{kind=link}
Introduction
Video recognition is a cornerstone of recent laptop imaginative and prescient, enabling machines to grasp and interpret visible content material in movies. With the fast evolution of convolutional neural networks (CNNs) and transformers, important strides have been made in enhancing the accuracy and effectivity of video recognition programs. Nonetheless, conventional approaches are sometimes constrained by closed-set studying paradigms, limiting their skill to adapt to new and rising classes in real-world eventualities. In response to the longstanding challenges encountered by conventional strategies in video recognition, a groundbreaking and transformative mannequin referred to as X-CLIP has emerged.
On this complete exploration, we delve deep into X-CLIP’s revolutionary capabilities. We dissect its core structure, unraveling the intricate mechanisms that energy its distinctive efficiency. Moreover, we highlight its outstanding zero/few-shot switch studying capabilities, showcasing how it’s revolutionizing the panorama of AI-powered video evaluation.
Come alongside on this enlightening exploration as we uncover X-CLIP’s full capabilities and its important implications for the way forward for video recognition and synthetic intelligence.

Studying Goals:
- Perceive the significance of cross-modality pretraining in video recognition.
- Discover the structure and elements of X-CLIP for efficient video evaluation.
- Learn to use X-CLIP for zero-shot video classification duties.
- Acquire insights into the advantages and implications of leveraging language-image fashions for video understanding.
So, how does X-CLIP obtain this outstanding feat?
What’s X-CLIP?
X-CLIP is a cutting-edge mannequin that’s not simply an incremental enchancment however represents a paradigm shift in how we method video understanding. It’s based on the ideas of contrastive language-image pretraining, a classy method that synergistically integrates pure language processing and visible notion.
X-CLIP’s arrival signifies a big development in video recognition, providing a holistic method past standard strategies. Its distinctive structure and progressive methodologies allow it to attain unparalleled accuracy in video evaluation duties. Furthermore, what units X-CLIP aside is its skill to seamlessly adapt to novel and various classes of movies, even when confronted with restricted coaching information.
Overview of the Mannequin
In contrast to conventional video recognition strategies that depend on supervised characteristic embeddings with one-hot labels, X-CLIP leverages textual content as supervision, offering richer semantic data. The method includes coaching a video encoder and a textual content encoder concurrently to align video and textual content representations successfully.
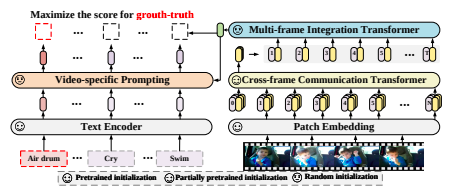
Fairly than ranging from scratch with a brand new video-text mannequin, X-CLIP builds upon present language-image fashions, enhancing them with video temporal modeling and video-adaptive textual prompts. This technique maximizes the utilization of large-scale pretrained fashions whereas seamlessly transferring their strong generalizability from pictures to movies.
Be taught Extra: Deep Studying Tutorial to Construct Video Classification Mannequin
Video Encoder Structure
The core of X-CLIP’s video encoder lies in its progressive design, consisting of two main elements:
A cross-frame communication transformer and a multi-frame integration transformer. These transformers work in tandem to seize world spatial and temporal data from video frames, enabling environment friendly illustration studying.
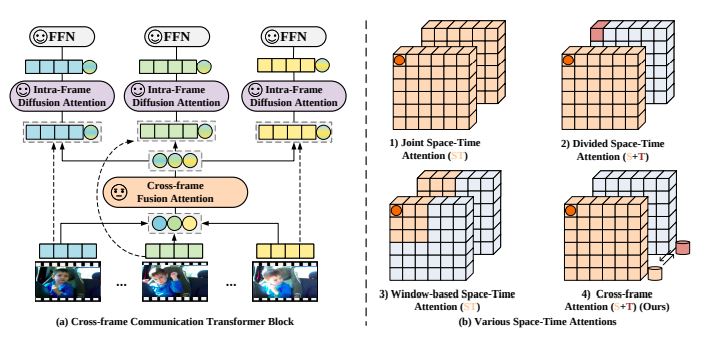
The cross-frame communication transformer facilitates data alternate between frames, permitting for the abstraction and communication of visible data throughout the whole video. That is achieved by way of a classy consideration mechanism that fashions spatio-temporal dependencies successfully.
Textual content Encoder with Video-Particular Prompting
X-CLIP’s textual content encoder is augmented with a video-specific prompting scheme, enhancing textual content illustration with contextual data from movies. In contrast to handbook immediate designs, which regularly fail to enhance efficiency, X-CLIP’s learnable prompting mechanism dynamically generates textual representations tailor-made to every video’s content material.
By leveraging the synergy between video content material and textual content embeddings, it enhances the discriminative energy of textual prompts, enabling extra correct and context-aware video recognition.
Now, let’s transfer on to learn how to use the X-CLIP Mannequin.
Zero-Shot Video Classification
Set-up Surroundings
We first set up 🤗 Transformers, file, and Pytube.
!pip set up -q git+https://github.com/huggingface/transformers.git
!pip set up -q pytube decordLoad Video
Right here you may present any YouTube video you want! Simply present the URL 🙂 in my case, I’m offering a YouTube video of enjoying soccer video games.
from pytube import YouTube
youtube_url="https://youtu.be/VMj-3S1tku0"
yt = YouTube(youtube_url)
streams = yt.streams.filter(file_extension='mp4')
print(streams)
print(len(streams))
file_path = streams[0].obtain()Pattern Frames
The X-CLIP mannequin we’ll use expects 32 frames for a given video. Let’s pattern them:
from decord import VideoReader, cpu
import torch
import numpy as np
from huggingface_hub import hf_hub_download
np.random.seed(0)
def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
converted_len = int(clip_len * frame_sample_rate)
end_idx = np.random.randint(converted_len, seg_len)
start_idx = end_idx - converted_len
indices = np.linspace(start_idx, end_idx, num=clip_len)
indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
return indices
videoreader = VideoReader(file_path, num_threads=1, ctx=cpu(0))
# pattern 32 frames
videoreader.search(0)
indices = sample_frame_indices(clip_len=32, frame_sample_rate=4, seg_len=len(videoreader))
video = videoreader.get_batch(indices).asnumpy()Let’s visualize the primary body!
from PIL import Picture
Picture.fromarray(video[0])

