{kind=link}

(issaro prakalung/Shutterstock)
Massive language fashions (LLMs) hallucinate. There’s simply no means round that, due to how they’re designed and elementary limitations on information compression as expressed within the Shannon Info Theorem, says Vectara CEO Amr Awadallah. However there are methods across the LLM hallucination drawback, together with one by Vectara that makes use of retrieval-augmented era (RAG), amongst different strategies.
MIT professor Claude Shannon, who died in 2001, is called the Father of Info Idea due to his intensive contributions to the fields of arithmetic, pc science, electrical engineering, and cryptography. Considered one of his observations, revealed in his seminal paper “A Mathematical Idea of Communication” (typically known as the “Magna Carta of the Info Age”) was there are inherent limits to how a lot information will be compressed earlier than it begins to lose its which means.
Awadallah explains:
“The Shannon Info Theorem proves for sure that the utmost you may compress textual content, the utmost, is 12.5%,” he says. “In the event you compress it past 12.5%, then you definately’re now in what’s known as lossy compression zone, versus lossless zone.”

MIT Professor Claude Shannon is called the Father of Info Idea (Picture courtesy Tekniska Museet/Wikipedia)
The factor is, LLMs go means past that 12.5%, or compressing eight phrases into storage designed to suit one uncompressed phrase. That leads LLMs into the lossy compression zone and, thus, imperfect recall.
“In a nutshell, they hallucinate as a result of we compress information an excessive amount of once we stuff information within them,” Awadallah says.
A few of at this time’s LLMs take about one trillion phrases and stuff it into an area with a billion parameters, which represents a 1,000x compression charge, Awadallah says. A number of the largest ones, akin to GPT-4, do considerably higher and are compressing charges at about 100x, he says.
One easy technique to cut back hallucinations is simply cram much less information into LLMs–successfully prepare the LLMs on smaller information units–and get the compression charge above that 12.5% wanted for textual content, Awadallah says.
But when we did that, the LLMs wouldn’t be as helpful. That’s as a result of we’re not coaching LLMs to have good recall of knowledge, however to know the underlying ideas mirrored within the phrases, he says.
It’s a bit like educating a physicist, the Cloudera co-founder says. As a school scholar, the coed is uncovered to scientific formulation, however he isn’t drilled endlessly with rote memorization. Crucial ingredient of the physicist’s training is greedy the important thing ideas of the bodily world. Throughout exams, the physics scholar could have open-book entry to scientific formulation as a result of the physics instructor understands {that a} scholar might sometimes neglect a system even whereas demonstrating understanding of key physics ideas.
