{kind=link}
In 1997 the IBM Deep Blue supercomputer defeated world chess champion Garry Kasparov. It was a groundbreaking demonstration of supercomputer expertise and a primary glimpse into how high-performance computing may at some point overtake human–stage intelligence. Within the 10 years that adopted, we started to make use of synthetic intelligence for a lot of sensible duties, equivalent to facial recognition, language translation, and recommending motion pictures and merchandise.
Quick-forward one other decade and a half and synthetic intelligence has superior to the purpose the place it could actually “synthesize information.” Generative AI, equivalent to ChatGPT and Steady Diffusion, can compose poems, create art work, diagnose illness, write abstract reviews and laptop code, and even design built-in circuits that rival these made by people.
Great alternatives lie forward for synthetic intelligence to change into a digital assistant to all human endeavors. ChatGPT is an efficient instance of how AI has democratized using high-performance computing, offering advantages to each particular person in society.
All these marvelous AI purposes have been on account of three elements: improvements in environment friendly machine-learning algorithms, the provision of large quantities of information on which to coach neural networks, and progress in energy-efficient computing by way of the development of semiconductor expertise. This final contribution to the generative AI revolution has acquired lower than its justifiable share of credit score, regardless of its ubiquity.
Over the past three many years, the main milestones in AI have been all enabled by the modern semiconductor expertise of the time and would have been not possible with out it. Deep Blue was applied with a mixture of 0.6- and 0.35-micrometer-node chip-manufacturing expertise. The deep neural community that received the ImageNet competitors, kicking off the present period of machine studying, was applied with 40-nanometer expertise. AlphaGo conquered the sport of Go utilizing 28-nm expertise, and the preliminary model of ChatGPT was skilled on computer systems constructed with 5-nm expertise. The newest incarnation of ChatGPT is powered by servers utilizing much more superior 4-nm expertise. Every layer of the pc programs concerned, from software program and algorithms all the way down to the structure, circuit design, and system expertise, acts as a multiplier for the efficiency of AI. But it surely’s honest to say that the foundational transistor-device expertise is what has enabled the development of the layers above.
If the AI revolution is to proceed at its present tempo, it’s going to want much more from the semiconductor business. Inside a decade, it can want a 1-trillion-transistor GPU—that’s, a GPU with 10 occasions as many gadgets as is typical immediately.
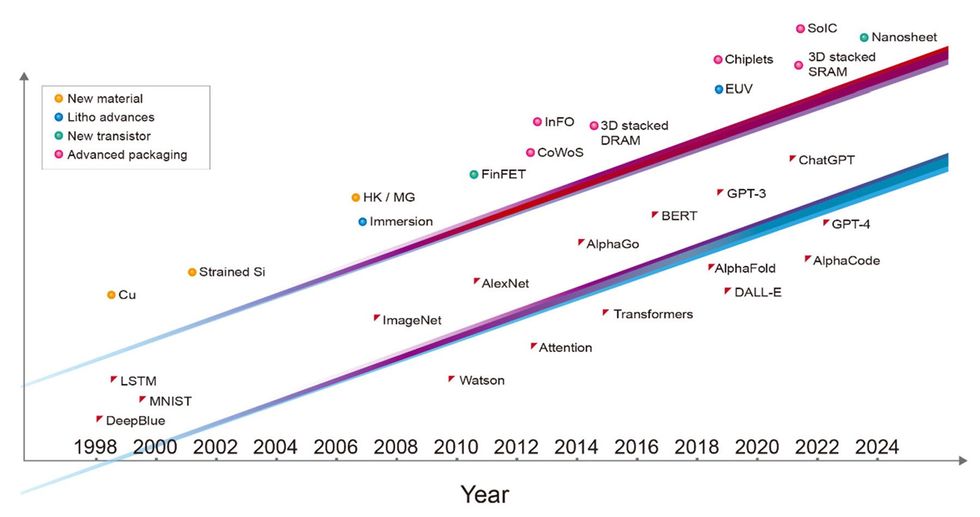 Advances in semiconductor expertise [top line]—together with new supplies, advances in lithography, new forms of transistors, and superior packaging—have pushed the event of extra succesful AI programs [bottom line]
Advances in semiconductor expertise [top line]—together with new supplies, advances in lithography, new forms of transistors, and superior packaging—have pushed the event of extra succesful AI programs [bottom line]
Relentless Progress in AI Mannequin Sizes
The computation and reminiscence entry required for AI coaching have elevated by orders of magnitude previously 5 years. Coaching GPT-3, for instance, requires the equal of greater than 5 billion billion operations per second of computation for a whole day (that’s 5,000 petaflops-days), and three trillion bytes (3 terabytes) of reminiscence capability.
Each the computing energy and the reminiscence entry wanted for brand new generative AI purposes proceed to develop quickly. We now must reply a urgent query: How can semiconductor expertise preserve tempo?
From Built-in Units to Built-in Chiplets
Because the invention of the built-in circuit, semiconductor expertise has been about cutting down in function dimension in order that we are able to cram extra transistors right into a thumbnail-size chip. At the moment, integration has risen one stage increased; we’re going past 2D scaling into 3D system integration. We are actually placing collectively many chips right into a tightly built-in, massively interconnected system. It is a paradigm shift in semiconductor-technology integration.
