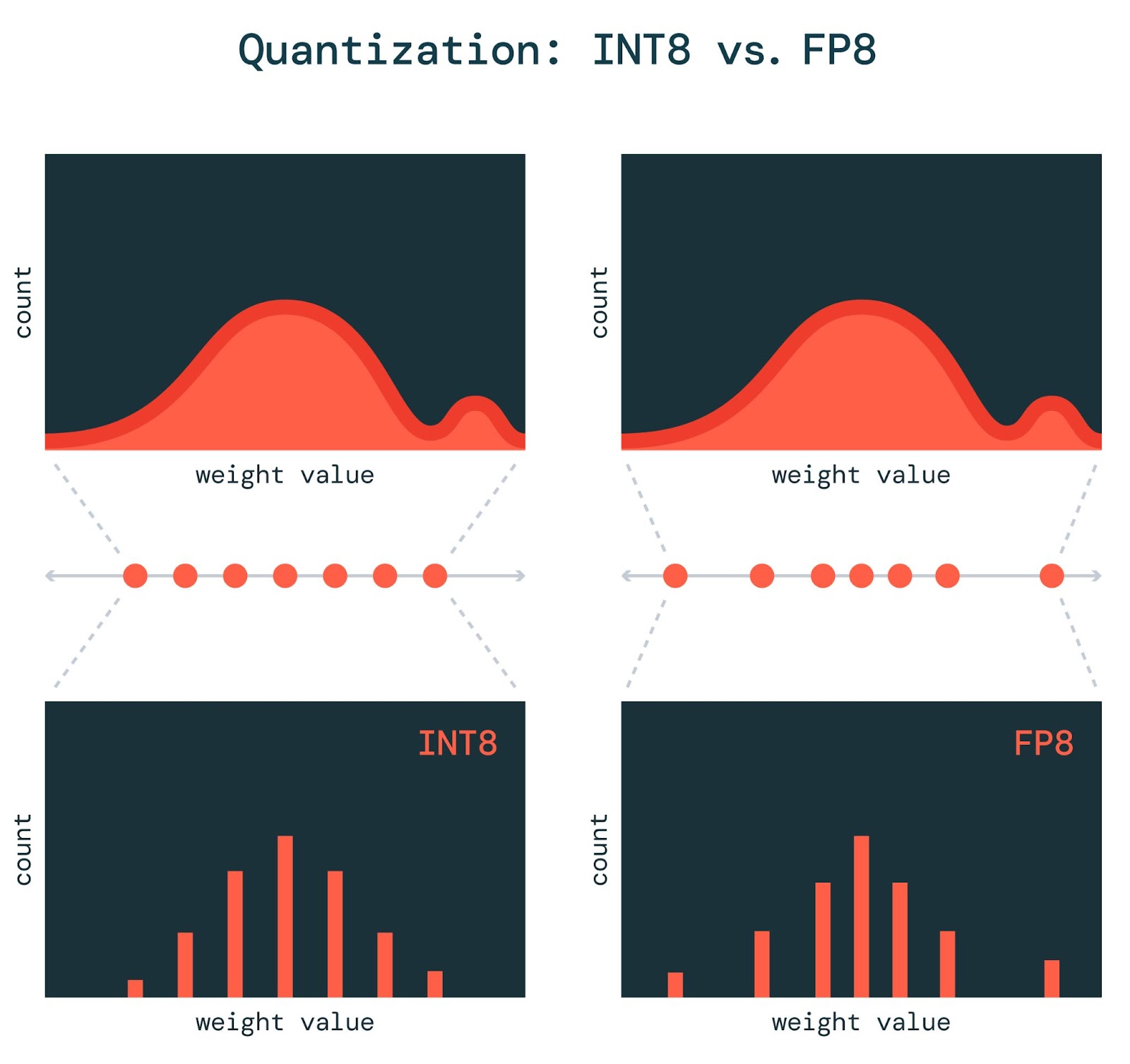
Determine 1: In comparison with integer quantization, FP8 quantization produces smaller errors for weights close to the center of our distribution. It is because integer quantity codecs symbolize a uniform distribution of numbers, whereas floating-point numbers symbolize an influence legislation distribution. Floating-point codecs even have bigger dynamic vary, in order that they introduce smaller errors in outliers.
