{kind=link}
Occasions change, and so should benchmarks. Now that we’re firmly within the age of huge generative AI, it’s time so as to add two such behemoths,
Llama 2 70B and Steady Diffusion XL, to MLPerf’s inferencing checks. Model 4.0 of the benchmark checks greater than 8,500 outcomes from 23 submitting organizations. As has been the case from the start, computer systems with Nvidia GPUs got here out on high, significantly these with its H200 processor. However AI accelerators from Intel and Qualcomm had been within the combine as properly.
MLPerf began pushing into the LLM world
final yr when it added a textual content summarization benchmark GPT-J (a 6 billion parameter open-source mannequin). With 70 billion parameters, Llama 2 is an order of magnitude bigger. Due to this fact it requires what the organizer MLCommons, a San Francisco-based AI consortium, calls “a distinct class of {hardware}.”
“By way of mannequin parameters, Llama-2 is a dramatic enhance to the fashions within the inference suite,”
Mitchelle Rasquinha, a software program engineer at Google and co-chair of the MLPerf Inference working group, mentioned in a press launch.
Steady Diffusion XL, the brand new
text-to-image era benchmark, is available in at 2.6 billion parameters, lower than half the scale of GPT-J. The recommender system check, revised final yr, is bigger than each.
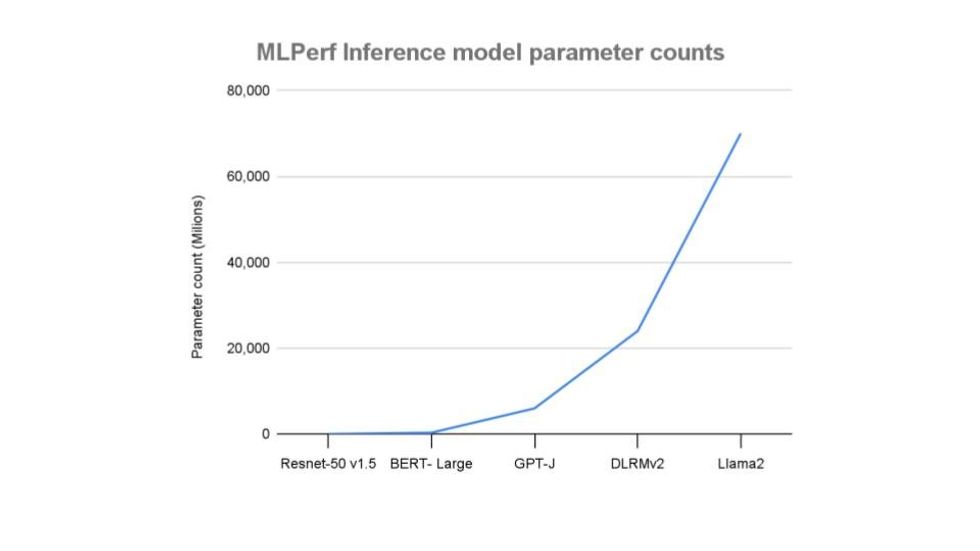 MLPerf benchmarks run the vary of sizes, with the newest, resembling Llama 2 70B within the many tens of billions of parameters.MLCommons
MLPerf benchmarks run the vary of sizes, with the newest, resembling Llama 2 70B within the many tens of billions of parameters.MLCommons
The checks are divided between methods meant to be used in
knowledge facilities and people meant to be used by gadgets out within the world, or the “edge” as its known as. For every benchmark, a pc might be examined in what’s known as an offline mode or in a extra real looking method. In offline mode, it runs by means of the check knowledge as quick as doable to find out its most throughput. The extra real looking checks are supposed to simulate issues like a stream of knowledge coming from a digital camera in a smartphone, a number of streams of knowledge from all of the cameras and sensors in a automobile, or as queries in a knowledge heart setup, for instance. Moreover, the ability consumption of some methods was tracked throughout duties.
