{kind=link}
Massive Language Mannequin (LLM) machine studying know-how is proliferating quickly, with a number of competing open-source and proprietary architectures now obtainable. Along with the generative textual content duties related to platforms reminiscent of ChatGPT, LLMs have been demonstrated to have utility in lots of text-processing purposes—starting from helping within the writing of code to categorization of content material.
SophosAI has researched quite a few methods to make use of LLMs in cybersecurity-related duties. However given the number of LLMs obtainable to work with, researchers are confronted with a difficult query: learn how to decide which mannequin is the very best fitted to a specific machine studying drawback. A great technique for choosing a mannequin is to create benchmark duties – typical issues that can be utilized to evaluate the capabilities of the mannequin simply and rapidly.
At present, LLMs are evaluated on sure benchmarks, however these assessments solely gauge the final talents of those fashions on primary pure language processing (NLP) duties. The Huggingface Open LLM (Massive Language Mannequin) Leaderboard makes use of seven distinct benchmarks to judge all of the open-source fashions accessible on Huggingface.
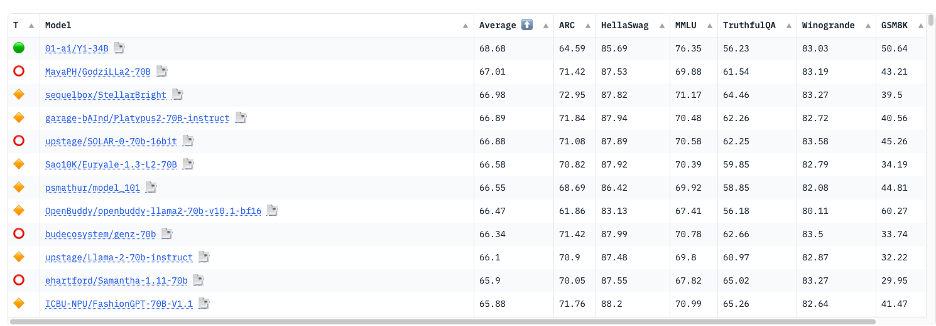
Nevertheless, efficiency on these benchmark duties could not precisely replicate how effectively fashions will work in cybersecurity contexts. As a result of these duties are generalized, they may not reveal disparities in security-specific experience amongst fashions that outcome from their coaching information.
To beat that, we got down to create a set of three benchmarks primarily based on duties we consider are elementary perquisites for many LLM-based defensive cybersecurity purposes:
- Performing as an incident investigation assistant by changing pure language questions on telemetry into SQL statements
- Producing incident summaries from safety operations middle (SOC) information
- Score incident severity
These benchmarks serve two functions: figuring out foundational fashions with potential for fine-tuning, after which assessing the out-of-the-box (untuned) efficiency of these fashions. We examined 14 fashions towards the benchmarks, together with three different-sized variations of each Meta’s LlaMa2 and CodeLlaMa fashions. We selected the next fashions for our evaluation, choosing them primarily based on standards reminiscent of mannequin dimension, recognition, context dimension, and recency:
| Mannequin Title | Measurement | Supplier | Max. Context Window |
| GPT-4 | 1.76T? | OpenA! | 8k or 32k |
| GPT-3.5-Turbo | ? | 4k or 16k | |
| Jurassic2-Extremely | ? | AI21 Labs | 8k |
| Jurassic2-Mid | ? | 8k | |
| Claude-Prompt | ? | Anthropic | 100k |
| Claude-v2 | ? | 100k | |
| Amazon-Titan-Massive | 45B | Amazon | 4k |
| MPT-30B-Instruct | 30B | Mosaic ML | 8k |
| LlaMa2 (Chat-HF) | 7B, 13B, 70B | Meta | 4k |
| CodeLlaMa | 7B, 13B, 34B | 4k |
On the primary two duties, OpenAI’s GPT-4 clearly had the very best efficiency. However on our closing benchmark, not one of the fashions carried out precisely sufficient in categorizing incident severity to be higher than random choice.
Job 1: Incident Investigation Assistant
In our first benchmark process, the first goal was to evaluate the efficiency of LLMs as SOC analyst assistants in investigating safety incidents by retrieving pertinent info primarily based on pure language queries—a process we’ve beforehand experimented with. Evaluating LLMs’ means to transform pure language queries into SQL statements, guided by contextual schema information, helps decide their suitability for this process.
