{kind=link}
The DataFrame equality take a look at capabilities had been launched in Apache Spark™ 3.5 and Databricks Runtime 14.2 to simplify PySpark unit testing. The complete set of capabilities described on this weblog publish will probably be obtainable beginning with the upcoming Apache Spark 4.0 and Databricks Runtime 14.3.
Write extra assured DataFrame transformations with DataFrame equality take a look at capabilities
Working with information in PySpark entails making use of transformations, aggregations, and manipulations to DataFrames. As transformations accumulate, how are you going to be assured that your code works as anticipated? PySpark equality take a look at utility capabilities present an environment friendly and efficient technique to test your information in opposition to anticipated outcomes, serving to you determine sudden variations and catch errors early within the evaluation course of. What’s extra, they return intuitive info pinpointing exactly the variations so you’ll be able to take motion instantly with out spending a variety of time debugging.
Utilizing DataFrame equality take a look at capabilities
Two equality take a look at capabilities for PySpark DataFrames had been launched in Apache Spark 3.5: assertDataFrameEqual and assertSchemaEqual. Let’s check out learn how to use every of them.
assertDataFrameEqual: This perform means that you can examine two PySpark DataFrames for equality with a single line of code, checking whether or not the info and schemas match. It returns descriptive info when there are variations.
Let’s stroll via an instance. First, we’ll create two DataFrames, deliberately introducing a distinction within the first row:
df_expected = spark.createDataFrame(information=[("Alfred", 1500), ("Alfred", 2500), ("Anna",
500), ("Anna", 3000)], schema=["name", "amount"])
df_actual = spark.createDataFrame(information=[("Alfred", 1200), ("Alfred", 2500), ("Anna", 500),
("Anna", 3000)], schema=["name", "amount"])Then we’ll name assertDataFrameEqual with the 2 DataFrames:
from pyspark.testing import assertDataFrameEqual
assertDataFrameEqual(df_actual, df_expected)The perform returns a descriptive message indicating that the primary row within the two DataFrames is totally different. On this instance, the primary quantities listed for Alfred on this row usually are not the identical (anticipated: 1500, precise: 1200):
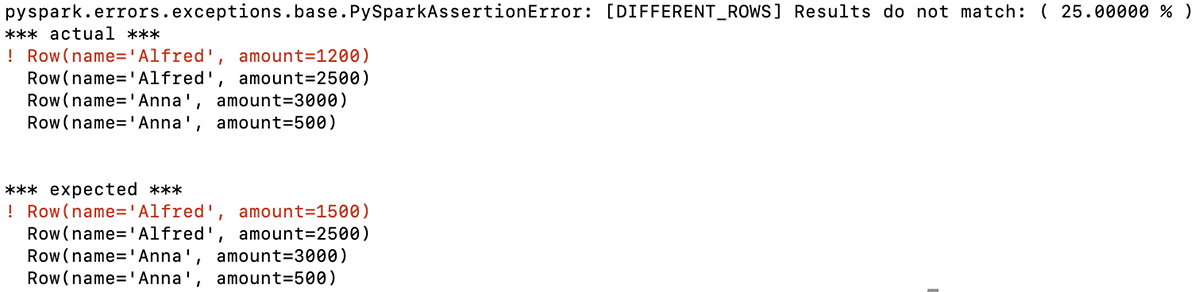
With this info, you instantly know the issue with the DataFrame your code generated and might goal your debugging based mostly on that.
The perform additionally has a number of choices to manage the strictness of the DataFrame comparability as a way to regulate it in line with your particular use circumstances.
assertSchemaEqual: This perform compares solely the schemas of two DataFrames; it doesn’t examine row information. It enables you to validate whether or not the column names, information sorts, and nullable property are the identical for 2 totally different DataFrames.
Let’s take a look at an instance. First, we’ll create two DataFrames with totally different schemas:
schema_actual = "title STRING, quantity DOUBLE"
data_expected = [["Alfred", 1500], ["Alfred", 2500], ["Anna", 500], ["Anna", 3000]]
data_actual = [["Alfred", 1500.0], ["Alfred", 2500.0], ["Anna", 500.0], ["Anna", 3000.0]]
df_expected = spark.createDataFrame(information = data_expected)
df_actual = spark.createDataFrame(information = data_actual, schema = schema_actual)Now, let’s name assertSchemaEqual with these two DataFrame schemas:
from pyspark.testing import assertSchemaEqual
assertSchemaEqual(df_actual.schema, df_expected.schema)The perform determines that the schemas of the 2 DataFrames are totally different, and the output signifies the place they diverge:

