
In April 2023 we introduced the discharge of Databricks ARC to allow easy, automated linking of knowledge inside a single desk. Immediately we announce an enhancement which permits ARC to search out hyperlinks between 2 totally different tables, utilizing the identical open, scalable, and easy framework. Information linking is a standard problem throughout Authorities – Splink, developed by the UK Ministry of Justice and which acts because the linking engine inside ARC, exists to supply a robust, open, and explainable entity decision package deal.
Linking knowledge is normally a easy process – there’s a frequent area or fields between two totally different tables which give a direct hyperlink between them. The Nationwide Insurance coverage quantity can be an instance of this – two data which have the identical NI quantity needs to be the identical individual. However how do you hyperlink knowledge with out these frequent fields? Or when the information high quality is poor? Simply because the NI quantity is similar, doesn’t suggest somebody did not make a mistake when writing it down. It’s in these instances that we enter the realm of probabilistic knowledge linking, or fuzzy matching. Beneath illustrates a case the place we will hyperlink 2 tables to create a extra full view, however do not have a standard key on which to hyperlink:


Clearly, these tables comprise details about the identical folks – one in every of them is present, the opposite historic. With no frequent area between the 2 although, how might one programmatically decide the best way to hyperlink the present with historic knowledge?
Historically, fixing this drawback has relied on laborious coded guidelines painstakingly handwritten over time by a gaggle of knowledgeable builders. Within the above case, easy guidelines akin to evaluating the beginning years and first names will work, however this method doesn’t scale when there are various totally different attributes throughout tens of millions of data. What inevitably occurs is the event of impenetrably complicated code with tons of or hundreds of distinctive guidelines, perpetually rising as new edge instances are discovered. This ends in a brittle, laborious to scale, even tougher to alter programs. When the first maintainers of those programs depart, organisations are then left with a black field system representing appreciable danger and technical debt.
Probabilistic linking programs use statistical similarities between data as the premise for his or her determination making. As machine studying (ML) programs, they don’t depend on guide specs of when two data are comparable sufficient however as an alternative study the place the similarity threshold is from the information. Supervised ML programs study these thresholds through the use of examples of data which can be the identical (Apple & Aple) and people who aren’t (Apple & Orange) to outline a normal algorithm which could be utilized to document pairs the mannequin hasn’t seen earlier than (Apple & Pear). Unsupervised programs would not have this requirement and as an alternative have a look at simply the underlying document similarities. ARC simplifies this unsupervised method by making use of requirements and heuristics to take away the necessity to manually outline guidelines, as an alternative choosing utilizing a looser ruleset and letting the computer systems do the laborious work of determining which guidelines are good.
Linking 2 datasets with ARC requires just some line of code:


This picture highlights how ARC has linked (artificial!) data collectively regardless of typos and transpositions – in line 1, the given title and surnames not solely have typos however have additionally been column swapped.
The place linking with ARC will help
Automated, low effort linking with ARC creates quite a lot of alternatives:
- Scale back the time to worth and price of migrations and integrations.
- Problem: Each mature system inevitably has duplicate knowledge. Sustaining these datasets and their pipelines creates pointless price and danger from having a number of copies of comparable knowledge; for instance unsecured copies of PII knowledge.
- How ARC helps: ARC can be utilized to routinely quantify the similarity between tables. Because of this duplicate knowledge and pipelines could be recognized sooner and at decrease price, leading to a faster time to worth when integrating new programs or migrating outdated ones.
- Allow interdepartmental and inter-government collaboration.
- Problem: There’s a expertise problem in sharing knowledge between nationwide, devolved and native authorities which hinders the power for all areas of presidency to make use of knowledge for the general public good. The power to share knowledge throughout the COVID-19 pandemic was essential to the federal government’s response, and knowledge sharing is a thread working by means of the 5 missions of the 2020 UK Nationwide Information Technique.
- How ARC helps: ARC democratises knowledge linking by reducing the abilities barrier – in case you can write python, you can begin linking knowledge. What’s extra, ARC can be utilized to ease the educational curve of Splink, the highly effective linking engine beneath the hood, permitting budding knowledge linkers to be productive immediately while studying the complexity of a brand new instrument.
- Hyperlink knowledge with fashions tailor-made to the information’s traits.
- Problem: Time consuming, costly linking fashions create an incentive to attempt to construct fashions able to generalising throughout many alternative profiles of knowledge. It’s a truism {that a} normal mannequin will likely be outperformed by a specialist mannequin, however the realities of mannequin coaching usually stop the coaching of a mannequin per linking venture.
- How ARC helps: ARC’s automation signifies that specialised fashions educated to hyperlink a selected set of knowledge could be deployed at scale, with minimal human interplay. This drastically lowers the barrier for knowledge linking initiatives.
The addition of automated knowledge linking to ARC is a vital contribution to the realm of entity decision and knowledge integration. By connecting datasets with no frequent key, the general public sector can harness the true energy of their knowledge, drive inner innovation and modernisation, and higher serve their residents. You may get began immediately by attempting the instance notebooks which could be cloned into your Databricks Repo from the ARC GitHub repository. ARC is a totally open supply venture, out there on PyPi to be pip put in, requiring no prior knowledge linking or entity decision to get began.