In INT8 quantization, we multiply our mannequin’s parameters by a scaling issue, shift them up or down so they’re centered round zero, after which spherical these values to one of many 256 integers representable by the INT8 format. This rounding induces errors, so the much less we now have to spherical our parameters, the higher the quantized mannequin’s high quality. However the distribution of integers is uniform, so INT8 quantization works finest when our mannequin parameters and activations are additionally uniformly distributed.
Sadly, our weights and activations are not often uniformly distributed. They normally look extra like a bell curve, so FP8 quantization may fit higher. Floating level quantity codecs can symbolize a non-uniform distribution; as a result of we use some bits for the mantissa and a few for the exponent, we will set our exponent to be destructive after we wish to symbolize numbers near zero with excessive precision.
Latest analysis has proven that outlier weights and activations—numbers far-off from typical values—are particularly vital for mannequin high quality. As a result of FP8 has an exponent element, it might probably symbolize very giant numbers with much less error than INT8. Due to this fact, quantization to FP8 tends to supply extra correct fashions than INT8.
Activations are inclined to comprise extra outliers than weights. So, to protect mannequin high quality with INT8, we solely quantize our weights and KV cache to INT8, leaving our activations in FP16 for now. Different methods, equivalent to SmoothQuant, get across the problems with outliers with INT8 quantization.
Quantizing Llama2-70B-Chat
Llama2-70B-Chat is at the moment one of many largest and highest high quality fashions supplied by way of our Basis Mannequin API. Sadly, that additionally implies that it’s slower and provides extra restricted concurrency than smaller fashions. Let’s see if quantization may also help!
We use the NVIDIA TensorRT-LLM library to quantize and serve our optimized Llama2-70B-Chat mannequin. We discover that we will quantize Llama2-70B-Chat and obtain:
(a) A 50% smaller mannequin, decreasing GPU reminiscence necessities and permitting us to suit a 2x bigger batch measurement on the identical {hardware}.
(b) As much as 30% sooner output token technology.
(c) The identical high quality, on common, as the unique Llama2-70B-Chat mannequin.
In sum, utilizing FP8 quantization, we will enhance our total mannequin throughput by 2.2x!
Pace
Quantization’s biggest profit is that it unlocks larger concurrency, as a result of it permits us to double the utmost batch measurement that may match on the identical {hardware} whereas sustaining the identical latency price range. At batch measurement 64 on the H100 utilizing FP8, we will generate 2.2x extra tokens per second in comparison with batch measurement 32 utilizing FP16, due to a ten% discount in time per output token per person (TPOT).
Even when growing concurrency will not be an possibility, quantization supplies some advantages. TPOT and throughput are ~30% higher for quantized fashions at batch sizes < 8. Above that time, INT8 weight-only quantization supplies little to no speedup as a result of our computation stays in FP16. Nevertheless, for the reason that H100 makes use of the Transformer Engine to carry out sooner FP8 computation, even at excessive batch sizes it maintains a ten% TPOT enchancment versus FP16.
What about processing the immediate? Throughout prefill, we course of your complete context without delay, so we’re usually compute certain. Quicker FP8 operations on the H100 present a 30% time-to-first-token (TTFT) enchancment over FP16. Nevertheless, INT8 weight-only quantization is definitely slower than no quantization right here as a result of our computation stays in FP16, and we now have the extra overhead of changing between information varieties.
