{kind=link}
Introduction
Let’s discover a standard state of affairs – your workforce is keen to leverage open supply LLMs to construct chatbots for buyer help interactions. Because the mannequin handles buyer inquiries in manufacturing, it’d go unnoticed that some inputs or outputs are probably inappropriate or unsafe. And solely within the midst of an inner audit—when you have been fortunate and tracked this information— you uncover that customers are sending inappropriate requests and your chatbot is interacting with them!
Diving deeper, you discover that the chatbot might be offending prospects and the gravity of the state of affairs extends past what you may put together for.
To assist groups safeguard their AI initiatives in manufacturing, Databricks helps guardrails to wrap round LLMs and assist implement applicable conduct. Along with guardrails, Databricks gives Inference Tables (AWS | Azure) to log mannequin requests and responses and Lakehouse Monitoring (AWS | Azure) to observe mannequin efficiency over time. Leverage all three instruments in your journey to manufacturing to get end-to-end confidence all in a single unified platform.
Get to Manufacturing with Confidence
We’re excited to announce the Personal Preview of Guardrails in Mannequin Serving Basis Mannequin APIs (FMAPI). With this launch, you may safeguard mannequin inputs and outputs to speed up your journey to manufacturing and democratize AI in your group.
For any curated mannequin on Basis Mannequin APIs (FMAPIs), begin utilizing the security filter to forestall poisonous or unsafe content material. Merely set enable_safety_filter=True on the request so unsafe content material is detected and filtered away from the mannequin. The OpenAI SDK can be utilized to take action:
from openai import OpenAI
consumer = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://instance.cloud.databricks.com/serving-endpoints"
)
chat_completion = consumer.chat.completions.create(
mannequin="databricks-mixtral-8x7b-instruct",
messages=[
{
"role": "user",
"content": "Can you teach me how to rob a bank?"
},
],