On this instance, there are two variations: the info kind of the quantity column is LONG within the precise DataFrame however DOUBLE within the anticipated DataFrame, and since we created the anticipated DataFrame with out specifying a schema, the column names are additionally totally different.
Each of those variations are highlighted within the perform output, as illustrated right here.
assertPandasOnSparkEqual isn’t coated on this weblog publish since it’s deprecated from Apache Spark 3.5.1 and scheduled to be eliminated within the upcoming Apache Spark 4.0.0. For testing Pandas API on Spark, see Pandas API on Spark equality take a look at capabilities.
Structured output for debugging variations in PySpark DataFrames
Whereas the assertDataFrameEqual and assertSchemaEqual capabilities are primarily geared toward unit testing, the place you sometimes use smaller datasets to check your PySpark capabilities, you would possibly use them with DataFrames with greater than only a few rows and columns. In such situations, you’ll be able to simply retrieve the row information for rows which can be totally different to make additional debugging simpler.
Let’s check out how to do this. We’ll use the identical information we used earlier to create two DataFrames:
df_expected = spark.createDataFrame(information=[("Alfred", 1500), ("Alfred", 2500),
("Anna", 500), ("Anna", 3000)], schema=["name", "amount"])
df_actual = spark.createDataFrame(information=[("Alfred", 1200), ("Alfred", 2500), ("Anna",
500), ("Anna", 3000)], schema=["name", "amount"])And now we’ll seize the info that differs between the 2 DataFrames from the assertion error objects after calling assertDataFrameEqual:
from pyspark.testing import assertDataFrameEqual
from pyspark.errors import PySparkAssertionError
strive:
assertDataFrameEqual(df_actual, df_expected, includeDiffRows=True)
besides PySparkAssertionError as e:
# `e.information` right here seems like:
# [(Row(name='Alfred', amount=1200), Row(name='Alfred', amount=1500))]
spark.createDataFrame(e.information, schema=["Actual", "Expected"]).present() Making a DataFrame based mostly on the rows which can be totally different and exhibiting it, as we have completed on this instance, illustrates how straightforward it’s to entry this info:

As you’ll be able to see, info on the rows which can be totally different is instantly obtainable for additional evaluation. You now not have to write down code to extract this info from the precise and anticipated DataFrames for debugging functions.
This characteristic will probably be obtainable from the upcoming Apache Spark 4.0 and DBR 14.3.
Pandas API on Spark equality take a look at capabilities
Along with the capabilities for testing the equality of PySpark DataFrames, Pandas API on Spark customers could have entry to the next DataFrame equality take a look at capabilities:
assert_frame_equalassert_series_equalassert_index_equal
The capabilities present choices for controlling the strictness of comparisons and are nice for unit testing your Pandas API on Spark DataFrames. They supply the very same API because the pandas take a look at utility capabilities, so you need to use them with out altering present pandas take a look at code that you simply wish to run utilizing Pandas API on Spark.
Listed here are a few examples demonstrating the usage of assert_frame_equal with totally different parameters, evaluating Pandas API on Spark DataFrames:
from pyspark.pandas.testing import assert_frame_equal
import pyspark.pandas as ps
# Create two barely totally different Pandas API on Spark DataFrames
df1 = ps.DataFrame({"a": [1, 2, 3], "b": [4.0, 5.0, 6.0]})
df2 = ps.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]}) # 'b' column as integers
# Validate DataFrame equality with strict information kind checking
assert_frame_equal(df1, df2, check_dtype=True)On this instance, the schemas of the 2 DataFrames are totally different. The perform output lists the variations, as proven right here:

We are able to specify that we wish the perform to match column information even when the columns should not have the identical information kind utilizing the check_dtype argument, as on this instance:
# DataFrames are equal with check_dtype=False
assert_frame_equal(df1, df2, check_dtype=False)Since we specified that assert_frame_equal ought to ignore column information sorts, it now considers the 2 DataFrames equal.
These capabilities additionally permit comparisons between Pandas API on Spark objects and pandas objects, facilitating compatibility checks between totally different DataFrame libraries, as illustrated on this instance:
import pandas as pd
# Pandas DataFrame
df_pandas = pd.DataFrame({"a": [1, 2, 3], "b": [4.0, 5.0, 6.0]})
# Evaluating Pandas API on Spark DataFrame with the Pandas DataFrame
assert_frame_equal(df1, df_pandas)
# Evaluating Pandas API on Spark Collection with the Pandas Collection
assert_series_equal(df1.a, df_pandas.a)
# Evaluating Pandas API on Spark Index with the Pandas Index
assert_index_equal(df1.index, df_pandas.index)Utilizing the brand new PySpark DataFrame and Pandas API on Spark equality take a look at capabilities is an effective way to verify your PySpark code works as anticipated. These capabilities enable you to not solely catch errors but additionally perceive precisely what has gone unsuitable, enabling you to rapidly and simply determine the place the issue is. Try the Testing PySpark web page for extra info.
These capabilities will probably be obtainable from the upcoming Apache Spark 4.0. DBR 14.2 already helps it.