Lastly, we examine GPU varieties. We see that TPOT is 25-30% higher for the H100 vs. the A100 on the identical batch measurement and precision (i.e., each operating INT8 or FP16). If we examine the quickest H100 mode, FP8, to the quickest A100 mode, INT8 (weights and KV cache), this hole will increase to 80% at giant batch sizes. Nevertheless, for the reason that H100 has 67% extra bandwidth and 3x extra compute than the A100, this distinction may enhance sooner or later, as software program and kernels for the H100 grow to be extra optimized. As of proper now, it seems the H100 has extra efficiency headroom than the A100. Our outcomes present that mannequin bandwidth utilization, a measure of how effectively information strikes from reminiscence to the compute components, ranges from 2% – 7% larger on the A100 vs. the H100 throughout output token technology.
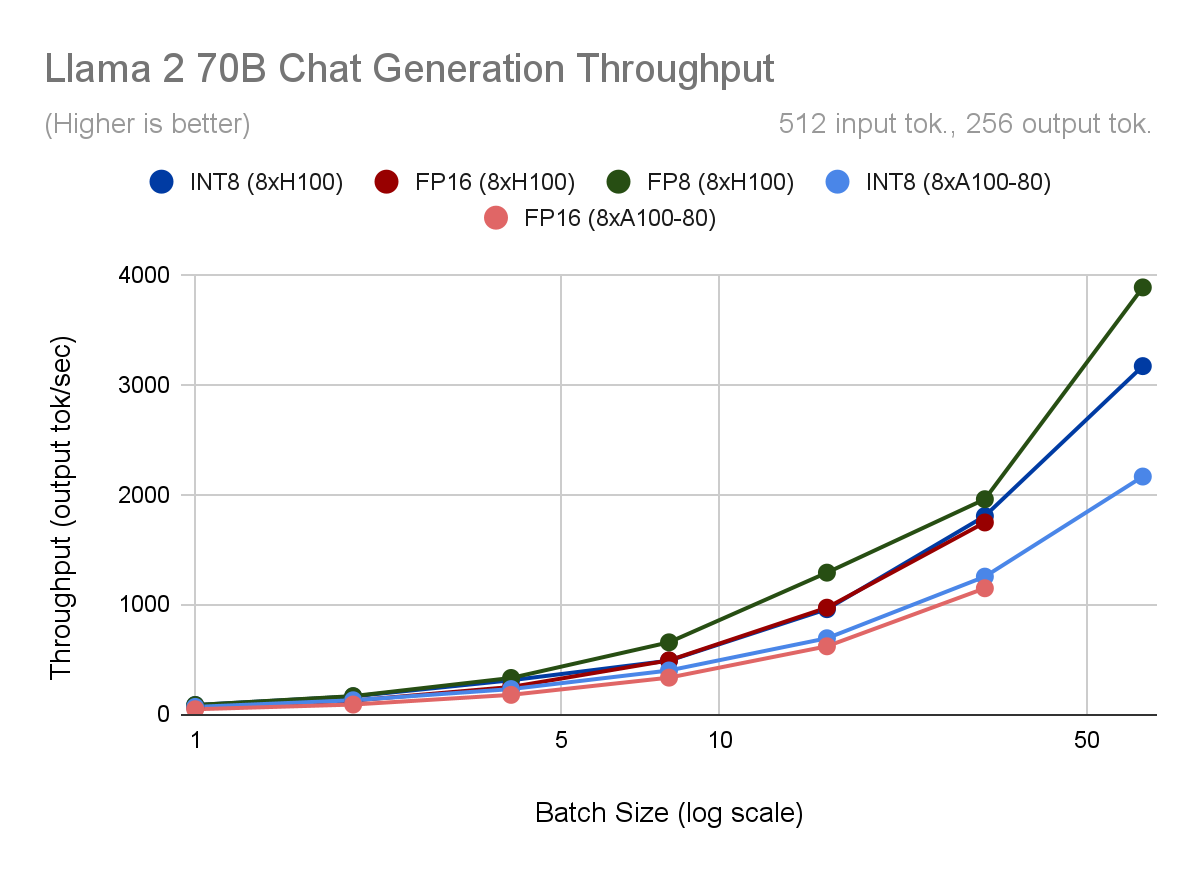
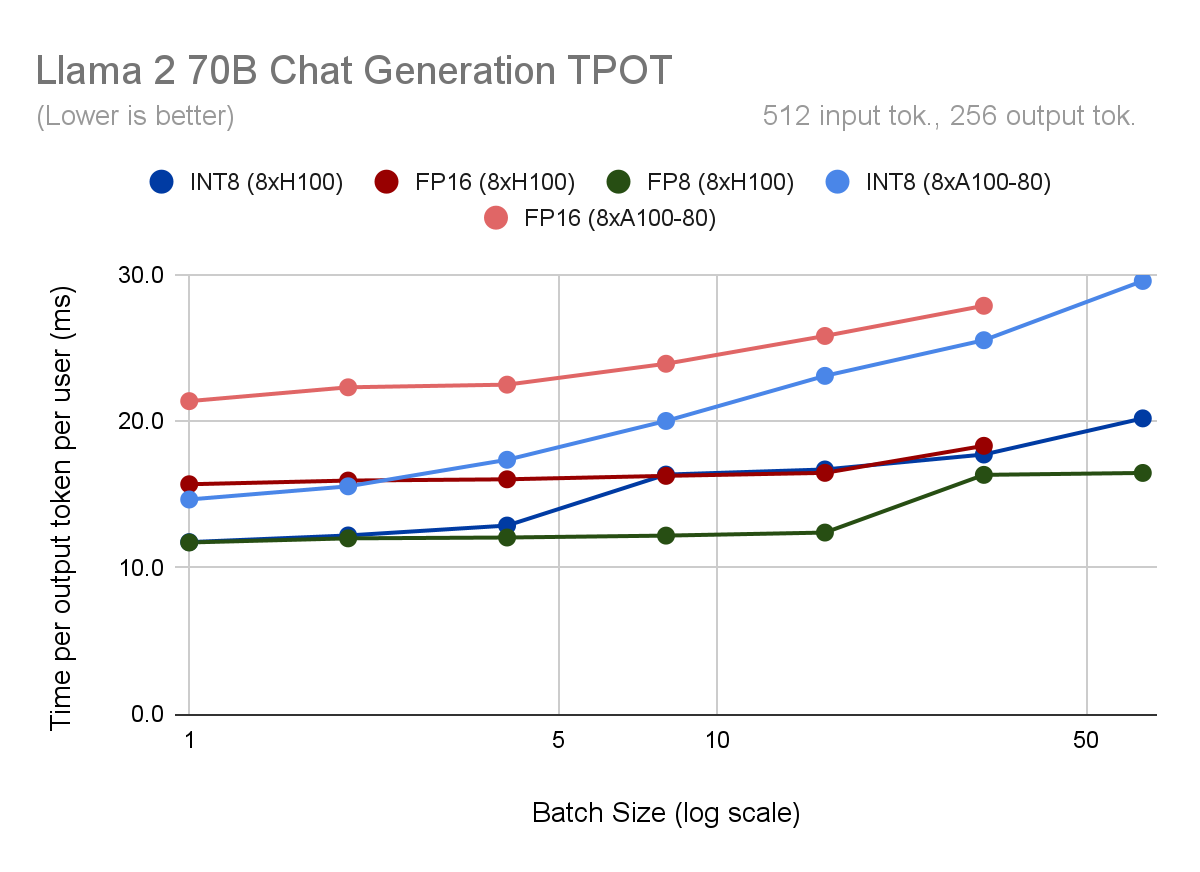
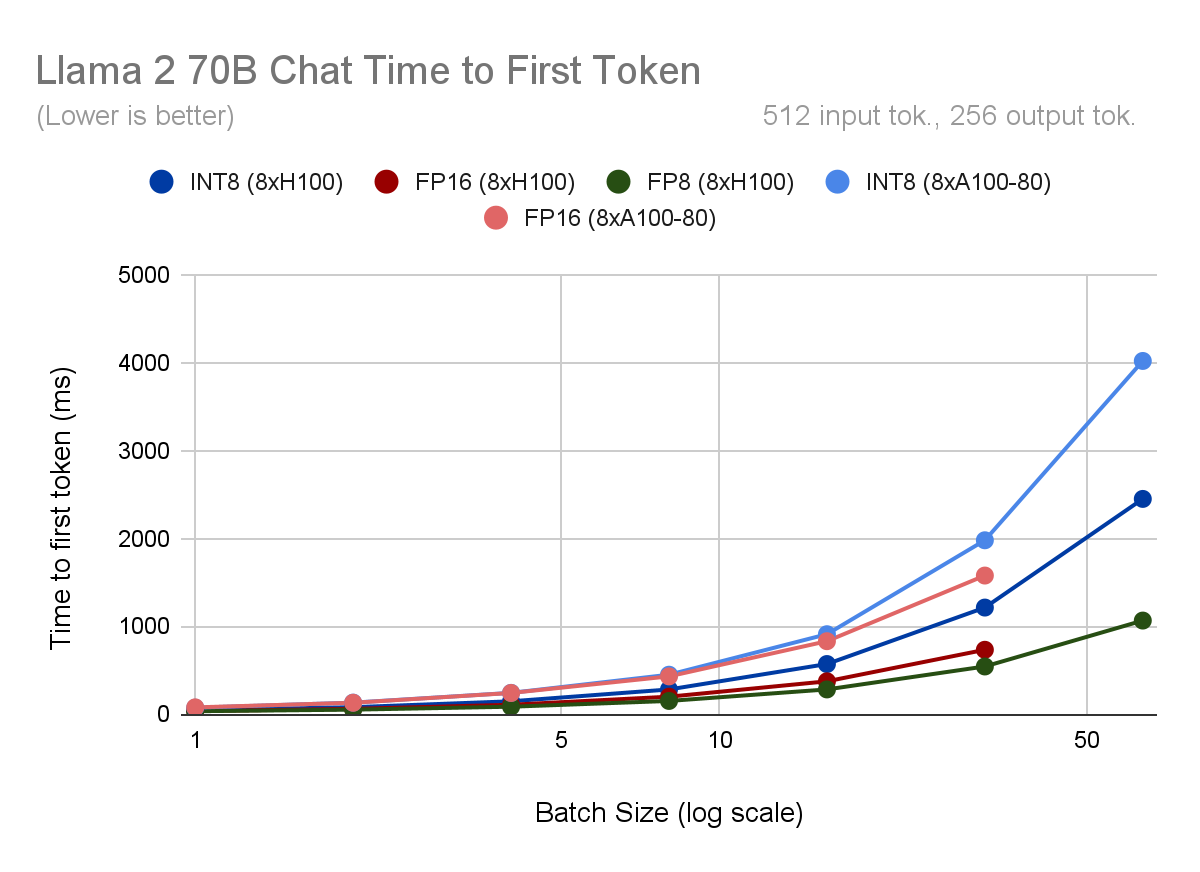