Knowledge heart inference outcomes
The highest performers within the new generative AI classes was an Nvidia H200 system that mixed eight of the GPUs with two Intel Xeon CPUs. It managed slightly below 14 queries per second for Steady Diffusion and about 27,000 tokens per second for Llama 2 70B. Its nearest competitors had been 8-GPU H100 methods. And the efficiency distinction wasn’t big for Steady Diffusion, about 1 question per second, however the distinction was bigger for Llama 2 70B.
H200s are the identical
Hopper structure because the H100, however with about 75 % extra high-bandwidth reminiscence and 43 % extra reminiscence bandwidth. In line with Nvidia’s Dave Salvator, reminiscence is especially vital in LLMs, which carry out higher if they’ll match totally on the chip with different key knowledge. The reminiscence distinction confirmed within the Llama 2 outcomes, the place H200 sped forward of H100 by about 45 %.
In line with the corporate, methods with H100 GPUs had been 2.4-2.9 instances sooner than H100 methods from the
outcomes of final September, due to software program enhancements.
Though H200 was the star of Nvidia’s benchmark present, its latest GPU structure,
Blackwell, formally unveiled final week, looms within the background. Salvator wouldn’t say when computer systems with that GPU may debut within the benchmark tables.
For its half,
Intel continued to provide its Gaudi 2 accelerator as the one choice to Nvidia, at the very least among the many firms taking part in MLPerf’s inferencing benchmarks. On uncooked efficiency, Intel’s 7-nanometer chip delivered rather less than half the efficiency of 5-nm H100 in an 8-GPU configuration for Steady Diffusion XL. Its Gaudi 2 delivered outcomes nearer to one-third the Nvidia efficiency for Llama 2 70B. Nonetheless, Intel argues that in the event you’re measuring efficiency per greenback (one thing they did themselves, not with MLPerf), the Gaudi 2 is about equal to the H100. For Steady Diffusion, Intel calculates it beats H100 by about 25 % on efficiency per greenback. For Llama 2 70B it’s both a fair contest or 21 % worse, relying on whether or not you’re measuring in server or offline mode.
Gaudi 2’s successor, Gaudi 3 is predicted to reach later this yr.
Intel additionally touted a number of CPU-only entries that confirmed an inexpensive stage of inferencing efficiency is feasible within the absence of a GPU, although not on Llama 2 70B or Steady Diffusion. This was the primary look of Intel’s fifth era Xeon CPUs within the MLPerf inferencing competitors, and the corporate claims a efficiency increase starting from 18 % to 91 % over 4th era Xeon methods from September 2023 outcomes.
Edge inferencing outcomes
As giant as it’s, Llama 2 70B wasn’t examined within the edge class, however Steady Diffusion XL was. Right here the highest performer was a system utilizing two Nvidia L40S GPUs and an Intel Xeon CPU. Efficiency right here is measured in latency and in samples per second. The system, submitted by Taipei-based cloud infrastructure firm
Wiwynn, produced solutions in lower than 2 seconds in single-stream mode. When pushed in offline mode, it generates 1.26 outcomes per second.
Energy consumption
Within the knowledge heart class, the competition round vitality effectivity was between Nvidia and Qualcomm. The latter has targeted on vitality environment friendly inference since introducing the Cloud AI 100 processor greater than a yr in the past. Qualcomm launched a brand new era of the accelerator chip the Cloud AI 100 Extremely late final yr, and its first outcomes confirmed up within the edge and knowledge heart efficiency benchmarks above. In comparison with the Cloud AI 100 Professional outcomes, Extremely produced a 2.5 to three instances efficiency increase whereas consuming lower than 150 Watts per chip.
Among the many edge inference entrance, Qualcomm was the one firm to try Steady Diffusion XL, managing 0.6 samples per second utilizing 578 watts.
From Your Web site Articles
Associated Articles Across the Net