We approached the duty as a few-shot prompting drawback. Initially, we offer the instruction to the mannequin that it must translate a request into SQL. Then, we furnish the schema info for all information tables created for this drawback. Lastly, we current three pairs of instance requests and their corresponding SQL statements to function examples for the mannequin, together with a fourth request that the mannequin ought to translate to SQL.
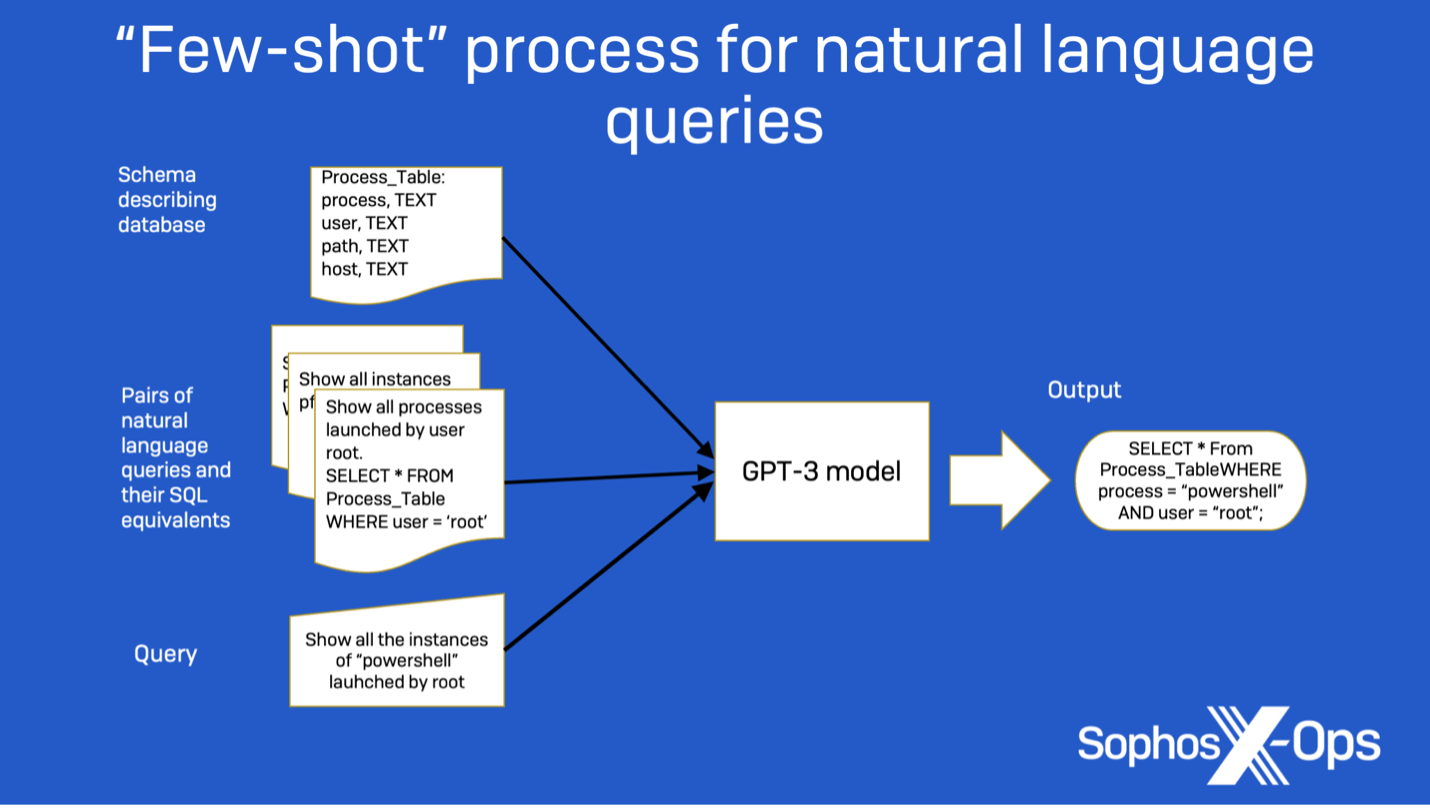
An instance immediate for this process is proven beneath:
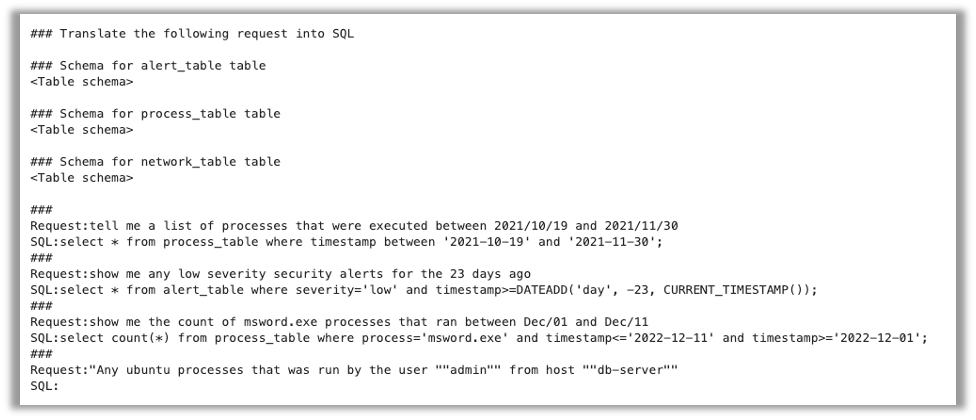
The accuracy of the question generated by every mannequin was measured by first checking if the output matched the anticipated SQL assertion precisely. If the SQL was not an actual match, we then ran the queries towards the check database we created and in contrast the ensuing information units with the outcomes of the anticipated question. Lastly, we handed the generated question and the anticipated question to GPT-4 to judge question equivalence. We used this technique to judge the outcomes of 100 queries for every mannequin.
