{kind=link}

StreamNative, a number one Apache Pulsar-based real-time information platform options supplier, and Databricks, the Information Intelligence Platform, are thrilled to announce the improved Pulsar-Spark Connector.
In an period the place real-time information processing is turning into more and more very important for companies, this collaboration combines the strengths of two highly effective open supply applied sciences: Apache Pulsar™ and Apache Spark™.
Apache Pulsar™
Apache Pulsar™ is an open supply, distributed messaging and occasion streaming platform that provides excessive sturdiness, scalability, and low latency messaging. It is designed to deal with real-time information streaming and can be utilized for numerous functions, from easy pub/sub messaging to advanced event-driven microservices architectures.
Some key options of Apache Pulsar embody:
- Geo-replication: Pulsar permits information to be replicated throughout a number of geographic areas, offering catastrophe restoration and low-latency entry to information.
- Multi-tenancy: It helps multi-tenancy, making it appropriate to be used in cloud environments and shared infrastructures.
- Information Retention and Tiered Storage: Pulsar offers versatile information retention and tiered storage choices, permitting you to optimize storage prices.
- Multi-Protocol help: Pulsar comes with built-in help for traditional messaging protocols resembling Pulsar’s personal binary protocol, MQTT, and Apache Kafka protocol. These built-in protocol handlers facilitate interoperability with a variety of consumer libraries and messaging techniques, making it simpler for builders to combine Pulsar into their present infrastructure.
Apache Spark™
Apache Spark™ is an open supply, distributed computing system that is designed for giant information processing and analytics. With over a billion annual downloads, Spark is thought for its pace and ease of use, offering a unified analytics engine for all large-scale information processing duties.
Key options of Apache Spark embody:
- In-Reminiscence Processing: Spark performs in-memory information processing, considerably accelerating information evaluation in comparison with conventional disk-based processing techniques.
- Ease of Use: It gives high-level APIs in Java, Scala, Python, and SQL, making it accessible to many information professionals.
- Help for Actual-Time Information: Apache Spark’s Structured Streaming allows real-time information processing, permitting companies to research information because it arrives.
Integrating Apache Pulsar™ and Apache Spark™
Companies are nonetheless searching for greater than batch processing and static stories. They demand real-time insights and prompt responses to information because it flows into their techniques. Apache Pulsar and Apache Spark™ have performed pivotal roles on this transformation, however there was a rising must unify the facility of those two applied sciences.
The Pulsar-Spark Connector: Addressing Actual-Time Information Challenges
Seamless Integration
The motivation to develop the Pulsar-Spark Connector stems from the necessity to seamlessly combine the high-speed, low-latency information ingestion capabilities of Apache Pulsar with the superior information processing and analytics capabilities of Apache Spark. This integration empowers organizations to assemble end-to-end information pipelines, guaranteeing information flows easily from ingestion to evaluation, all in real-time.
Scalability and Reliability
Actual-time information processing requires scalability and reliability. Apache Pulsar’s innate capabilities on this regard, mixed with the distributed computing energy of Apache Spark, ship an unmatched resolution that addresses these essential challenges.
Unified Analytics
Companies want a unified analytics platform to research and make selections on real-time information. The Pulsar-Spark Connector paves the way in which for this by providing a seamless resolution to mix the perfect of Apache Pulsar and Apache Spark, leading to speedy insights and data-driven decision-making.
Open Supply Collaboration
Moreover, releasing the Pulsar-Spark Connector as an open-source challenge displays our dedication to transparency, collaboration, and making a thriving neighborhood of customers and contributors.
In abstract, the motivation behind creating the Pulsar-Spark Connector is to offer organizations with a unified, high-performance resolution that seamlessly integrates the pace and scalability of Apache Pulsar with the information processing capabilities of Databricks’ Spark platform. This empowers companies to satisfy the rising calls for for real-time information processing and analytics.
