Introduction
A dependable statistical approach for figuring out significance is the evaluation of variance (ANOVA), particularly when evaluating greater than two pattern averages. Though the t-distribution is ample for evaluating the technique of two samples, an ANOVA is required when working with three or extra samples directly with the intention to decide whether or not or not their means are the identical since they arrive from the identical underlying inhabitants.
For instance, ANOVA can be utilized to find out whether or not totally different fertilizers have totally different results on wheat manufacturing in several plots and whether or not these therapies present statistically totally different outcomes from the identical inhabitants.

Prof. R.A Fisher launched the time period ‘Evaluation of Variance’ in 1920 when coping with the issue in evaluation of agronomical information. Variability is a elementary function of pure occasions. The general variation in any given dataset originates from a number of sources, which might be broadly categorised as assignable and likelihood causes.
The variation resulting from assignable causes might be detected and measured whereas the variation resulting from likelihood causes is past the management of human hand and can’t be handled individually.
In line with R.A. Fisher, Evaluation of Variance (ANOVA) is the “Separation of Variance ascribable to 1 group of causes from the variance ascribable to different group”.
Studying Goals
- Perceive the idea of Evaluation of Variance (ANOVA) and its significance in statistical evaluation, significantly when evaluating a number of pattern averages.
- Study the assumptions required for conducting an ANOVA check and its utility in several fields equivalent to drugs, schooling, advertising and marketing, manufacturing, psychology, and agriculture.
- Discover the step-by-step technique of performing a one-way ANOVA, together with organising null and different hypotheses, information assortment and group, calculation of group statistics, dedication of sum of squares, computation of levels of freedom, calculation of imply squares, computation of F-statistics, dedication of essential worth and determination making.
- Achieve sensible insights into implementing a one-way ANOVA check in Python utilizing scipy.stats library.
- Perceive the importance stage and interpretation of the F-statistic and p-value within the context of ANOVA.
- Study post-hoc evaluation strategies like Tukey’s Truthfully Vital Distinction (HSD) for additional evaluation of serious variations amongst teams.
Assumptions for ANOVA TEST
ANOVA check relies on the check statistics F.
Assumptions made relating to the validity of the F-test in ANOVA embody the next:
- The observations are impartial.
- Mother or father inhabitants from which observations are taken is regular.
- Varied therapy and environmental results are additive in nature.
One-way ANOVA
A technique ANOVA is a statistical check used to find out if there are statistically important variations within the technique of three or extra teams for a single issue (impartial variable). It compares the variance between teams to variance inside teams to evaluate if these variations are seemingly resulting from random likelihood or a scientific impact of the issue.
A number of use circumstances of one-way ANOVA from totally different domains are:
- Drugs: One-way ANOVA can be utilized to check the effectiveness of various therapies on a selected medical situation. For instance, it could possibly be used to find out whether or not three totally different medicine have considerably totally different results on lowering blood strain.
- Training: One-way ANOVA can be utilized to investigate whether or not there are important variations in check scores amongst college students who’ve been taught utilizing totally different educating strategies.
- Advertising and marketing: One-way ANOVA might be employed to evaluate whether or not there are important variations in buyer satisfaction ranges amongst merchandise from totally different manufacturers.
- Manufacturing: One-way ANOVA might be utilized to investigate whether or not there are important variations within the energy of supplies produced by totally different manufacturing processes.
- Psychology: One-way ANOVA can be utilized to analyze whether or not there are important variations in nervousness ranges amongst contributors uncovered to totally different stressors.
- Agriculture: One-way ANOVA can be utilized to find out whether or not totally different fertilizers result in considerably totally different crop yields in farming experiments.
Let’s perceive this with Agriculture instance intimately:
In agricultural analysis, one-way ANOVA might be employed to evaluate whether or not totally different fertilizers result in considerably totally different crop yields.
Fertilizer Impact on Plant Progress
Think about you’re researching the affect of various fertilizers on plant progress. You apply three sorts of fertilizer (A, B and C) to separate teams of crops. After a set interval, you measure the common top of crops in every group. You should use one-way ANOVA to check if there’s a big distinction in common top amongst crops grown with totally different fertilizers.
Step1: Null and Various Hypotheses
First step is to step up Null and Various Hypotheses:
- Null Speculation(H0): The technique of all teams are equal (there’s no important distinction in plant progress resulting from fertilizer kind)
- Various Speculation (H1): Atleast one group imply is totally different from the others (fertilizer kind has a big impact on plant progress).
Step2: Knowledge Assortment and Knowledge Group
After a set progress interval, fastidiously measure the ultimate top of every plant in all three teams. Now set up your information. Every column represents a fertilizer kind (A, B, C) and every row holds the peak of a person plant inside that group.