Outcomes
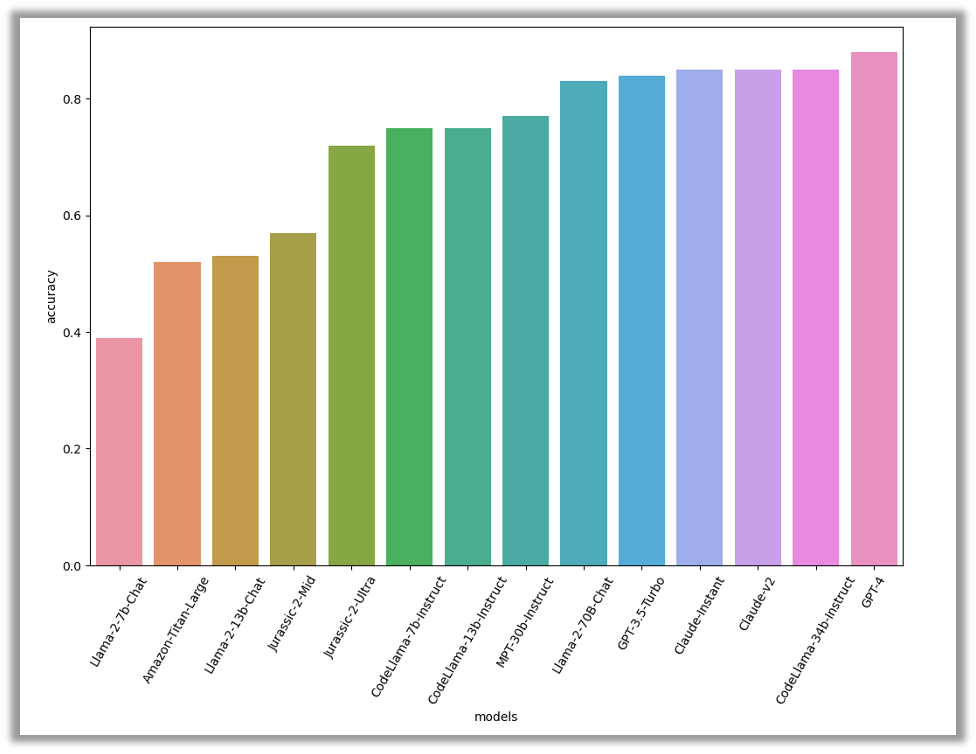
In accordance with our evaluation, GPT-4 was the highest performer, with an accuracy degree of 88%. Coming in intently behind had been three different fashions: CodeLlama-34B-Instruct and the 2 Claude fashions, all at 85% accuracy. CodeLlama’s distinctive efficiency on this process is anticipated, because it focuses on producing code
Total, the excessive accuracy scores point out that this process is simple for the fashions to finish. This implies that these fashions may very well be successfully employed to assist menace analysts in investigating safety incidents out of the field.
Job 2: Incident Summarization
In Safety Operations Facilities (SOCs), menace analysts examine quite a few safety incidents day by day. Usually, these incidents are offered as a sequence of occasions that occurred on a person endpoint or community, associated to suspicious exercise that has been detected. Risk analysts make the most of this info to conduct additional investigation. Nevertheless, this sequence of occasions can typically be noisy and time-consuming for the analysts to navigate by, making it troublesome to establish the notable occasions. That is the place giant language fashions could be worthwhile, as they’ll help in figuring out and organizing occasion information primarily based on a particular template, making it simpler for analysts to grasp what is occurring and decide their subsequent steps.