Widespread use circumstances
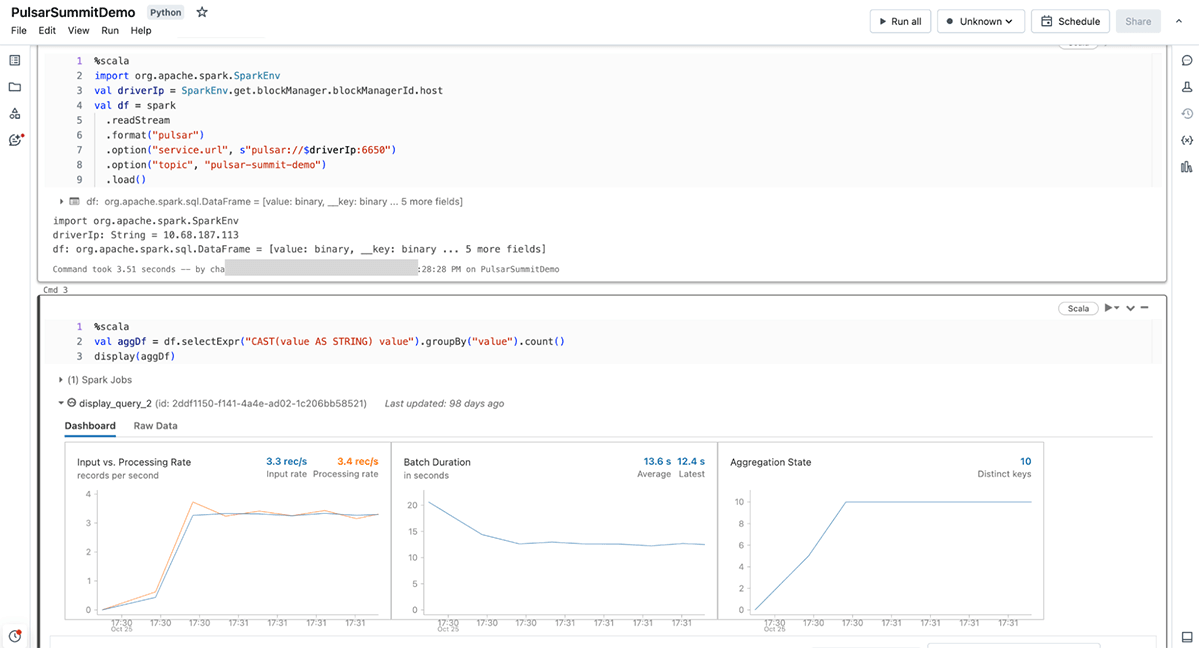
Actual-Time Information Processing and Analytics: Apache Pulsar’s pub-sub messaging system allows the ingestion of large streams of information from various sources in real-time. Spark Structured Streaming offers the potential to course of these information streams with low latency, enabling real-time analytics, monitoring, and alerting. Collectively, Pulsar and Spark can kind the spine of real-time information processing pipelines, permitting organizations to realize insights and take speedy actions on streaming information.
Steady ETL (Extract, Rework, Load): In fashionable information architectures, the necessity for steady ETL processes is paramount. Apache Pulsar facilitates the ingestion of information from numerous sources, whereas Apache Spark offers highly effective transformation capabilities by means of its batch and streaming processing engines. Organizations can leverage Pulsar to ingest information streams and make the most of Spark to carry out real-time transformations, enrichments, and aggregations on the information earlier than loading it into downstream techniques or information shops.
Complicated Occasion Processing (CEP): Complicated Occasion Processing entails figuring out patterns and correlations in streams of occasions or information in real-time. Apache Pulsar’s capacity to deal with high-throughput occasion streams and Spark’s wealthy set of stream processing APIs make them a superb mixture for implementing CEP functions. Organizations can use Pulsar to ingest occasion streams and Spark to research and detect advanced patterns, anomalies, and developments in real-time, enabling proactive decision-making and speedy responses to vital occasions.
