{kind=link}
Introduction
Apache Spark™ Structured Streaming is a well-liked open-source stream processing platform that gives scalability and fault tolerance, constructed on prime of the Spark SQL engine. Most incremental and streaming workloads on the Databricks Lakehouse Platform are powered by Structured Streaming, together with Delta Stay Tables and Auto Loader. We’ve got seen exponential development in Structured Streaming utilization and adoption for a various set of use instances throughout all industries over the previous few years. Over 14 million Structured Streaming jobs run per week on Databricks, with that quantity rising at a charge of greater than 2x per 12 months.
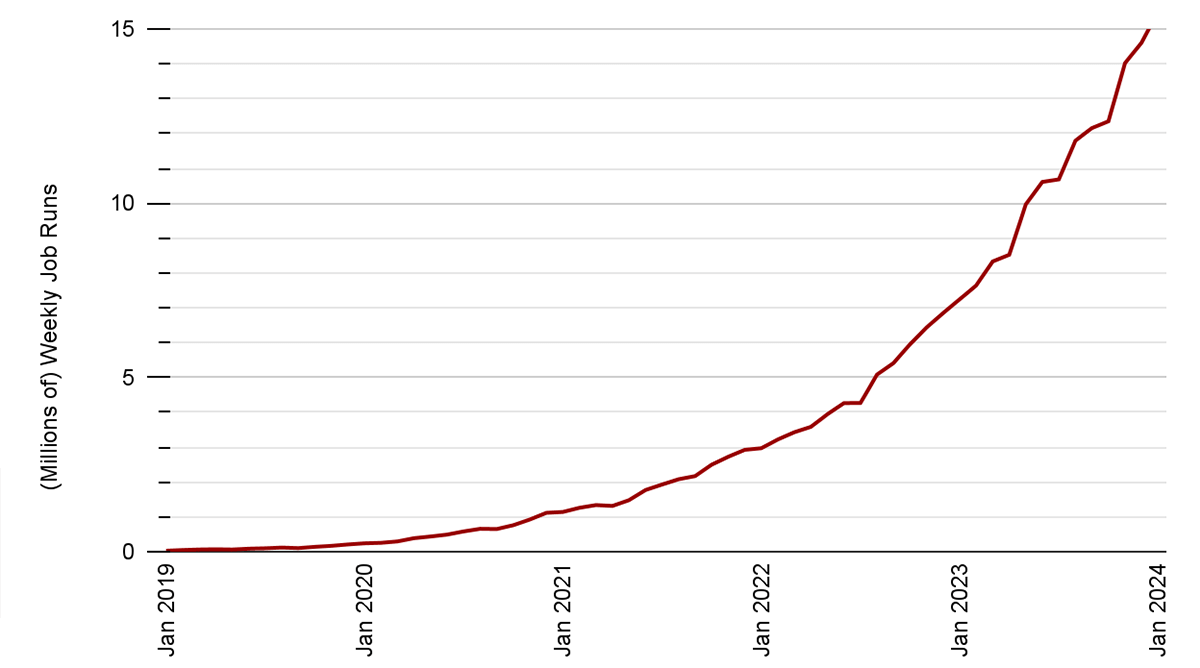
Most Structured Streaming workloads may be divided into two broad classes: analytical and operational workloads. Operational workloads run crucial components of a enterprise in real-time. In contrast to analytical processing, operational processing emphasizes well timed transformations and actions on the information. Operational processing structure allows organizations to shortly course of incoming knowledge, make operational choices, and set off fast actions primarily based on the real-time insights derived from the information.
For such operational workloads, constant low latency is a key requirement. On this weblog, we’ll deal with the efficiency enhancements Databricks has carried out as a part of Undertaking Lightspeed that may assist obtain this requirement for stateful pipelines utilizing Structured Streaming.