For this benchmark, we use a dataset of 310 incidents from our Managed Detection and Response (MDR) SOC, every formatted as a sequence of JSON occasions with various schemas and attributes relying on the capturing sensor. The information was handed to the mannequin together with directions to summarize the info and a predefined template for the summarization course of.

We used 5 distinct metrics to judge the summaries generated by every mannequin. First, we verified that the incident descriptions generated efficiently extracted all of the pertinent particulars from the uncooked incident information by evaluating them to “gold normal” summaries—descriptions initially generated utilizing GPT-4 after which improved upon and corrected with the assistance of a guide evaluate by Sophos analysts.

If the info extracted didn’t utterly match, we measured how far off all of the extracted particulars had been from the human-generated reviews by calculating the Longest Frequent Subsequence and Levenshtein distance for every extracted truth from the incident information, and deriving a median rating for every mannequin. We additionally evaluated the descriptions utilizing the BERTScore metric, a similarity rating utilizing ADA2 mannequin, and the METEOR analysis metric.
Outcomes
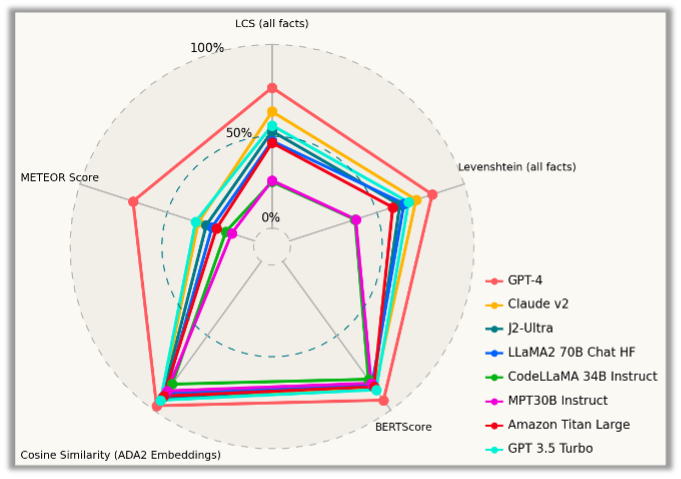
GPT-4 once more stands out because the clear winner, performing considerably higher than the opposite fashions in all features. However GPT-4 has an unfair benefit in some qualitative metrics—particularly the embedding-based ones—as a result of the gold normal set used for analysis was developed with the assistance of GPT-4 itself.
The numbers don’t essentially inform the complete story of how effectively the fashions summarized occasions. To higher grasp what was occurring with every mannequin, we seemed on the descriptions generated by them and evaluated them qualitatively. (To guard buyer info, we are going to show solely the primary two sections of the incident abstract that was generated.)
GPT-4 did a decent job of summarization; the abstract was correct, although slightly verbose. GPT-4 additionally accurately extracted the MITRE methods within the occasion information. Nevertheless, it missed the indentation used to suggest the distinction between the MITRE method and tactic.

Llama-70B additionally extracted all of the artifacts accurately. Nevertheless, it missed a truth within the abstract (that the account was locked out). It additionally fails to separate the MITRE method and tactic within the abstract.

J2-Extremely, then again, didn’t achieve this effectively. It repeated the MITRE method thrice and missed the tactic utterly. The abstract, nevertheless, appears very concise and on level.
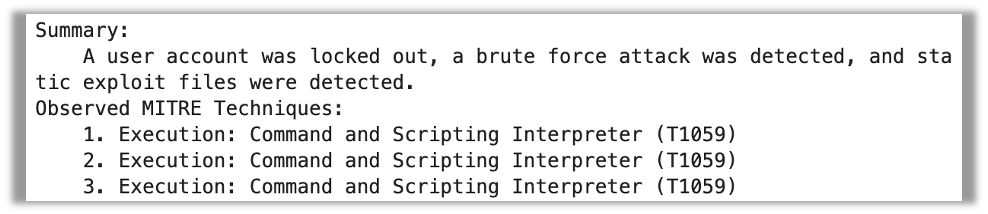
MPT-30B-Instruct fails utterly in following the format, and simply produces a paragraph summarizing what it sees within the uncooked information.