Having open guide exams, versus requiring good recall, is a part of the answer to LLM hallucinations, Awadallah says. An open guide check, as carried out with RAG strategies that carry further information to the LLM, offers one test towards an LLM’s tendency to make issues up.
“RAG in a nutshell is about this open guide factor,” he says. “We inform [the LLM] ‘Your job now’s to reply this query, however solely use these information.’”
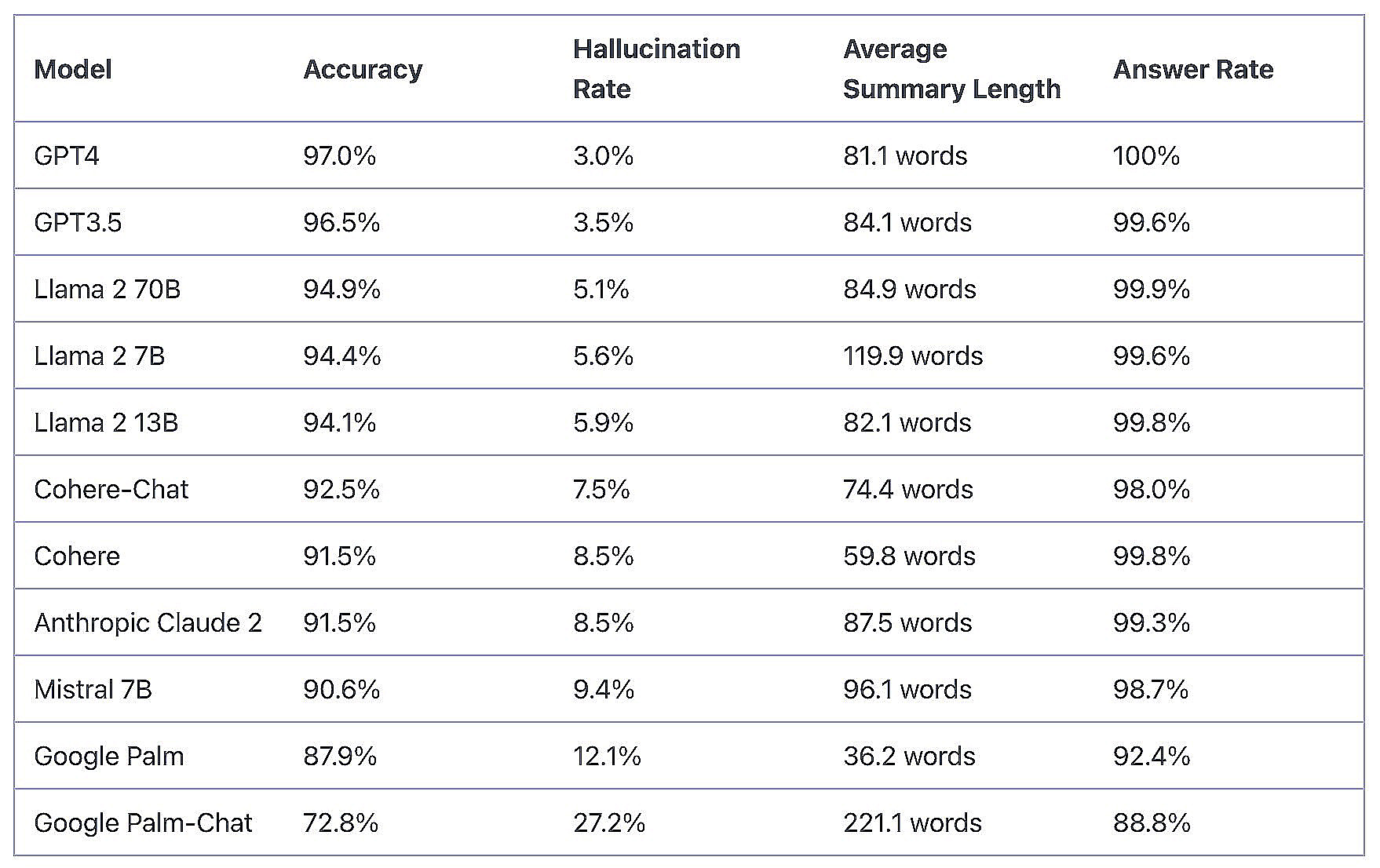
Vectara Hallucination Leaderboard (picture courtesy Vectara)
The parents at Vectara hoped this “sandboxing” approach can be sufficient to carry the hallucination charge to zero. They quickly discovered that, whereas it decreased the hallucination charge considerably, it didn’t totally remove hallucinations. Utilizing Vectara’s RAG answer, the hallucination charge for GPT-4, for instance, dropped to three%, which is best however nonetheless not ample for manufacturing. Llama-2 70B had a 5.1% hallucination charge, whereas Google Palm made stuff up about 12% of the time, based on Vectara’s Hallucination Leaderboard.
“They nonetheless can interject,” Awadallah says. “Whereas all of those information are appropriate, uncompressed, extremely [relevant] information, they will nonetheless make up one thing.”
Eliminating the remaining fib charge required one other approach: the creation of a novel LLM designed particularly to detect hallucinations.
Like a human fact-checker, the Vectara LLM, dubbed Boomerang, generates a rating that corresponds with the probability that an LLM’s reply is made up.
“It provides you a rating that claims ‘This response is 100% factual. It didn’t transcend what the information have been’ versus ‘This response is a bit off. A human ought to learn it’ versus ‘This response is totally dangerous, you need to throw this away. That is utterly a fabrication,’” Awadallah says.
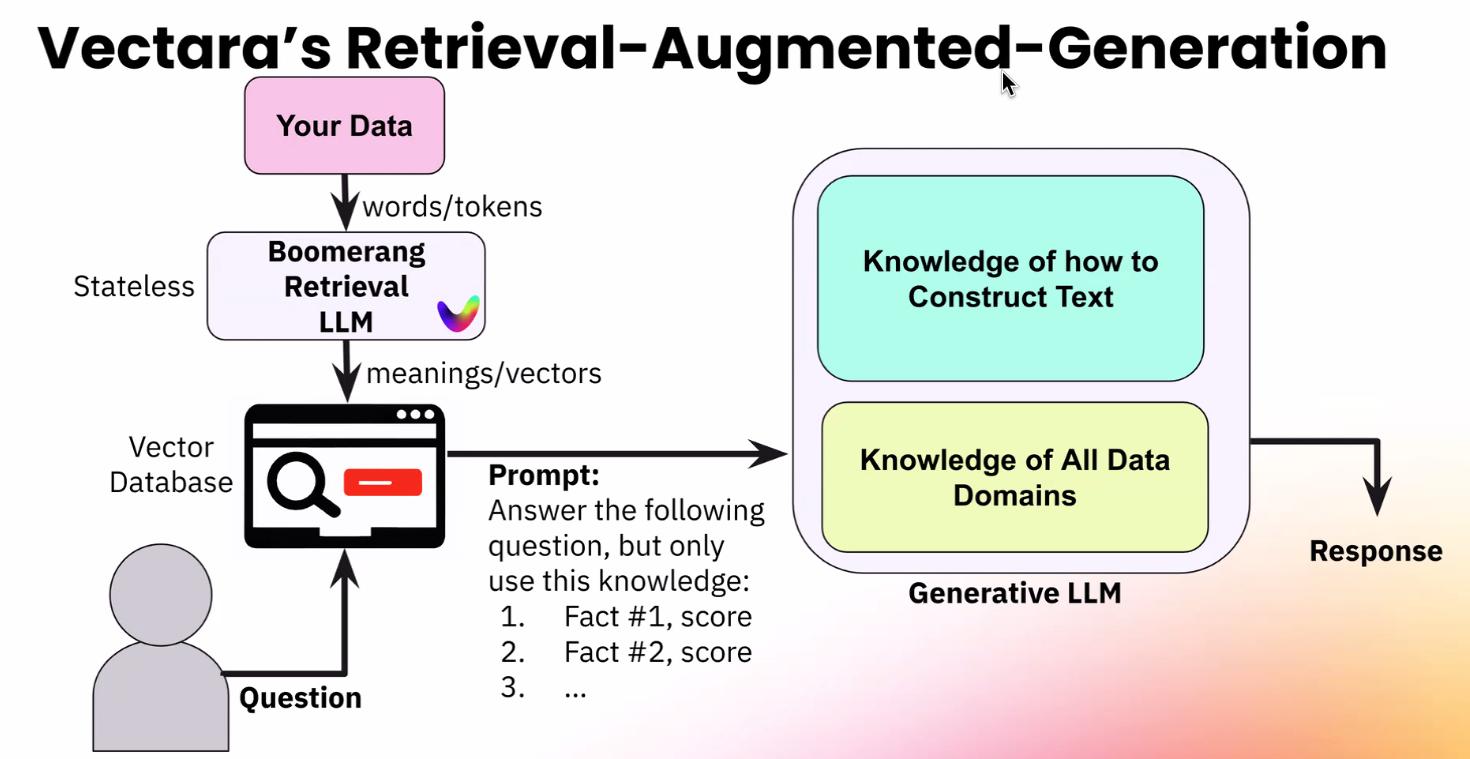
Vectara’s GenAI stack (Picture courtesy Vectara)
One cause that Boomerang is best at reality checking than, say GPT-4 itself, is that it was designed particularly to be a fact-checking LLM. One more reason is that it’s educated on an organization’s personal information. The shopper will get to outline the information that the mannequin makes use of to find out truthfulness. This information is then saved in one other compoent of Vectara’s solutoin: a homegrown vector database.
“What that vector database is doing is it’s storing your authentic content material–the textual content you had–nevertheless it’s additionally storing the meanings behind the content material” as vector embeddings, Awadallah says. “We’re very specialised for you in context, and what you could have in a company that runs a enterprise.”