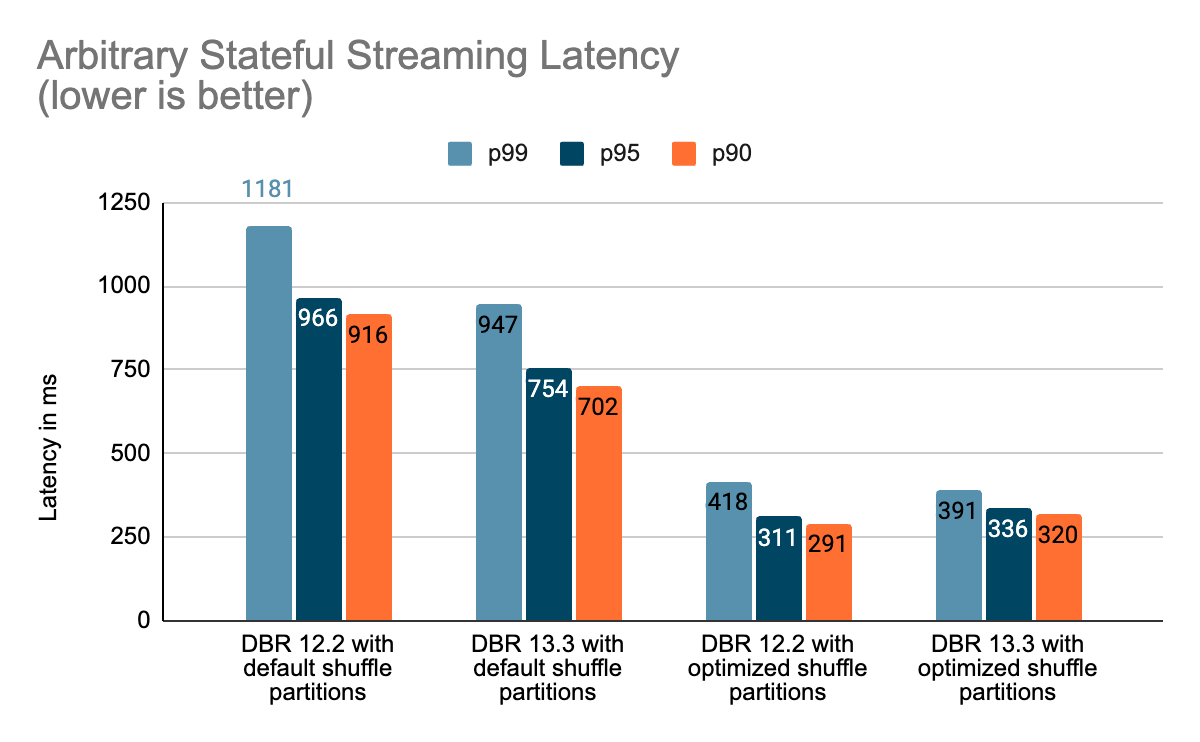
Our efficiency analysis signifies that these enhancements can enhance the stateful pipeline latency by as much as 3–4x for workloads with a throughput of 100k+ occasions/sec working on Databricks Runtime 13.3 LTS onward. These refinements open the doorways for a bigger number of workloads with very tight latency SLAs.
This weblog is in two components – this weblog, Half 1, delves into the efficiency enhancements and features and Half 2 supplies a complete deep dive and superior insights of how we achieved these efficiency enhancements.
Observe that this weblog publish assumes the reader has a fundamental understanding of Apache Spark Structured Streaming.
Background
Stream processing may be broadly labeled into stateless and stateful classes:
- Stateless pipelines normally require every micro-batch to be processed independently with out remembering any context between micro-batches. Examples embody streaming ETL pipelines that remodel knowledge on a per-record foundation (e.g., filtering, branching, mapping, or iterating).
- Stateful pipelines typically contain aggregating info throughout data that seem in a number of micro-batches (e.g., computing a mean over a time window). To finish such operations, these pipelines want to recollect knowledge that they’ve seen throughout micro-batches, and this state must be resilient throughout pipeline restarts.
Stateful streaming pipelines are used largely for real-time use instances similar to product and content material suggestions, fraud detection, service well being monitoring, and so forth.