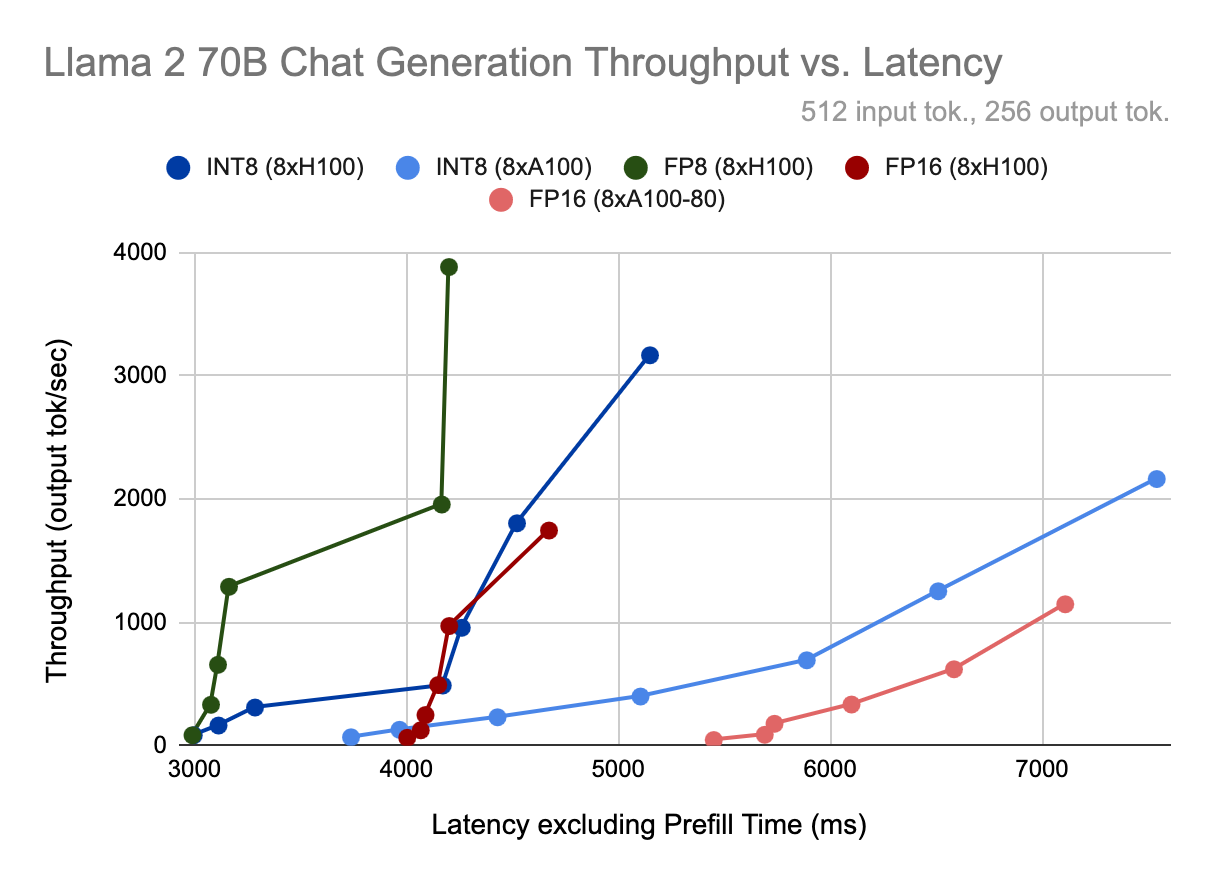
Determine 2. For every Llama2-70B-Chat quantization mode and {hardware} configuration, we plot (high) mannequin throughput, measured in output tokens per second, (second) time per output token per person (TPOT), (third) time to first token, and (backside) output throughput vs. latency.
