{kind=link}

(Tee11/Shutterstock)
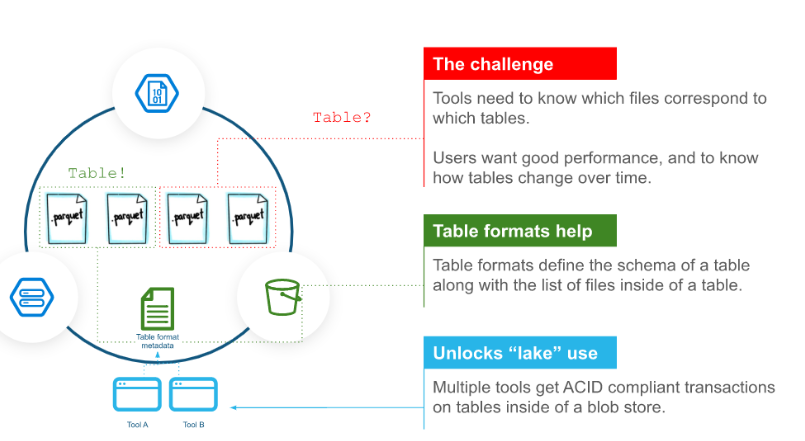
One of many large breakthroughs in information engineering over the previous seven to eight years is the emergence of desk codecs. Sometimes layered atop column-oriented Parquet information, desk codecs like Apache Iceberg, Delta, and Apache Hudi present vital advantages to large information operations, such because the introduction of transactions. Nonetheless, the desk codecs additionally introduce new prices, which clients ought to concentrate on.
Every of the three main desk codecs was developed by a unique group, which makes their origin tales distinctive. Nonetheless, they have been developed largely in response to the identical kind of technical limitations with the large information established order, which impacts enterprise operations of every kind.
As an illustration, Apache Hudi initially was created in 2016 by the info engineering workforce at Uber, which was a giant consumer (and in addition a giant developer) of massive information tech. Hudi, which stands for Hadoop Upserts, Deletes, and Incrementals, got here from a need to enhance the file dealing with of its huge Hadoop information lakes.
Apache Iceberg, in the meantime, emerged in 2017 from Netflix, additionally a giant consumer of massive information tech. Engineers on the firm grew pissed off with the restrictions within the Apache Hive metastore, which may probably result in corruption when the identical file was accessed by totally different question engines, probably resulting in incorrect solutions.

Picture supply: Apache Software program Basis
Equally, the oldsters at Databricks developed Delta in 2017 when too many information lakes become information swamps. As a key element of Databricks’ Delta Lake, the Delta desk format enabled customers to get information warehousing-like high quality and accuracy for information saved in S3 or HDFS information lakes–or a lakehouse, in different phrases.
As an information engineering automation supplier, Nexla works with all three desk codecs. As its shoppers’ large information repositories develop, they’ve discovered a necessity for higher administration of knowledge for analytic use instances.
The large profit that each one desk codecs carry is the aptitude to see how data have modified over time, which is a function that has been widespread in transactional use instances for many years and is pretty new to analytical use instances, says Avinash Shahdadpuri, the CTO and co-founder of Nexla.
“Parquet as a format didn’t actually have any kind of historical past,” he tells Datanami in an interview. “If I’ve a report and I needed to see how this report has modified over a time frame in two variations of a Parquet file, it was very, very laborious to do this.”
The addition of recent metadata layers inside the desk codecs permits customers to achieve ACID transaction visibility on information saved in Parquet information, which have turn into the predominant format for storing columnar information in S3 and HDFS information lakes (with ORC and Avro being the opposite large information codecs).
“That’s the place a bit little bit of ACID comes into play, is you’re capable of roll again extra reliably as a result of now you had a historical past of how this report has modified over a time frame,” Shahdadpuri says. “You’re now capable of basically model your information.”
Picture supply: Snowflake
This functionality to rollback information to an earlier model is useful particularly conditions, equivalent to for an information set that’s regularly being up to date. It’s not very best in instances the place new information is being appended to the top of the file.
“For those who’re in case your information is not only append, which might be 95% of use instances in these traditional Parquet information, then this tends to be higher since you’re capable of delete, merge and replace a lot better than what you’ll have been capable of do with the traditional Parquet file,” Shahdadpuri says.
Desk codecs enable customers to do extra manipulation of knowledge instantly on the info lake, just like a database. That saves the shopper from the time and expense of pulling the info out of the lake, manipulating it, after which placing it again within the lake, Shahdadpuri says.
Customers may simply depart the info in a database, after all, however conventional databases can’t scale into the petabytes. Distributed file techniques like HDFS and object shops like S3 can simply scale into the petabyte realm. And with the addition of a desk format, the consumer doesn’t should compromise on transactionality and accuracy.
That’s to not say there are not any downsides. There are at all times tradeoffs in pc architectures, and desk codecs do carry their very own distinctive prices. Based on Shahdadpuri, the prices come within the type of elevated storage and complexity.

Picture supply: Databricks
On the storage entrance, the metadata saved by the desk format can add as little as a ten p.c storage overhead, all the best way as much as a 2x penalty for information that’s regularly altering, Shahdadpuri says.
“Your storage prices can enhance fairly a bit, as a result of earlier you have been simply storing Parquet. Now you’re storing variations of Parquet,” he says. “Now you’re storing your meta information in opposition to what you already had with Parquet. In order that additionally will increase your prices, so you find yourself having to make that commerce off.
Prospects ought to ask themselves in the event that they really want the extra options that desk codecs carry. In the event that they don’t want transactionality and the time-travel performance that ACID brings, say as a result of their information is predominantly append-only, then they could be higher off sticking with plain previous Parquet, he says.
“Utilizing this extra layer positively provides complexity, and it provides complexity in a bunch of various methods,” Shahdadpuri says. “So Delta generally is a little extra efficiency heavy than Parquet. All of those codecs are a bit bit efficiency heavy. However you pay the associated fee someplace, proper?”
There isn’t any single greatest desk format, says. As an alternative, one of the best format emerges after analyzing the precise wants of every shopper. “It depends upon the shopper. It depends upon the use case,” Shahdadpuri says. “We wish to be unbiased. As an answer, we’d help every of this stuff.”
With that stated, the oldsters at Nexla have noticed sure traits in desk format adoption. The large issue is how clients have aligned themselves with reference to the large information behemoths: Databricks vs. Snowflake.
Because the creator of Delta, Databricks is firmly in that camp, whereas Snowflake has come out in help of Iceberg. Hudi doesn’t have the help of a serious large information participant, though it’s backed by the startup Onehouse, which was based by Vinoth Chandar, the creator of Hudi. Iceberg is backed by Tabular, which was co-founded by Ryan Blue, who helped created Iceberg at Netflix.
Large corporations will most likely find yourself with a mixture of totally different desk codecs, Shahdadpuri says. That leaves room for corporations like Nexla to come back in and supply instruments to automate the combination of those codecs, or for consultancies to manually sew them collectively.
Associated Objects:
Large Information File Codecs Demystified
Open Desk Codecs Sq. Off in Lakehouse Information Smackdown
The Information Lakehouse Is On the Horizon, However It’s Not Clean Crusing But
acid, ACID transactions, Apache Hudi, Apache Iceberg, large information, information administration, Delta, Delta Lake, Delta Desk format, Hadoop, rollback, s3, desk codecs