What Are State and State Administration?
State within the context of Apache Spark queries is the intermediate persistent context maintained between micro-batches of a streaming pipeline as a group of keyed state shops. The state retailer is a versioned key-value retailer offering each learn and write operations. In Structured Streaming, we use the state retailer supplier abstraction to implement the stateful operations. There are two built-in state retailer supplier implementations:
- The HDFS-backed state retailer supplier shops all of the state knowledge within the executors’ JVM reminiscence and is backed by recordsdata saved persistently in an HDFS-compatible filesystem. All updates to the shop are executed in units transactionally, and every set of updates increments the shop’s model. These variations can be utilized to re-execute the updates on the proper model of the shop and regenerate the shop model if wanted. Since all updates are saved in reminiscence, this supplier can periodically run into out-of-memory points and rubbish assortment pauses.
- The RocksDB state retailer supplier maintains state inside RocksDB cases, one per Spark partition on every executor node. On this case, the state can be periodically backed as much as a distributed filesystem and can be utilized for loading a particular state model.
Databricks recommends utilizing the RocksDB state retailer supplier for manufacturing workloads as, over time, it’s common for the state measurement to develop to exceed thousands and thousands of keys. Utilizing this supplier avoids the dangers of working into JVM heap-related reminiscence points or slowness because of rubbish assortment generally related to the HDFS state retailer supplier.
Benchmarks
We created a set of benchmarks to grasp higher the efficiency of stateful streaming pipelines and the consequences of our enhancements. We generated knowledge from a supply at a continuing throughput for testing functions. The generated data contained details about when the data had been created. For all stateful streaming benchmarks, we tracked end-to-end latency on a per-record foundation. On the sink aspect, we used the Apache DataSketches library to gather the distinction between the time every document was written to the sink and the timestamp generated by the supply. This knowledge was used to calculate the latency in milliseconds.
For the Kafka benchmark, we put aside some cluster nodes for working Kafka and producing the information for feeding to Kafka. We calculated the latency of a document solely after the document had been efficiently revealed to Kafka (on the sink). All of the exams had been run with RocksDB because the state retailer supplier for stateful streaming queries.