Step3: Calculate the group Statistics
- Compute the imply closing top for crops in every fertilizer group (A, B and C).
- Compute the entire variety of crops noticed (N) throughout all teams.
- Decide the entire variety of teams (Ok) in our case, ok=3(A, B, C)
Step4: Calculate Sum of Sq.
So Complete sum of sq., between-group sum of sq., within-group sum of sq. might be calculated.
Right here, Complete Sum of Sq. represents the entire variation in closing top throughout all crops.
Between-Group Sum of Sq. displays the variation noticed between the common heights of the three fertilizer teams. And Inside-Group Sum of Sq. captures the variation in closing heights inside every fertilizer group.
Step5: Compute Levels of Freedom
Levels of freedom outline the variety of impartial items of data used to estimate a inhabitants parameter.
- Levels of Freedom Between-Group: k-1 (variety of teams minus 1) So, right here it will likely be 3-1 =2
- Levels of Freedom Inside-Group: N-k (Complete variety of observations minus variety of teams)
Step6: Calculate Imply Squares
Imply Squares are obtained by dividing the respective Sum of Squares by levels of freedom.
- Imply Sq. Between: Between- Group Sum of Sq./Levels of Freedom Between-Group
- Imply Sq. Inside: Inside-Group sum of Sq./Levels of Freedom Inside-Group
Step7: Compute F-statistics
The F-statistic is a check statistic used to check the variation between teams to the variation inside teams. A better F-statistic suggests a doubtlessly stronger impact of fertilizer kind on plant progress.
The F-statistic for one-way Anova is calculate by utilizing this method:

Right here,
MSbetween is the imply sq. between teams, calculated because the sum of squares between teams divided by the levels of freedom between teams.
MSwithin is the imply sq. inside teams, calculated because the sum of squares inside teams divided by the levels of freedom inside teams.
- Levels of Freedom Between Teams(dof_between): dof_between = k-1
The place ok is the variety of teams(ranges) of the impartial variable.
- Levels of Freedom Inside Teams(dof_within): dof_within = N-k
The place N is the variety of observations and ok is the variety of teams(ranges) of the impartial variable.
For one-way ANOVA, whole levels of freedom is the sum of the levels of freedom between teams and inside teams:
dof_total= dof_between+dof_within
Step8: Decide Essential Worth and Resolution
Select a significance stage (alpha) for the evaluation, often 0.05 is chosen
Lookup the essential F-value on the chosen alpha stage and the calculated Levels of Freedom Between-Group and Levels of Freedom Inside-Group utilizing an F-distribution desk.
Evaluate the calculated F-statistic with the essential F-value
- If the calculated F-statistic is larger than the essential F-value, reject the null speculation(H0). This means a statistically important distinction in common plant heights among the many three fertilizer teams.
- If the calculated F-statistic is lower than or equal to the essential F-vale, fail to reject the null speculation (H0). You can’t conclude a big distinction primarily based on this information.
Step9: Put up-hoc Evaluation (if mandatory)
If the null speculation is rejected, signifying a big general distinction, you would possibly need to delve deeper. Put up -hoc like Tukey’s Truthfully Vital Distinction (HSD) can assist establish which particular fertilizer teams have statistically totally different common plant heights.
Implementation in Python:
import scipy.stats as stats
# Pattern plant top information for every fertilizer kind
plant_heights_A = [25, 28, 23, 27, 26]
plant_heights_B = [20, 22, 19, 21, 24]
plant_heights_C = [18, 20, 17, 19, 21]
# Carry out one-way ANOVA
f_value, p_value = stats.f_oneway(plant_heights_A, plant_heights_B, plant_heights_C)
# Interpretation
print("F-statistic:", f_value)
print("p-value:", p_value)
# Significance stage (alpha) - usually set at 0.05
alpha = 0.05
if p_value < alpha:
print("Reject H0: There's a important distinction in plant progress between the fertilizer teams.")
else:
print("Fail to reject H0: We can't conclude a big distinction primarily based on this pattern.")
Output:

The diploma of freedom between is Ok-1 = 3-1 =2 , the place ok represents the variety of fertilizer teams. The diploma of freedom inside is N-k = 15-3= 12,, the place N represents the entire variety of information factors.
F-Essential at dof(2,12) might be calculated from F-Distribution desk at 0.05 stage of significance.
F-Essential = 9.42
Since F-Essential < F-statistics So, we reject the null speculation which concludes that there’s important distinction in plant progress between the fertilizer teams.
With a p-value under 0.05, our conclusion stays constant: we reject the null speculation, indicating a big distinction in plant progress among the many fertilizer teams.
