{kind=link}
Introduction
Changing pure language queries into code is without doubt one of the hardest challenges in NLP. The power to vary a easy English query into a fancy code opens up plenty of potentialities in developer productiveness and a fast software program improvement lifecycle. That is the place Google Gemma, an Open Supply Giant Language Mannequin comes into play. This information will discover methods to fine-tune Google’s Gemma with unsloth for producing code statements from pure language queries.

Studying Targets
- Perceive the significance of code era from pure language for developer effectivity.
- Study Google Gemma and its function in reworking English queries into code.
- Discover Unsloth’s effectivity enhancements and reminiscence administration for Giant Language Fashions.
- Arrange the atmosphere for fine-tuning Google Gemma with Unsloth effectively.
- Put together datasets appropriate with Gemma and Unsloth for efficient fine-tuning.
- Grasp fine-tuning Google Gemma with particular coaching arguments utilizing SFTTrainer.
- Generate code from pure language prompts utilizing fine-tuned Gemma.
- Consider the efficiency of fine-tuned Gemma in software program improvement workflows.
This text was revealed as part of the Information Science Blogathon.
Introduction to Gemma
Google developed a set of Open-Supply Giant Language Fashions referred to as Google Gemma. It was skilled with 6T textual content tokens primarily based on Google’s Gemini fashions. These are regarded to be the Gemini fashions‘ lighter variants. There are two sizes within the Gemma household: a 2 billion parameter mannequin for CPU and on-device functions, and a 7 billion parameter mannequin for efficient deployment on GPU and TPU.
Gemma has cutting-edge comprehension and reasoning means at scale together with excessive expertise in textual content domains. It outperforms different open fashions in a wide range of classes, which embrace query answering, commonsense reasoning, arithmetic, and science at matchable or larger scales. Google releases fine-tuned checkpoints and an open-source codebase for inference and serving for each fashions. On this information, we are going to work with the 7 Billion Parameter model of Gemma.
What’s Unsloth?
Daniel and Michael Han crafted Unsloth, which shortly emerged because the optimized framework tailor-made to refine the fine-tuning course of for big language fashions (LLMs). Famend for its swiftness and reminiscence effectivity, Unsloth can fasten as much as 30x coaching velocity and with a notable 60% discount in reminiscence utilization. These spectacular metrics have rendered it a goto framework for the builders searching for to fine-tune LLMs with precision and velocity.
Notably, Unsloth accommodates completely different {Hardware} Setups, spanning from NVIDIA GPUs like Tesla T4 to H100, and extends its compatibility to AMD and Intel GPUs. The library’s adaptability shines by its incorporation of pioneering methods which embrace clever weight upcasting, a function that curtails the need for upscaling weights throughout QLoRA, thereby optimizing reminiscence utilization. Moreover, Unsloth leverages bfloat16 swiftly, enhancing the soundness of 16-bit coaching and expediting QLoRA fine-tuning.
As an open-source software licensed underneath Apache 2.0, Unsloth built-in seamlessly into fine-tuning outstanding LLMs like Mistral 7B, Llama, and Google Gemma displaying as much as a facet of 5x acceleration in fine-tuning velocity whereas concurrently slashing reminiscence consumption by 60%. Furthermore, its compatibility extends to various fine-tuning strategies like Flash-Consideration 2, which not solely accelerates inference however even fine-tuning processes.
Setting Up the Surroundings
The very first thing is to organize the Python atmosphere by downloading and putting in the mandatory libraries. We will probably be engaged on Google Collab to Finetune the Gemma LLM. To take action, we are going to observe the next instructions
!pip set up "unsloth[colab] @ git+https://github.com/unslothai/unsloth.git"- This installs the unsloth library within the Colab atmosphere. The [colab] beside the unsloth particularly tells the pip installer to put in different libraries that assist unsloth within the Google Colab atmosphere.
- This even installs the datasets and the transformers library from HuggingFace.