All exams beneath ran on i3.2xlarge cases in AWS with 8 cores and 61 GB RAM. Exams ran with one driver and 5 employee nodes, utilizing DBR 12.2 (with out the enhancements) as the bottom picture and DBR 13.3 LTS (which incorporates all of the enhancements) because the take a look at picture.
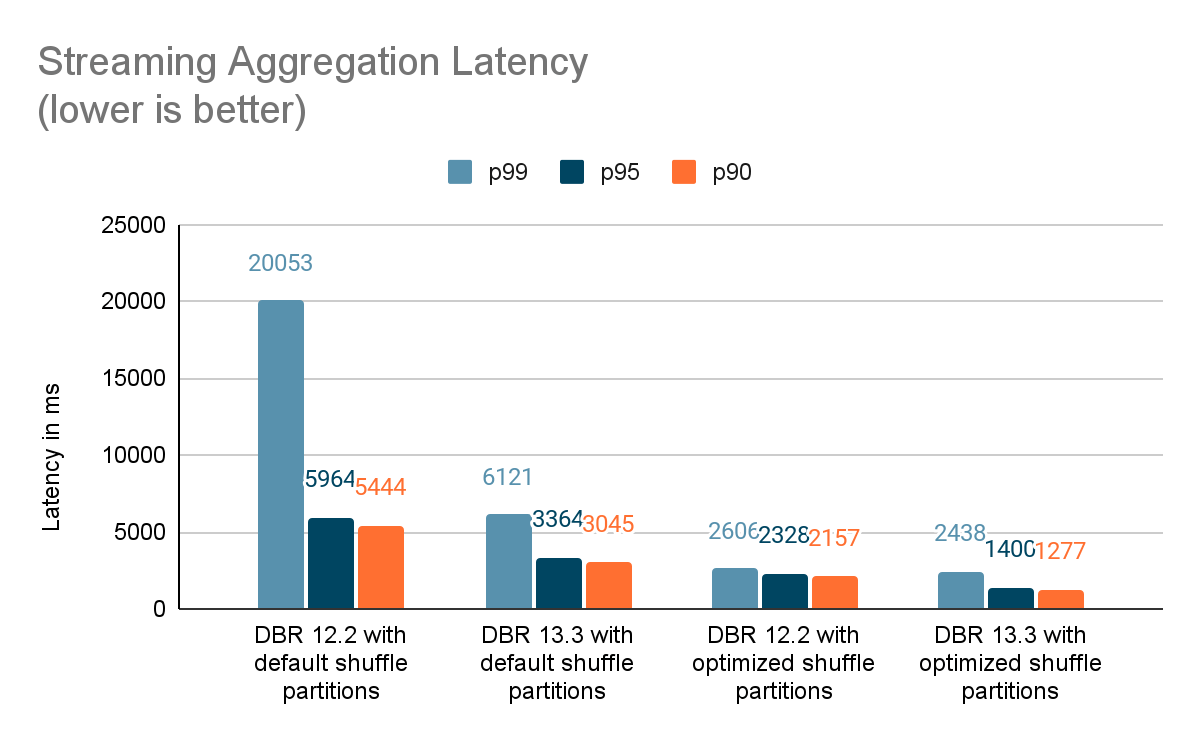
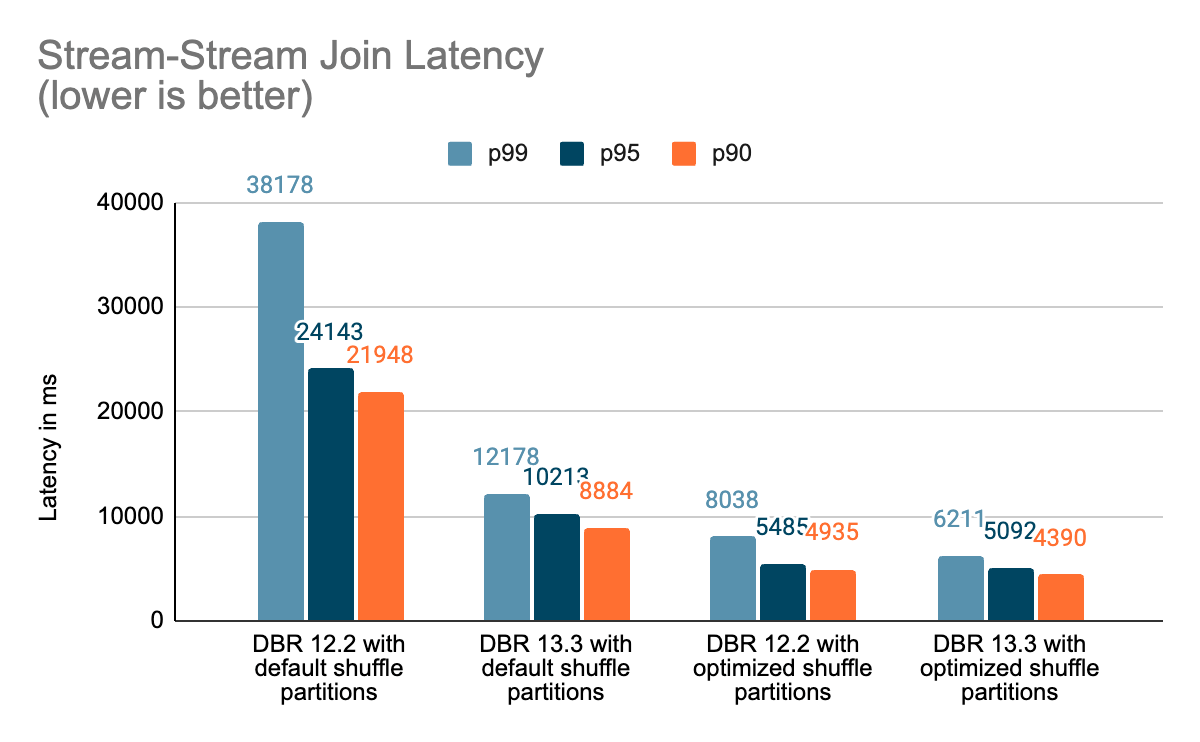
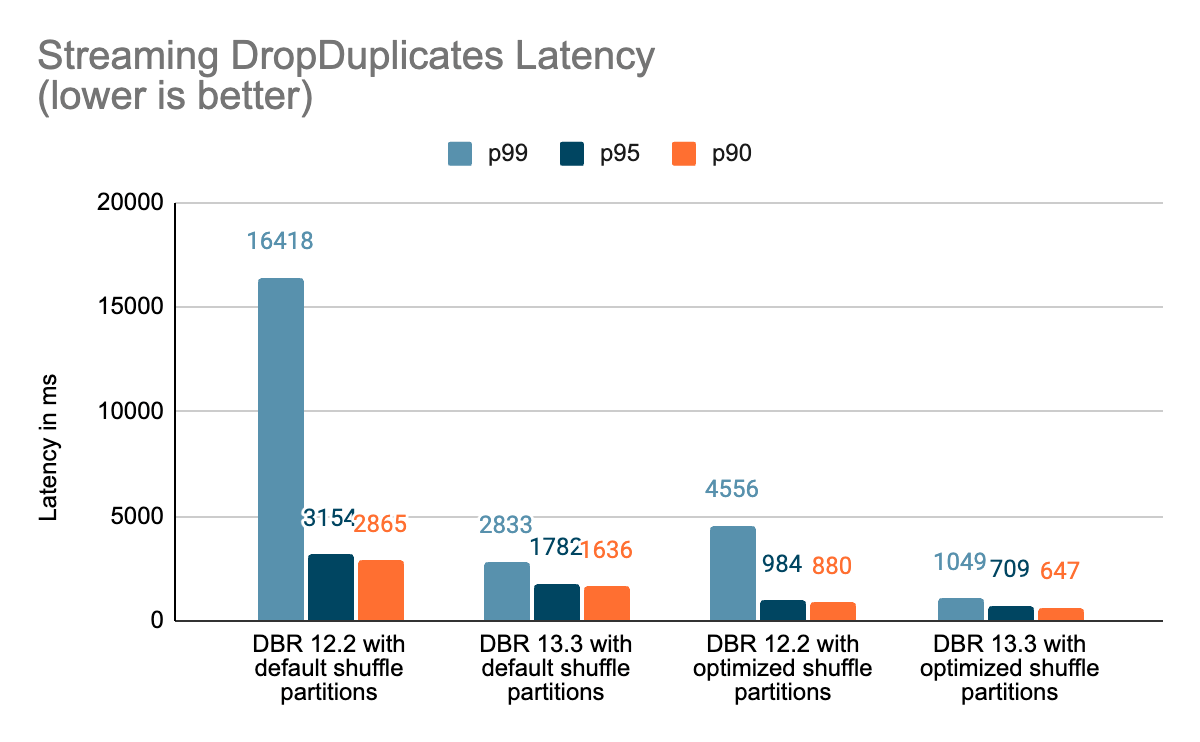
Conclusion
On this weblog, we supplied a high-level overview of the benchmark we have carried out to showcase the efficiency enhancements talked about within the Undertaking Lightspeed replace weblog. Because the benchmarks present, the efficiency enhancements now we have added unlock loads of velocity and worth for purchasers working stateful pipelines utilizing Spark Structured Streaming on Databricks. The added efficiency enhancements to stateful pipelines deserve their very own time for a extra in-depth dialogue, which you’ll be able to look ahead to within the subsequent weblog publish “A Deep Dive Into the Newest Efficiency Enhancements of Stateful Pipelines in Apache Spark Structured Streaming”.
Availability
All of the options talked about above can be found from the DBR 13.3 LTS launch.