Two-way ANOVA
One-way ANOVA is appropriate for just one issue, however what in case you have two components influencing your experiment? Then two -way ANOVA is used which lets you analyze the results of two impartial variables on a single dependent variable.
Step1: Establishing Hypotheses
- Null speculation (H0): There’s no important distinction in common closing plant top resulting from fertilizer kind (A, B, C) or planting time (early, late) or their interplay.
- Various Speculation (H1): At the least one the next is true:
- Fertilizer kind has important impact on common closing top.
- Planting time has a big impact on common closing top.
- There’s a big interplay impact between fertilizer kind and planting time. This implies the impact of 1 issue (fertilizer) relies on the extent of the opposite issue (planting time).
Step2: Knowledge Assortment and Group
- Measure closing plant heights.
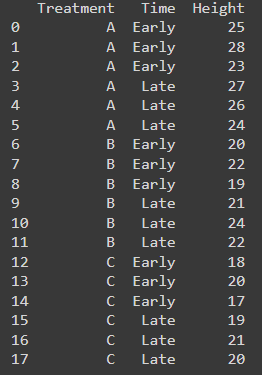
- Arrange your information right into a desk with rows representing particular person crops and columns for:
- Fertilizer kind (A, B, C)
- Planting time (early, late)
- Last top(cm)
Right here is the desk:
Step3: Calculate Sum of Sq.
Just like one-way ANOVA, you’ll have to calculate varied sums of squares to evaluate the variation in closing heights:
- Complete Sum of Sq. (SST): Represents the entire variation throughout all crops. Important impact sum of sq.:
- Between-Fertilizer Varieties (SSB_F): Displays the variation resulting from variations in fertilizer kind (averaged throughout planting occasions)
- Between-Plating Instances (SSB_T): Displays the variation resulting from variations in planting occasions (averaged throughout fertilizer varieties).
- Interplay sum of sq. (SSI): Captures the variation resulting from interplay between fertilizer kind and planting time.
- Inside-Group Sum of Squares (SSW): Represents the variation in closing heights inside every fertilizer-planting time mixture.
Step4: Compute Levels of Freedom (df):
Levels of freedom outline the variety of impartial items of data for every impact.
- dfTotal: N-1 (whole observations minus 1)
- dfFertilizer: Variety of fertilizer varieties -1
- dfPlanting Time: Variety of planting occasions -1
- dfInteraction: (Variety of fertilizer varieties -1) * (Variety of planting occasions -1)
- dfWithin: dfTotal-dfFertilizer-dfplanting-dfInteraction
Step5: Calculate Imply Squares
Divide every Sum of Sq. by its corresponding diploma of freedom.
- MS_Fertilizer: SSB_F/dfFertilizer
- MS_PlantingTime: SSB_T/dfPlanting
- MS_Interaction: SSI/dfInteraction
- MS_Within: SSW/dfWithin
Step6: Compute F-statistics
Calculate separate F-statistics for fertilizer kind, planting time, and interplay impact:
- F_Fertilize: MS_Fertilizer/MS_Within
- F_PlantingTime: MS_PlantingTime/ MS_Within
- F_Interaction: MS_Inteaction/MS_Within
- F_PlantingTime: MS_PlantingTime/MS_Within
- F_Interaction: MS_Interaction/ MS_Within
Step7: Decide Essential Values and Resolution:
Select a significance stage (alpha) on your evaluation, often we take 0.05
Lookup essential F-values for every impact (fertilizer, planting time, interplay) on the chosen alpha stage and their respective levels of freedom utilizing an F-distribution desk or statistical software program.
Evaluate your calculated F-statistics to the essential F-values for every impact:
- If the F-statistic is larger than the essential F-value, reject the null speculation(H0) for that impact. This means a statistically important distinction.
- If the F-statistic is lower than or equal to the essential F-value fail to reject H0 for that impact. This means a statistically insignificant distinction.
Step8: Put up-hoc Evaluation (if mandatory)
If the null speculation is rejected, signifying a big general distinction, you would possibly need to delve deeper. Put up -hoc like Tukey’s Truthfully Vital Distinction (HSD) can assist establish which particular fertilizer teams have statistically totally different common plant heights.