Vectra’s full answer, which runs solely within the cloud, contains Boomerang, its “RAG in a field,” and a vector database operating subsequent to an LLM. Any unstructured textual content, from Phrases docs and PDFs to paper-based information run by optical character recognition (OCR), can function enter for coaching the mannequin.
Vectara provides prospects the selection of utilizing both GPT-4 or Mistral 7B, operating within the cloud as a managed service or within the buyer’s personal VPC. (The options are solely out there within the cloud; Awadallah received his fill of sustaining on-prem software program with Cloudera).

Amr Awadallah is the CEO and founding father of Vectara
Which LLM a buyer chooses depends upon what they’re making an attempt to do, and their consolation stage with sending information to OpenAI.
“Mistral 7B is of the perfect fashions on the planet proper now. It’s dimension is small so it’s actually quick and it does very well on common,” he says. “We host that mannequin ourselves for our prospects. Or if they want us to name out to GPT-4, we are able to name out to GPT-4 as nicely.” Meta’s Llama-2 will probably be added sooner or later, he says.
The purpose for Vectara, which Awadallah based in 2020 earlier than the ChatGPT ignited the AI craze, is to allow corporations to create their very own chatbots and conversational interfaces. Awadallah acknowledges there are tons of of startups and established tech companies chasing this data goldmine, however insists that Vectara has constructed an answer that addresses the hallucination concern–in addition to different issues akin to defending towards immediate injection assaults–in a means that places the corporate forward of the curve.
Since launching its GA product final April, Vectara has obtained 18,000 signups, a quantity that’s rising by 500 to 700 per week, Awadallah says. Among the many corporations which might be utilizing Vectara embody an ultrasound producer that needed to automate machine configuration primarily based on the distillation of professional finest practices and a wealth advisory agency that needed to supply non-hallucinated monetary recommendation.
Whereas the GenAI revolution is peeking executives’ pursuits, it’s additionally making a headwind for corporations like Vectara, Awadallah says.
“I believe ChatGPT helped lots, nevertheless it provides companies a pause,” he says. “Once they noticed these hallucinations, they’re undecided they will use this. However now they’re coming again. They’re seeing the answer out there like ours, they will really maintain that hallucination beneath management.”
Associated Objects:
What’s Holding Up the ROI for GenAI?
Why A Unhealthy LLM Is Worse Than No LLM At All
Are We Underestimating GenAI’s Impression?