Machine Studying on Streaming Information: As organizations more and more undertake machine studying methods for real-time decision-making, the mixing of Apache Pulsar and Apache Spark turns into instrumental. Pulsar allows the ingestion of steady streams of information generated by sensors, IoT units, or software logs, whereas Spark’s MLlib library offers scalable machine studying algorithms that may function on streaming information. Organizations can leverage this mix to construct and deploy real-time machine studying fashions for duties resembling anomaly detection, predictive upkeep, and personalization.
Actual-Time Monitoring and Alerting: Monitoring and alerting techniques require the power to course of and analyze giant volumes of streaming information in real-time. Apache Pulsar can function a dependable messaging spine for accumulating and distributing occasion streams from numerous monitoring sources, whereas Apache Spark can be utilized to research incoming streams, detect anomalies, and set off alerts based mostly on predefined thresholds or patterns. This joint resolution allows organizations to observe their techniques, functions, and infrastructure in real-time, guaranteeing well timed detection and response to potential points or failures.
Key Highlights of the Pulsar-Spark Connector:
- Extremely-Quick Information Ingestion: The Pulsar-Spark Connector allows lightning-fast information ingestion from Apache Pulsar into Databricks’ Apache Spark clusters, permitting organizations to course of real-time information at unprecedented speeds.
- Finish-to-end Information Pipelines: Seamlessly assemble end-to-end information pipelines encompassing all the information lifecycle, from ingestion to processing, evaluation, and visualization.
- Excessive Scalability and Reliability: Profit from the inherent scalability and reliability of Apache Pulsar mixed with the superior information processing capabilities of Databricks’ Spark platform.
- Native Integration: The Pulsar-Spark Connector is designed for seamless integration, making it simpler for information engineers and scientists to work collectively, leveraging the perfect of each platforms.
- Unified Analytics: Analyze real-time information streams with Databricks’ unified analytics platform, permitting for speedy insights and data-driven decision-making.
- Open Supply: The Pulsar-Spark Connector might be launched as an open-source challenge, guaranteeing transparency, collaboration, and a thriving neighborhood of customers and contributors.
Additionally Out there within the Databricks Runtime
The Databricks Information Intelligence Platform is the perfect place to run Apache Spark workloads. It is constructed on lakehouse structure to offer an open, unified basis for all information and governance, and is powered by a Information Intelligence engine that understands the distinctiveness of your information whereas offering high-performance computation and queries for every kind of information customers. Which means that getting information from Pulsar into analytics or machine studying processes might be each easy and environment friendly.
On high of the above advantages highlighted for the connector, Databricks has added some further parts to enhance the standard of life for builders who use Pulsar on the Databricks platform. Beginning with their help in DBR 14.1 (and Delta Stay Tables preview channel), the Databricks engineering workforce has added two key further areas that make utilizing Pulsar easier and simpler, added help in SQL and a better approach to handle credentials information.
- Prolonged Language Help: Databricks prolonged the language help past the already supported Scala/Java and Python APIs to incorporate a
read_pulsarSQL connector. Utilizing every of the completely different flavors gives related choices and aligns with Spark’s Structured Streaming strategies however the SQL syntax is exclusive to the Databricks platform and the syntax itself differs to align with theSTREAMobject. - Credentials Administration Choices: For password authentication Databricks recommends utilizing Secrets and techniques to assist forestall credentials leaks. For TLS authentication you should utilize any of the next location varieties relying in your setting setup.
- Exterior Location
.choice("tlsTrustStorePath", "s3://<credential_path>/truststore.jks")
- DBFS
.choice("tlsTrustStorePath", "dbfs:/<credential_path>/truststore.jks")
- Unity Catalog Quantity
.choice("tlsTrustStorePath", "/Volumes/<catalog>/<schema>/<quantity>/truststore.jks")
In Databricks environments utilizing Unity Catalog, it is very important enable Pulsar customers entry to the credentials file to keep away from permissions errors when studying the stream.