Accuracy – to hyperlink, or to not hyperlink
The perennial problem of knowledge linking in the actual world is accuracy – how have you learnt in case you appropriately recognized each hyperlink? This isn’t the identical as each hyperlink you might have made being appropriate – you might have missed some. The one strategy to totally assess a linkage mannequin is to have a reference knowledge set, one the place each document hyperlink is thought prematurely. This implies we will then evaluate the expected hyperlinks from the mannequin in opposition to the recognized hyperlinks to calculate accuracy measures.
There are three frequent methods of measuring the accuracy of a linkage mannequin: Precision, Recall and F1-score.
- Precision: what quantity of your predicted hyperlinks are appropriate?
- Recall: what quantity of whole hyperlinks did your mannequin discover?
- F1-score: a blended metric of precision and recall which provides extra weight to decrease values. This implies to attain a excessive F1-score, a mannequin should have good precision and recall, quite than excelling in a single and middling within the different.
Nonetheless, these metrics are solely relevant when one has entry to a set of labels displaying the true hyperlinks – within the overwhelming majority of instances, these labels don’t exist, and creating them is a labor intensive process. This poses a conundrum – we need to work with out labels the place potential to decrease the price of knowledge linking, however with out labels we will not objectively consider our linking fashions.
With a view to consider ARCs efficiency we used FEBRL to create an artificial knowledge set of 130,000 data which comprises 30,000 duplicates. This was cut up into 2 recordsdata – the 100,000 clear data, and 30,000 data which must be linked with them. We use the unsupervised metric beforehand mentioned when linking the two knowledge units collectively. We examined our speculation by optimizing solely for our metric over a 100 runs for every knowledge set above, and individually calculating the F1 rating of the predictions, with out together with it within the optimization course of. The chart under exhibits the connection between our metric on the horizontal axis versus the empirical F1 rating on the vertical axis.
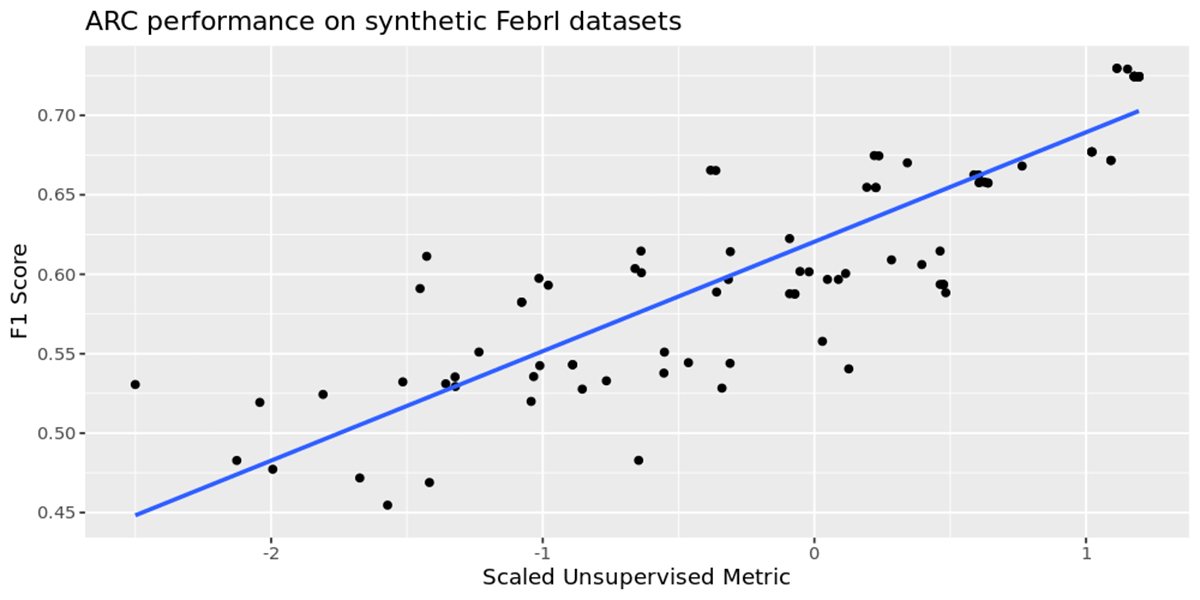
We observe a optimistic correlation between the 2, indicating that by growing our metric of the expected clusters by means of hyperparameter optimization will result in the next accuracy mannequin. This permits ARC to reach at a robust baseline mannequin over time with out the necessity to present it with any labeled knowledge. This offers a robust knowledge level to counsel that maximizing our metric within the absence of labeled knowledge is an efficient proxy for proper knowledge linking.
You may get began linking knowledge immediately ARC by merely working the instance notebooks after cloning the ARC GitHub repository into your Databricks Repo. This repo contains pattern knowledge in addition to code, giving a walkthrough of the best way to hyperlink 2 totally different datasets, or deduplicate one dataset, all with just some traces of a code. ARC is a totally open supply venture, out there on PyPi to be pip put in, requiring no prior knowledge linking or entity decision expertise to get began.
Technical Appendix – how does Arc work?
For an in-depth overview of how Arc works, the metric we optimise for and the way the optimisation is finished please go to the documentation at https://databricks-industry-solutions.github.io/auto-data-linkage/.
You may get began linking knowledge immediately ARC by merely working the instance notebooks after cloning the ARC GitHub repository into your Databricks Repo. This repo contains pattern knowledge in addition to code, giving a walkthrough of the best way to hyperlink 2 totally different datasets, or deduplicate one dataset, all with just some traces of a code. ARC is a totally open supply venture, out there on PyPi to be pip put in, requiring no prior knowledge linking or entity decision expertise to get began.