{kind=link}

Right now on the GPU Expertise Convention, Nvidia launched a brand new providing aimed toward serving to clients rapidly deploy their generative AI functions in a safe, secure, and scalable method. Dubbed Nvidia Inference Microservice, or NIM, the brand new Nvidia AI Enterprise part bundles every part a person wants, together with AI fashions and integration code, all working in a preconfigured Kubernetes Helm chart that may be deployed wherever.
As firms transfer from testing giant language fashions (LLM) to really deploying them in a manufacturing setting, they’re working into a bunch of challenges, from sizing the {hardware} for inference workloads to integrating exterior information as a part of a retrieval augmented era (RAG) workflow to performing immediate engineering utilizing a device like LlamaIndex or LangChain.
The objective with NIM is to cut back the quantity of integration and improvement work firms should carry out to carry all of those shifting components collectively right into a deployable entity. This can let firms transfer their GenAI functions from the proof of idea (POC) stage to manufacturing, or “zero to inference in just some minutes,” mentioned Manuvir Das, the vp of enterprise computing at Nvidia.
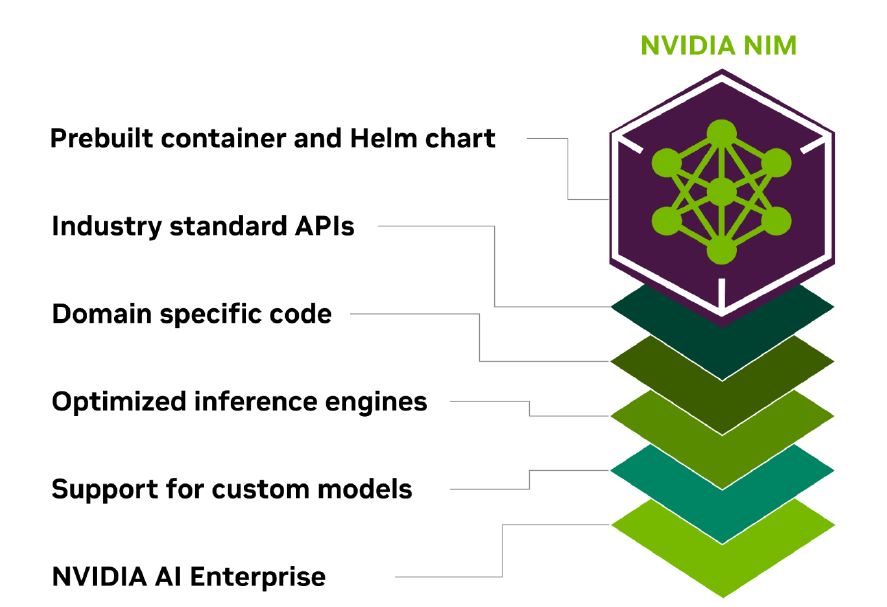
Nvidia NIM streamlines the deployment of GenAI apps (Picture courtesy Nvidia)
“What this actually does is it takes the entire software program work that we’ve accomplished over the previous few years and places it collectively in a bundle the place we take a mannequin and we put the mannequin in a container as a microservice,” Das mentioned throughout a press briefing final week. “We bundle it along with the optimized inference engines that we produce each night time at Nvidia throughout a variety of GPUs.”
Accessible from inside the Enterprise AI software program, NIM offers clients entry to a variety of proprietary and open supply LLMs from suppliers like OpenAI, Meta, Mistral, Nvidia itself, and extra. Nvidia engineers are continuously working to patch safety points and optimize efficiency of those fashions working throughout numerous Nvidia GPUs, from giant H100s working within the cloud to smaller choices like Jetson working on the sting. This work accrues to clients with a minimal of effort once they deploy a GenAI app utilizing NIM.
“NIM leverages optimized inference engines for every mannequin and {hardware} setup, offering the very best latency and throughput on accelerated infrastructure,” Nvidia says in a weblog submit. “Along with supporting optimized neighborhood fashions, builders can obtain much more accuracy and efficiency by aligning and fine-tuning fashions with proprietary information sources that by no means go away the boundaries of their information middle.”
NIM leverages trade customary APIs and microservices, each to combine the assorted elements that make up a GenAI app (mannequin, RAG, information, and so on.) in addition to to show and combine the ultimate GenAI software with their enterprise functions. After they’re able to deploy the NIM, they’ve a selection of platforms to mechanically deploy to.

Nvidia is aiming to speed up AI deployment
It’s all about eliminating as a lot of the tedious integration and deployment work so clients can get their GenAI into operation as rapidly as doable, Das mentioned.
“We take the mannequin and we bundle it along with the engines which can be optimized for these fashions to run as effectively as doable throughout the vary of Nvidia GPUs that you will discover in laptops or workstations in information facilities and clouds,” Das mentioned. “We put trade customary APIs on them in order that they’re appropriate with cloud endpoints like Open AI, for instance. After which we put it right into a container as a microservice so it may be deployed wherever. You possibly can deploy it on high of Kubernetes utilizing Helm charts, you may deploy it simply on legacy infrastructure with out Kubernetes as a container.”
Within the latest previous, information scientists had been wanted to construct and deploy most of these GenAI apps, Das mentioned. However with NIM, any developer now has the flexibility to construct issues like chatbots and deploy them to their clients, he mentioned.
“As a developer, you may entry [AI models] by means of the API keys after which, better of all you may click on the obtain and you’ll put them on the NIM and put it in a briefcase and take it with you,” Das continued. “You possibly can procure Nvidia AI Enterprise. We made that quite simple to do. And also you’re off and working and you’ll go to manufacturing.”
NIM is part of the brand new launch of Nvidia AI Enterprise, model 5.0, whi ch is out there now. Along with NIM, 5.0 brings different new options, together with higher help in RAPIDS for a few of the main information analytic and machine studying frameworks, like Spark and Pandas.
ch is out there now. Along with NIM, 5.0 brings different new options, together with higher help in RAPIDS for a few of the main information analytic and machine studying frameworks, like Spark and Pandas.
Nvidia and Databricks have been companions for a while. With AI Enterprise 5.0, Nvidia is including help for Photon, the optimized C++-based model of Spark developed by Databricks, enabling customers to run Photon on GPUs.
“[W]e are working along with Databricks,” Das mentioned. “They’re the main Spark firm. They’re the house of Spark, and with them we’re accelerating their flagship information intelligence engine powered by Photon to run on GPUs. So you may have the most effective of each worlds. All the innovation that Databricks has accomplished making information processing run quicker on Spark, and the world that we’ve accomplished to speed up GPU’s for Spark.”
The combination work Nvidia has accomplished with pandas could attain an excellent larger potential person base, as Das factors out that there are 9.6 million pandas customers. With the enhancements in cuDF, pandas workloads can now run on GPUs, Das mentioned.
“What we’ve accomplished is we’ve taken our RAPIDS libraries and we now have now made them seamless so you may get the advantage of GPU acceleration–150 instances quicker for the widespread operations, which is be part of and group by, which is absolutely behind most queries that you just do, with zero code change,” Das mentioned. “It’s an entire, seamless drop in substitute. You simply exchange one bundle with one other. one line of code, and also you’re off and working and also you get this profit.”
Nvidia AI Enterprise prices $4,500 per GPU per 12 months. Prospects may use it within the cloud for $1 per GPU per hour.
Associated Gadgets:
Nvidia Bolsters RAPIDS Graph Analytics with NetworkX Enlargement
NVIDIA CEO Jensen Huang to Ship Keynote at GTC 2024
Nvidia CEO Requires Sovereign AI Infrastructure