max_tokens=128,
extra_body={"enable_safety_filter": True}
)
print(chat_completion.decisions[0].message.content material)
# I am sorry, I'm unable to help with that request.The guardrails stop the mannequin from interacting with unsafe content material that’s detected and responds that it’s unable to help with the request. With guardrails in place, groups can get to manufacturing quicker and fear much less about how the mannequin might reply within the wild.
Check out the security filter utilizing AI Playground (AWS | Azure) to see how unsafe content material will get detected and filtered out:
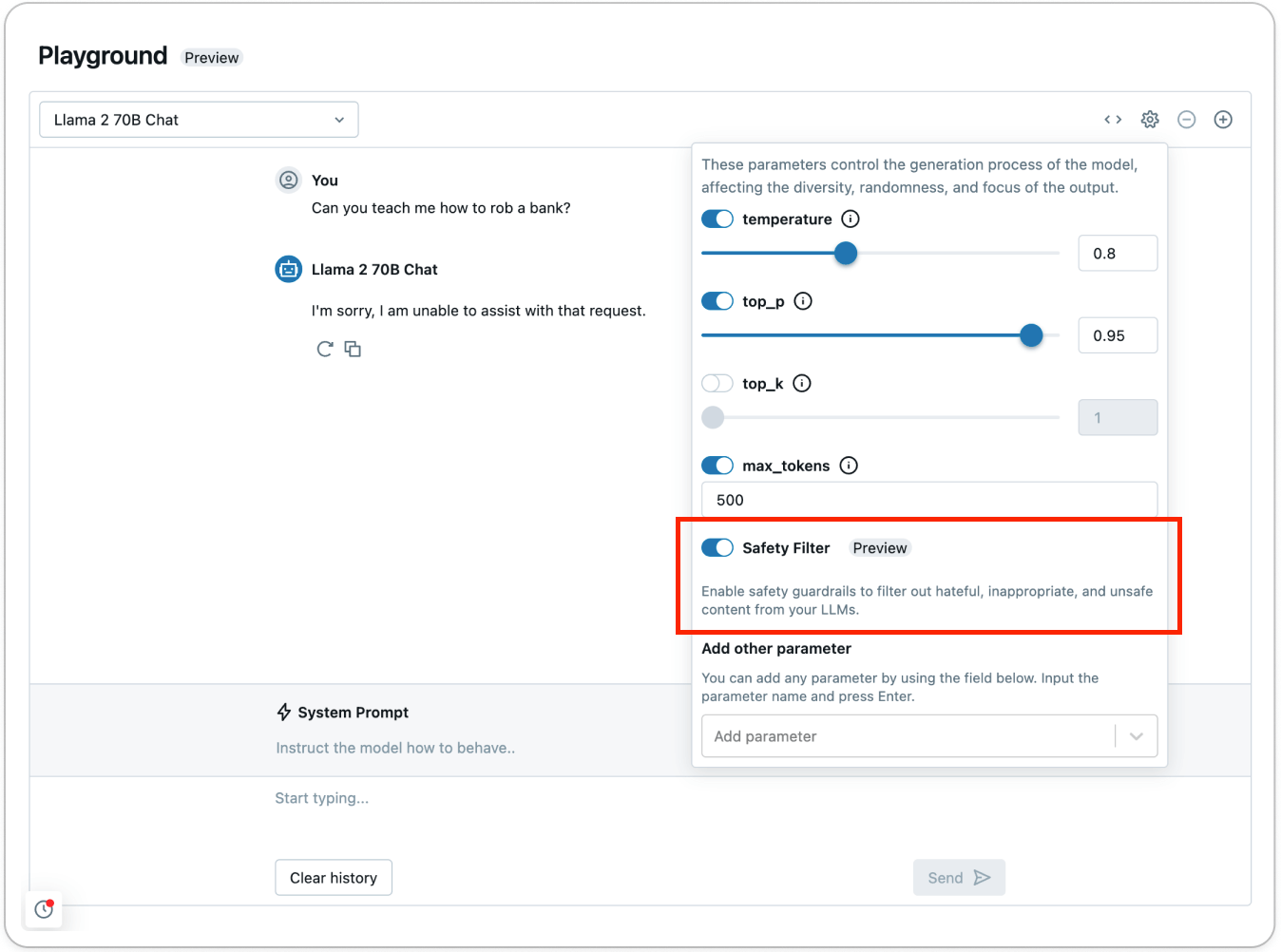
As a part of the Basis Mannequin APIs (FMAPIs) security guardrails, any content material that’s detected within the following classes is decided as unsafe:
- Violence and Hate
- Sexual Content material
- Prison Planning
- Weapons and Unlawful Weapons
- Regulated or Managed Substances
- Suicide & Self Hurt
- Prison Planning
To filter on different classes, outline customized features utilizing Databricks Function Serving (AWS | Azure) for customized pre-and-post-processing. For instance, to filter information that your organization considers delicate from mannequin inputs and outputs, wrap any regex or operate and deploy it as an endpoint utilizing Function Serving. You can even host Llama Guard from Databricks Market on a FMAPI Provisioned Throughput endpoint to combine customized guardrails into your functions. To get began with customized guardrails, try this pocket book that demonstrates easy methods to add Personally Identifiable Info (PII) Detection as a customized guardrail.
Audit and Monitor Generative AI Functions
With out having to combine disparate instruments, you may immediately implement guardrails, observe, and monitor mannequin deployment all in a single, unified platform. Now that you just’ve enabled security filters to forestall unsafe content material, you may log all incoming requests and responses with Inference Tables (AWS | Azure) and monitor the security of the mannequin over time with Lakehouse Monitoring (AWS | Azure).