import pandas as pd
import statsmodels.api as sm
from statsmodels.method.api import ols
# Create a DataFrame from the dictionary
plant_heights = {
'Therapy': ['A', 'A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C', 'C'],
'Time': ['Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late'],
'Peak': [25, 28, 23, 27, 26, 24,
20, 22, 19, 21, 24, 22,
18, 20, 17, 19, 21, 20]
}
df = pd.DataFrame(plant_heights)
# Match the ANOVA mannequin
mannequin = ols('Peak ~ C(Therapy) + C(Time) + C(Therapy):C(Time)', information=df).match()
# Carry out ANOVA
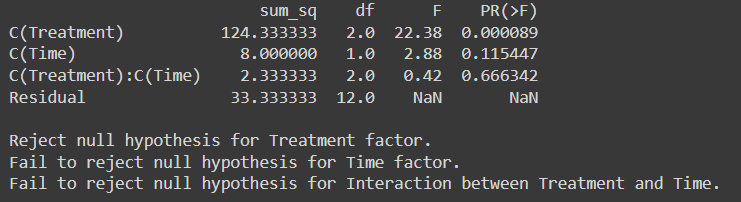
anova_table = sm.stats.anova_lm(mannequin, typ=2)
# Print the ANOVA desk
print(anova_table)
# Interpret the outcomes
alpha = 0.05 # Significance stage
if anova_table['PR(>F)'][0] < alpha:
print("nReject null speculation for Therapy issue.")
else:
print("nFail to reject null speculation for Therapy issue.")
if anova_table['PR(>F)'][1] < alpha:
print("Reject null speculation for Time issue.")
else:
print("Fail to reject null speculation for Time issue.")
if anova_table['PR(>F)'][2] < alpha:
print("Reject null speculation for Interplay between Therapy and Time.")
else:
print("Fail to reject null speculation for Interplay between Therapy and Time.")
Output:
{kind=link}
F-critical worth for Therapy at diploma of freedom (2,12) at 0.05 stage of significance from F-distribution desk is 9.42
F-critical worth for Time at diploma of freedom (1,12) at 0.05 stage of significance is 61.22
F- essential worth for interplay between therapy and Time at 0.05 stage of significance at diploma of freedom (2,12) is 9.42
Since F-Essential < F-statistics So, we reject the null speculation for Therapy Issue.
However for Time Issue and Interplay between Therapy and Time issue we did not reject the Null Speculation as F-statistics worth > F-Essential worth
With a p-value under 0.05, our conclusion stays constant: we reject the null speculation for Therapy Issue whereas with a p-value above 0.05 we fail to reject the Null speculation for Time issue and interplay between Therapy and Time issue.
Distinction Between One- means ANOVA and TWO- means ANOVA
One-way ANOVA and Two-way ANOVA are each statistical methods used to investigate variations amongst teams, however they differ by way of the variety of impartial variables they take into account and the complexity of the experimental design.
Listed here are the important thing variations between one-way ANOVA and two-way ANOVA:
| Facet | One-way ANOVA | Two-way ANOVA |
|---|---|---|
| Variety of Variables | Analyzes one impartial variable (issue) on a steady dependent variable | Analyzes two impartial variables (components) on a steady dependent variable |
| Experimental Design | One categorical impartial variable with a number of ranges (teams) | Two categorical impartial variables (components), typically labeled as A and B, with a number of ranges. Permits examination of principal results and interplay results |
| Interpretation | Signifies important variations amongst group means | Gives data on principal results of things (A and B) and their interplay. Helps assess variations between issue ranges and interdependency |
| Complexity | Comparatively easy and straightforward to interpret | Extra complicated, analyzing principal results of two components and their interplay. Requires cautious consideration of issue relationships |
Conclusion
ANOVA is a robust software for analyzing variations amongst group means, important when evaluating greater than two pattern averages. One-way ANOVA assesses the affect of a single issue on a steady end result, whereas two-way ANOVA extends this evaluation to think about two components and their interplay results. Understanding these variations permits researchers to decide on essentially the most appropriate analytical method for his or her experimental designs and analysis questions.
Ceaselessly Requested Questions
A. ANOVA stands for Evaluation of Variance, a statistical methodology used to investigate variations amongst group means. It’s used when evaluating means throughout three or extra teams to find out if there are important variations.
A. One-way ANOVA is used when you might have one categorical impartial variable (issue) with a number of ranges and also you need to examine the means of those ranges. For instance, evaluating the effectiveness of various therapies on a single end result.
A. Two-way ANOVA is used when you might have two categorical impartial variables (components) and also you need to analyze their results on a steady dependent variable, in addition to the interplay between the 2 components. It’s helpful for learning the mixed results of two components on an end result.
A. The p-value in ANOVA signifies the chance of observing the info if the null speculation (no important distinction amongst group means) have been true. A low p-value (< 0.05) suggests that there’s important proof to reject the null speculation and conclude that there are variations among the many teams.)
A. The F-statistic in ANOVA measures the ratio of the variance between teams to the variance inside teams. A better F-statistic signifies that the variance between teams is bigger relative to the variance inside teams, suggesting a big distinction among the many group means.