Visualization of 32 frames
import matplotlib.pyplot as plt
# Visualize 32 frames
fig, axs = plt.subplots(4, 8, figsize=(16, 8))
fig.suptitle('Sampled Frames from Video')
axs = axs.flatten()
for i in vary(32):
axs[i].imshow(video[i])
axs[i].axis('off')
plt.tight_layout()
plt.savefig('Frames')
plt.present()
Load X-CLIP mannequin
Let’s instantiate the XCLIP mannequin, together with its processor.
from transformers import XCLIPProcessor, XCLIPModel
model_name = "microsoft/xclip-base-patch16-zero-shot"
processor = XCLIPProcessor.from_pretrained(model_name)
mannequin = XCLIPModel.from_pretrained(model_name)Zero-Shot Classification
Utilization of X-CLIP is similar to CLIP: You’ll be able to feed it a bunch of texts, and the mannequin determines which of them go finest with the video.
import torch
input_text=["programming course", "eating spaghetti", "playing football"]
inputs = processor(textual content=input_text, movies=record(video), return_tensors="pt", padding=True)
# ahead move
with torch.no_grad():
outputs = mannequin(**inputs)
probs = outputs.logits_per_video.softmax(dim=1)
probsOutput

max_prob=torch.argmax(probs)
print(f'Video is about : {input_text[max_prob]}')Outputs

Conclusion
In conclusion, X-CLIP represents a groundbreaking development in video recognition, leveraging cross-modality pretraining to attain outstanding accuracy and flexibility. By combining language understanding with visible notion, X-CLIP opens up new potentialities in understanding and decoding video content material. Its progressive structure, seamless integration of temporal cues and textual prompts, and strong efficiency in zero/few-shot eventualities make it a game-changer within the area of AI-powered video evaluation.
Key Takeaways
- X-CLIP combines language and visible data for enhanced video recognition.
- Its cross-frame communication transformer and video-specific prompting scheme enhance illustration studying.
- Zero-shot classification with X-CLIP demonstrates its adaptability to novel classes.
- It leverages pretraining on large-scale datasets for strong and context-aware video evaluation.
Often Requested Questions
A. X-CLIP mannequin integrates language understanding and visible notion for video recognition duties.
A. X-CLIP leverages cross-modality pretraining, progressive architectures, and video-specific prompting to reinforce accuracy and flexibility.
A. Sure, X-CLIP demonstrates sturdy efficiency in zero-shot eventualities, adapting to unseen classes with minimal coaching information.