Whereas most of the details extracted had been appropriate, the output was loads much less useful than an organized abstract following the anticipated template would have been.
CodeLlaMa-34B’s output was completely unusable—it regurgitated occasion information as an alternative of summarizing, and it even partially “hallucinated” some information.
Job 3: Incident Severity Analysis
The third benchmark process we assessed was a modified model of a standard ML-Sec drawback: figuring out if an noticed occasion is both a part of innocent exercise or an assault. At SophosAI, we make the most of specialised ML fashions designed for evaluating particular varieties of occasion artifacts reminiscent of Moveable Executable information and Command traces.
For this process, our goal was to find out if an LLM can study a sequence of safety occasions and assess their degree of severity. We instructed the fashions to assign a severity ranking from 5 choices: Vital, Excessive, Medium, Low, and Informational. Right here is the format of the immediate we supplied to the fashions for this process:

The immediate explains what every severity degree means and supplies the identical JSON detection information we used for the earlier process. Because the occasion information was derived from precise incidents, we had each the preliminary severity evaluation and the ultimate severity degree for every case. We evaluated the efficiency of every mannequin towards over 3300 circumstances and measured the outcomes.
The efficiency of all LLMs we examined was evaluated utilizing varied experimental setups, however none of them demonstrated ample efficiency higher than random guessing. We performed experiments in a zero-shot setting (proven in blue) and a 3-shot setting (proven in yellow) utilizing nearest neighbors, however neither experiment reached an accuracy threshold of 30%.
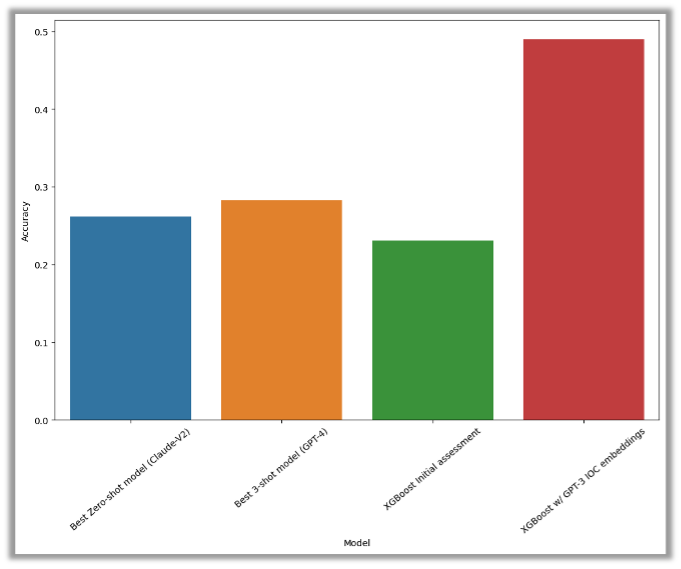
As a baseline comparability, we used an XGBoost mannequin with solely two options: the preliminary severity assigned by the triggering detection guidelines and the kind of alert. This efficiency is represented by the inexperienced bar.
Moreover, we experimented with making use of GPT-3-generated embeddings to the alert information (represented by the purple bar). We noticed important enhancements in efficiency, with accuracy charges reaching 50%.
We discovered typically that almost all fashions should not outfitted to carry out this type of process, and sometimes have bother sticking to the format. We noticed some humorous failure behaviors—together with producing further immediate directions, regurgitating detection information, or writing code that produces the severity label as output as an alternative of simply producing a label.
Conclusion
The query of which mannequin to make use of for a safety utility is a nuanced one which includes quite a few, diversified elements. These benchmarks supply some info for beginning factors to contemplate, however don’t essentially handle each potential drawback set.
Massive language fashions are efficient in aiding menace searching and incident investigation. Nevertheless, they might nonetheless require some guardrails and steering. We consider that this potential utility could be applied utilizing LLMs out of the field, with cautious immediate engineering.
In relation to summarizing incident info from uncooked information, most LLMs carry out adequately, although there’s room for enchancment by fine-tuning. Nevertheless, evaluating particular person artifacts or teams of artifacts stays a difficult process for pre-trained and publicly obtainable LLMs. To sort out this drawback, a specialised LLM skilled particularly on cybersecurity information is perhaps required.
When it comes to pure efficiency phrases, we noticed GPT-4 and Claude v2 did finest throughout the board on all our benchmarks. Nevertheless, the CodeLlama-34B mannequin will get an honorary point out for doing effectively on the primary benchmark process, and we expect it’s a aggressive mannequin for deployment as a SOC assistant.