High quality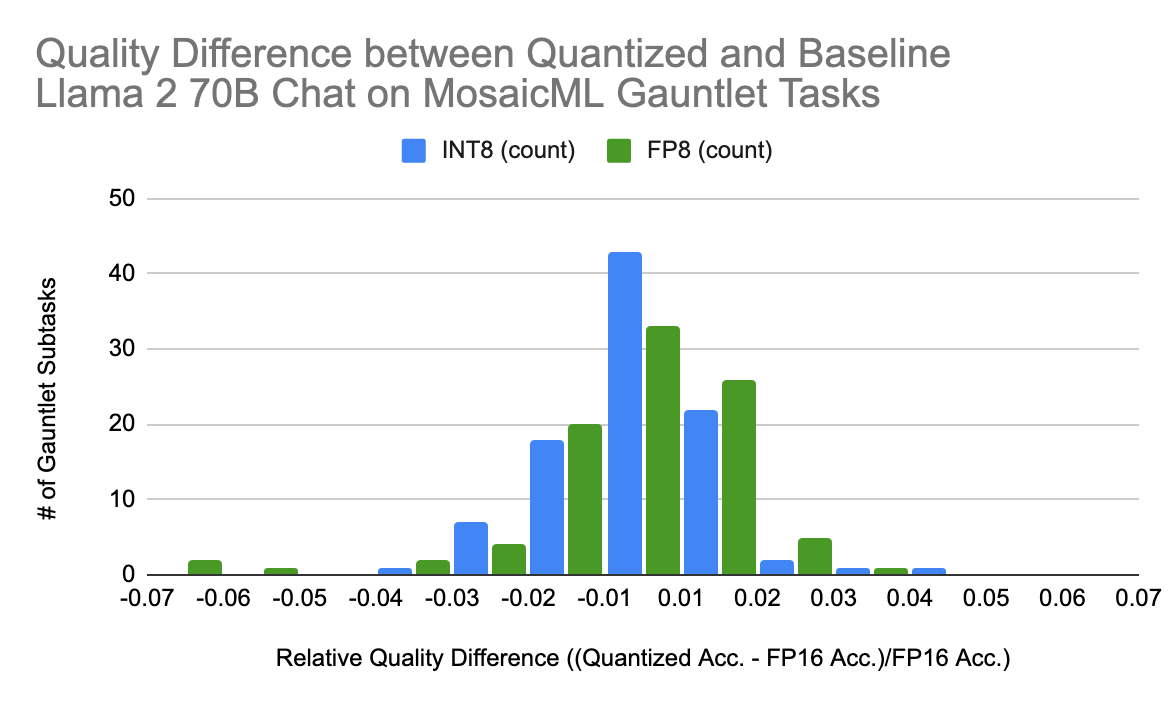
Determine 3. For each INT8 and FP8 Llama fashions, the accuracy distinction from the baseline mannequin on our LLM Analysis Gauntlet subtasks is an roughly regular distribution, centered near zero.
Quantizing fashions can have an effect on mannequin high quality. We’ve developed our MosaicML Gauntlet Analysis suite to check the standard of our fashions on a big selection of various duties. Our suite consists of dozens of industry-standard benchmarks, together with MMLU, BigBench, Arc, and HellaSwag. These benchmarks comprise many alternative courses of issues, together with world information, commonsense reasoning, language understanding, symbolic drawback fixing, and studying comprehension.
We carry out an intensive analysis on our quantized Llama2-70B-Chat fashions utilizing the Gauntlet and discover no vital accuracy distinction between both quantization mode and our baseline mannequin. In Determine 3, we present the standard distinction between every quantization sort and the baseline Llama2-70B-Chat on the Gauntlet subtasks. On common, there isn’t any high quality distinction between the quantized and baseline fashions, and the quantized fashions are inside +/- 2% of the baseline efficiency for the overwhelming majority of duties.
Conclusion
Quantization is a robust approach that may considerably enhance mannequin pace and throughput. At low batch sizes, each INT8-weight-only and FP8 supply related advantages. Nevertheless, for top throughput use-cases, FP8 quantization on NVIDIA’s H100s supplies probably the most advantages.
Our engineering group is at all times cautious to keep up mannequin high quality after we introduce a speedup, and quantization isn’t any completely different. Our Gauntlet analysis suite exhibits that on common, Llama2-70B-Chat maintains its unique high quality after both FP8 or INT8 quantization.
We’ll quickly be serving quantized Llama2-70B-Chat by way of our Basis Mannequin APIs, with all of the efficiency advantages described above. You’ll be able to rapidly get began querying the mannequin and pay per token, and in case you require concurrency ensures in your manufacturing workload, you possibly can deploy Basis Mannequin APIs with Provisioned Throughput. Study extra right here.
We’re continually working to make the fashions we serve sooner whereas sustaining high quality outcomes. Keep tuned for extra optimizations!