# Import the FastLanguageModel class from the unsloth library.
from unsloth import FastLanguageModel
# Import the torch library.
import torch
# Set the utmost sequence size to 8192 tokens.
max_seq_length = 8192
# Set the information kind to None for automated detection.
dtype = None
# Set the load_in_4bit flag to True to load the mannequin weights in 4-bit precision.
load_in_4bit = True- The FastLanguageModel class from the unsloth library supplies an optimized implementation of huge language fashions for Google Colab.
- max_seq_length tells the utmost variety of tokens the mannequin can course of in a single sequence. The max sequence size for Gemma is 8192 and therefore initializing the identical.
- dtype tells the information kind to make use of for the mannequin’s weights and activations.
- load_in_4bit setting to true will load the mannequin weights in 4-bit precision. This may save reminiscence and enhance efficiency on some GPUs, however could even cut back accuracy barely.
Downloading 4-bit Quantized Mannequin and Including LoRA Adapters
On this part, we are going to begin off by first downloading the Gemma Mannequin:
# Load the pre-trained mannequin from the 'unsloth/gemma-7b-bnb-4bit' repository.
mannequin, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gemma-7b-bnb-4bit",
# Set the utmost sequence size to the worth outlined earlier.
max_seq_length = max_seq_length,
# Set the information kind to the worth outlined earlier.
dtype = dtype,
# Set the load_in_4bit flag to the worth outlined earlier.
load_in_4bit = load_in_4bit,
)
- This code works with the from_pretrained() technique of the FastLanguageModel class to load a pre-trained mannequin from the Hugging Face mannequin hub.
- The model_name argument tells the identify of the mannequin that we have to load.
- The max_seq_length, dtype, and load_in_4bit arguments are handed to the constructor of the FastLanguageModel class. These are the parameters that we’ve already outlined.
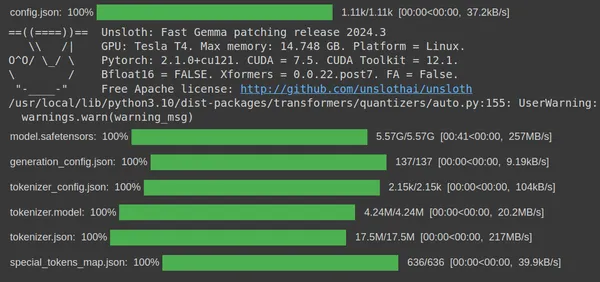
We will see that after operating the code, the code will obtain the gemma-7b 4-bit quantized model from the unsloth huggingface hub current in HuggingFace. Lastly, the obtain of the quantized mannequin step is accomplished. Now we have to create a LoRA for this in order that we are able to solely prepare a subset of those parameters.
The code for that is as follows:
# Create a PEFT mannequin with the given parameters
mannequin = FastLanguageModel.get_peft_model(
mannequin,
r=16, # LoRa Rank
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing=True
)
- The r parameter determines the rank of the LoRA projection matrix. It controls the variety of parameters wanted for fine-tuning. Extra parameters and possibly improved efficiency observe from a better rank, however the mannequin’s reminiscence footprint could even develop
- The lora_alpha choice units the size of the LoRA projection matrix. This parameter permits for adjusting the Studying Charge throughout the fine-tuning course of.
- The LoRA projection matrix’s dropout price is informed by the lora_dropout choice. This parameter is to scale back overfitting and enhance the mannequin’s capability for generalization. Nonetheless, for Unsloth optimization, it’s set to 0.
- The bias parameter determines whether or not to incorporate a Bias Part within the LoRA projection matrix. Setting it to ‘none’ means no bias time period will probably be utilized.
- The use_gradient_checkpointing variable is about to True to leverage Gradient Checkpointing. Doing it will velocity up the coaching course of
Lastly operating this code will create the LoRA adapters for the Gemma 7B mannequin which we are able to work with to fine-tune the mannequin on several types of dataset.