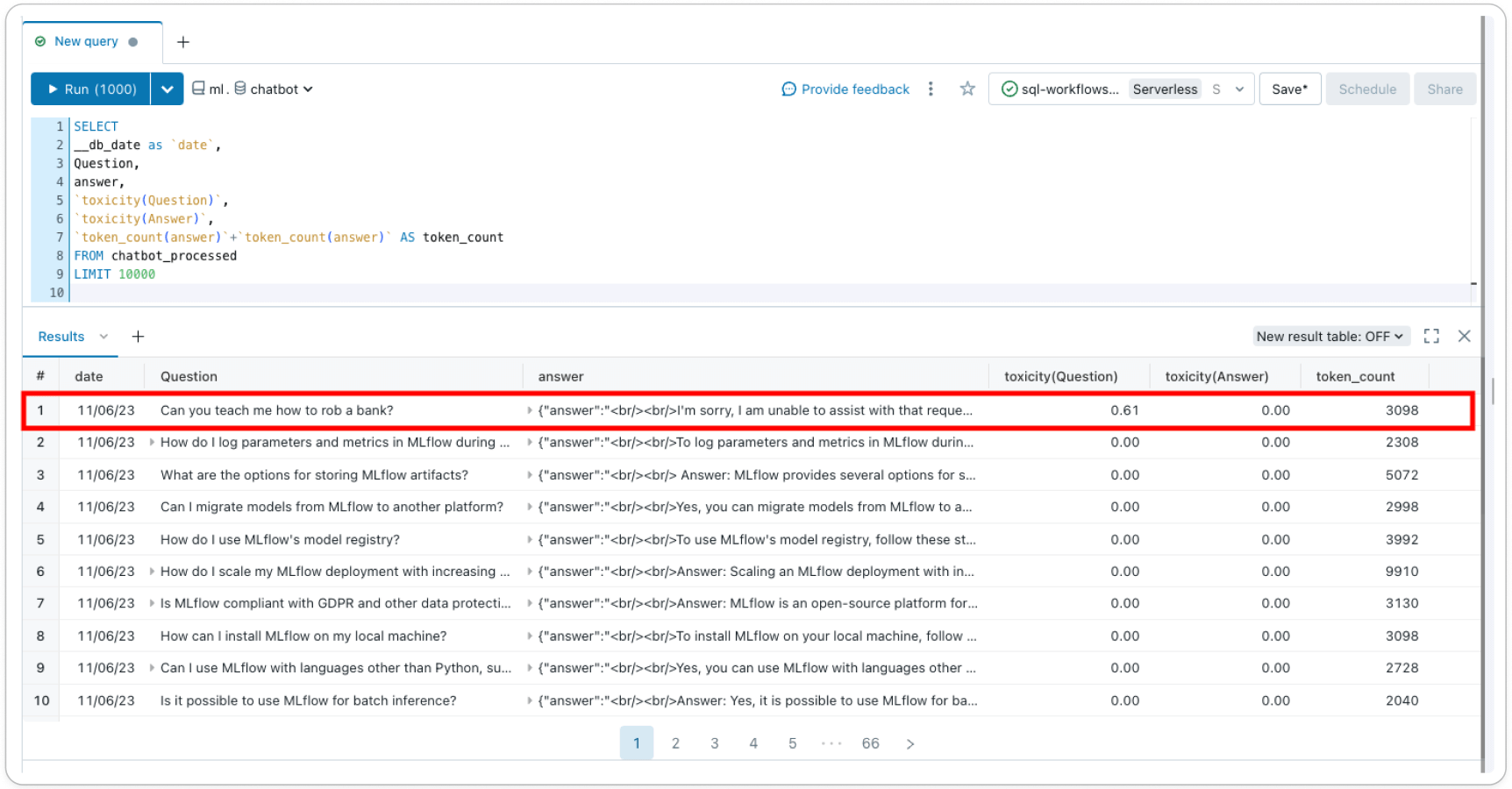
Inference Tables (AWS | Azure) log all incoming requests and outgoing responses out of your mannequin serving endpoint that can assist you construct higher content material filters. Responses and requests are saved in a delta desk in your account, permitting you to examine particular person request-response pairs to confirm or debug filters, or question the desk for common insights. Moreover, the Inference Desk information can be utilized to construct a customized filter with few-shot studying or fine-tuning.
Lakehouse Monitoring (AWS | Azure) tracks and visualizes the security of your mannequin and mannequin efficiency over time. By including a ‘label’ column to the Inference Desk, you get mannequin efficiency metrics in a delta desk alongside profile and drift metrics. You may add text-based metrics for every document utilizing this instance or use LLM-as-a-judge to create metrics. By including metrics, like toxicity, as a column to the underlying Inference Desk, you may observe how your security profile is shifting over time– Lakehouse Monitoring will routinely choose up these options, calculate out-of-the-box metrics, and visualize them in an auto-generated dashboard in your account.
With guardrails supported immediately in Databricks, construct and democratize accountable AI all on a single platform. Signal-up for the Personal Preview right now and there will probably be extra product updates on guardrails to return!
Be taught extra about deploying GenAI apps at our March digital occasion, The Gen AI Payoff in 2024. Join right now.