Within the period of AI, the aptitude of a system is instantly proportional to the variety of transistors built-in into that system. One of many foremost limitations is that lithographic chipmaking instruments have been designed to make ICs of not more than about 800 sq. millimeters, what’s known as the reticle restrict. However we are able to now prolong the dimensions of the built-in system past lithography’s reticle restrict. By attaching a number of chips onto a bigger interposer—a bit of silicon into which interconnects are constructed—we are able to combine a system that incorporates a a lot bigger variety of gadgets than what is feasible on a single chip. For instance, TSMC’s chip-on-wafer-on-substrate (CoWoS) expertise can accommodate as much as six reticle fields’ value of compute chips, together with a dozen high-bandwidth-memory (HBM) chips.
HBMs are an instance of the opposite key semiconductor expertise that’s more and more essential for AI: the flexibility to combine programs by stacking chips atop each other, what we at TSMC name system-on-integrated-chips (SoIC). An HBM consists of a stack of vertically interconnected chips of DRAM atop a management logic IC. It makes use of vertical interconnects known as through-silicon-vias (TSVs) to get alerts by way of every chip and solder bumps to kind the connections between the reminiscence chips. At the moment, high-performance GPUs use HBMextensively.
Going ahead, 3D SoIC expertise can present a “bumpless various” to the traditional HBM expertise of immediately, delivering far denser vertical interconnection between the stacked chips. Latest advances have proven HBM take a look at constructions with 12 layers of chips stacked utilizing hybrid bonding, a copper-to-copper reference to a better density than solder bumps can present. Bonded at low temperature on high of a bigger base logic chip, this reminiscence system has a complete thickness of simply 600 µm.
With a high-performance computing system composed of numerous dies operating giant AI fashions, high-speed wired communication could rapidly restrict the computation velocity. At the moment, optical interconnects are already getting used to attach server racks in information facilities. We’ll quickly want optical interfaces primarily based on silicon photonics which are packaged along with GPUs and CPUs. This can permit the scaling up of energy- and area-efficient bandwidths for direct, optical GPU-to-GPU communication, such that lots of of servers can behave as a single big GPU with a unified reminiscence. Due to the demand from AI purposes, silicon photonics will change into one of many semiconductor business’s most essential enabling applied sciences.
Towards a Trillion Transistor GPU
As famous already, typical GPU chips used for AI coaching have already reached the reticle area restrict. And their transistor rely is about 100 billion gadgets. The continuation of the development of accelerating transistor rely would require a number of chips, interconnected with 2.5D or 3D integration, to carry out the computation. The combination of a number of chips, both by CoWoS or SoIC and associated superior packaging applied sciences, permits for a a lot bigger whole transistor rely per system than might be squeezed right into a single chip. We forecast that inside a decade a multichiplet GPU may have greater than 1 trillion transistors.
We’ll must hyperlink all these chiplets collectively in a 3D stack, however luckily, business has been capable of quickly scale down the pitch of vertical interconnects, growing the density of connections. And there may be loads of room for extra. We see no motive why the interconnect density can’t develop by an order of magnitude, and even past.
Power-Environment friendly Efficiency Pattern for GPUs
So, how do all these revolutionary {hardware} applied sciences contribute to the efficiency of a system?
We are able to see the development already in server GPUs if we take a look at the regular enchancment in a metric known as energy-efficient efficiency. EEP is a mixed measure of the power effectivity and velocity of a system. Over the previous 15 years, the semiconductor business has elevated energy-efficient efficiency about threefold each two years. We consider this development will proceed at historic charges. It will likely be pushed by improvements from many sources, together with new supplies, system and integration expertise, excessive ultraviolet (EUV) lithography, circuit design, system structure design, and the co-optimization of all these expertise components, amongst different issues.
Particularly, the EEP improve will probably be enabled by the superior packaging applied sciences we’ve been discussing right here. Moreover, ideas equivalent to system-technology co-optimization (STCO), the place the totally different purposeful elements of a GPU are separated onto their very own chiplets and constructed utilizing one of the best performing and most economical applied sciences for every, will change into more and more crucial.
A Mead-Conway Second for 3D Built-in Circuits
In 1978, Carver Mead, a professor on the California Institute of Expertise, and Lynn Conway at Xerox PARC invented a computer-aided design technique for built-in circuits. They used a set of design guidelines to explain chip scaling in order that engineers may simply design very-large-scale integration (VLSI) circuits with out a lot information of course of expertise.
That very same kind of functionality is required for 3D chip design. At the moment, designers must know chip design, system-architecture design, and {hardware} and software program optimization. Producers must know chip expertise, 3D IC expertise, and superior packaging expertise. As we did in 1978, we once more want a standard language to explain these applied sciences in a approach that digital design instruments perceive. Such a {hardware} description language offers designers a free hand to work on a 3D IC system design, whatever the underlying expertise. It’s on the way in which: An open-source customary, known as 3Dblox, has already been embraced by most of immediately’s expertise corporations and digital design automation (EDA) corporations.
The Future Past the Tunnel
Within the period of synthetic intelligence, semiconductor expertise is a key enabler for brand new AI capabilities and purposes. A brand new GPU is not restricted by the usual sizes and kind elements of the previous. New semiconductor expertise is not restricted to cutting down the next-generation transistors on a two-dimensional airplane. An built-in AI system might be composed of as many energy-efficient transistors as is sensible, an environment friendly system structure for specialised compute workloads, and an optimized relationship between software program and {hardware}.
For the previous 50 years, semiconductor-technology improvement has felt like strolling inside a tunnel. The highway forward was clear, as there was a well-defined path. And everybody knew what wanted to be completed: shrink the transistor.
Now, now we have reached the tip of the tunnel. From right here, semiconductor expertise will get more durable to develop. But, past the tunnel, many extra prospects lie forward. We’re not sure by the confines of the previous.