- Exterior areas
GRANT READ FILES ON EXTERNAL LOCATION s3://<credential_path> TO <consumer>
- Unity Catalog Volumes
GRANT READ VOLUME ON VOLUME <catalog.schema.credentials> TO <consumer>
Syntax Examples
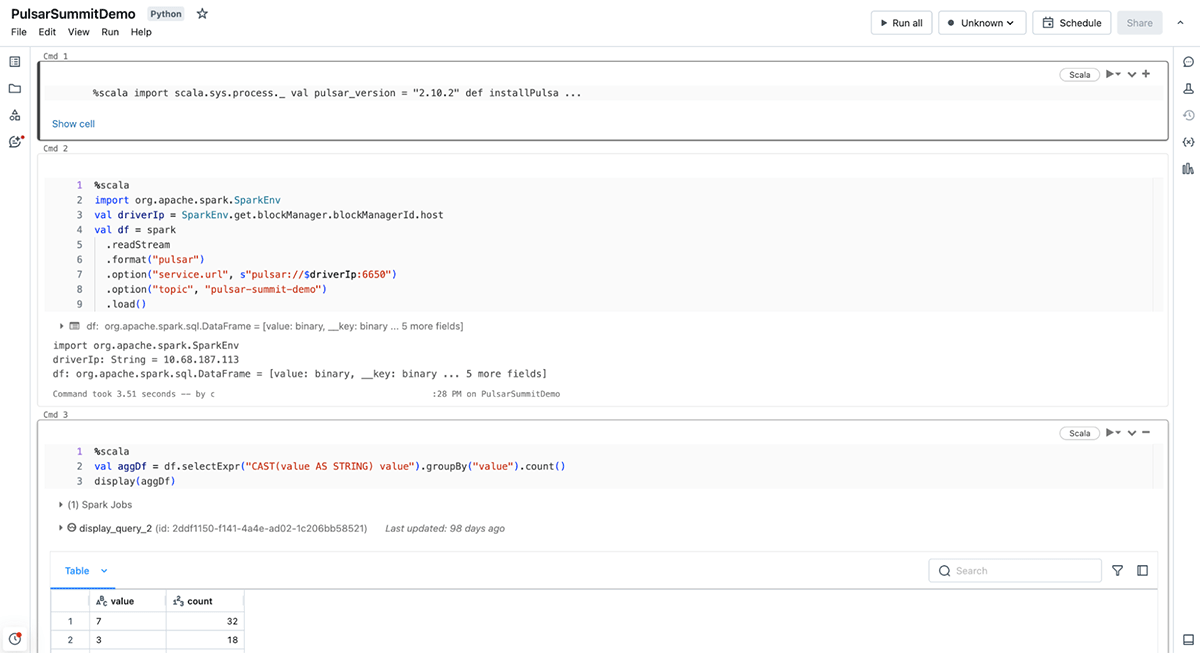
Right here we’ve an instance of the syntax for every of the supported APIs. Be aware that each the Scala and Python APIs are used straight as a readStream enter and the SQL API makes use of the STREAM object.
Scala
val df = spark
.readStream
.format("pulsar")
.choice("service.url"," "...")
.choice("subjects", "topic1")
.load()Python
df = (
spark
.readStream
.format("pulsar")
.choice("service.url"," "...")
.choice("subjects", "topic1")
.load()
)SQL
SELECT CAST(worth as STRING)
FROM STREAM
read_pulsar(
serviceUrl => '...',
subject => 'topic1',
startingOffsets => 'earliest'
)To see additional out there configuration choices please confer with the Databricks documentation. For utilization with open supply Apache Spark see the StreamNative documentation.
Abstract
In a world pushed by real-time information, the collaboration between StreamNative and Databricks to develop the Pulsar-Spark Connector represents a major leap ahead. This groundbreaking connector addresses the important thing challenges of real-time information processing, enabling organizations to assemble end-to-end information pipelines, profit from scalability and reliability, and make data-driven selections at unparalleled speeds.
As we embark on this journey, we’re dedicated to steady enchancment, innovation, and assembly our customers’ evolving wants. We additionally invite you to be a part of us in contributing to this thrilling endeavor, and we sit up for the constructive impression the Pulsar-Spark Connector may have in your real-time information processing and analytics endeavors.
Thanks in your help, and we’re excited to form the way forward for real-time information processing with you.