Making ready the Dataset for Superb-tuning
Now, we are going to obtain the dataset and put together it for fine-tuning. For this information, for producing codes, we are going to go together with the Token Bender Code Directions dataset. This dataset follows alpaca tyle chat formatting. The dataset appears to be like just like the one beneath:

We work with primarily 3 columns, the Enter, Instruction, and the Output Column. With these 3 columns, we prepare it in an alpaca-style format and prepare the Gemma Giant Language Mannequin on this knowledge. First, let’s outline a helper perform that takes in every row of this knowledge and converts it to an alpaca-style format.
def formatted_train(x):
if x['input']:
formatted_text = f"""Beneath is an instruction that describes a process.
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Enter:
{x['input']}
### Response:
{x['output']}<eos>"""
else:
formatted_text = f"""Beneath is an instruction that describes a process.
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Response:
{x['output']}<eos>"""
return formatted_textThe perform takes in every row of the dataset and returns it within the corresponding Alpaca format:
- The perform takes a single argument, x, which represents a row of a DataFrame.
- It checks whether or not the worth within the ‘enter’ column of the DataFrame row is true (if x[‘input’]:). Whether it is, it proceeds to create a formatted textual content block utilizing f-strings.
- If the ‘enter’ column is true, it constructs a formatted textual content block containing an instruction, enter, and response, separated by markdown headings (###) for every part. It consists of the instruction from the ‘instruction’ column, the enter from the ‘enter’ column, and the output from the ‘output’ column.
- If the ‘enter’ column is just not truthy (empty or evaluates to False), it constructs an identical formatted textual content block however with out together with the enter part.
- In each instances, the formatted textual content block has an appended (finish of sentence) marker on the finish.
- Lastly, the perform returns the constructed formatted textual content block.
Operate to Obtain Dataset from HuggingFace
Subsequent, we create a perform to obtain the dataset from HuggingFace and rework the dataset with the next formatting.
from datasets import load_dataset, Dataset
def prepare_train_data(data_id):
knowledge = load_dataset(data_id, cut up="prepare")
data_df = knowledge.to_pandas()
data_df["formatted_text"] = data_df[["input", "output",
"instruction"]].apply(formatted_train, axis=1)
knowledge = Dataset.from_pandas(data_df)
return knowledge
data_id = "TokenBender/code_instructions_122k_alpaca_style"
knowledge = prepare_train_data(data_id)- The load_dataset perform hundreds the dataset from the required dataset ID and splits.
- The to_pandas technique converts the dataset to a pandas dataframe.
- The apply technique applies the lambda perform to every row within the dataframe.
- The lambda perform takes the instruction, enter, and output columns from every row and passes them to the formatted_train perform.
- The formatted_train perform returns the formatted chat template string in Alpaca format, which we then retailer within the new ‘formatted_text’ column.
- The Dataset.from_pandas technique converts the dataframe again to a Dataset object.
After which we lastly move the data_id to the prepare_train_data perform. We obtain the dataset from HuggingFace, apply the required adjustments to every row, after which save the ensuing Alpaca-format textual content within the ‘formatted_text’ column of the dataset.
With this, we’ve accomplished the preparation of the code dataset for fine-tuning.
Superb-tuning Google Gemma for Code Dataset
We now have entry to the dataset for fine-tuning. On this part, we are going to begin off by defining the coaching arguments and eventually fine-tune the mannequin. The beneath code defines the coaching arguments for fine-tuning Google Gemma Giant Language Mannequin:
from trl import SFTTrainer
from transformers import TrainingArguments
coach = SFTTrainer(
mannequin = mannequin,
tokenizer = tokenizer,
train_dataset = knowledge,
dataset_text_field = "formatted_text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 10,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "paged_adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)The supplied code snippet configures coaching arguments for the Giant Language Mannequin utilizing the TrainingArguments class from the Transformers library. These arguments Outline completely different parameters that management the coaching course of. Then passes them together with different Coach parameters to the SFTTrainer class.
Breakdown of Key Arguments
Right here’s a breakdown of the important thing arguments for the TrainingArguments:
- per_device_train_batch_size: This tells the variety of coaching examples processed per system (e.g., GPU) throughout every coaching step. Right here, it’s set to 2, that means 2 examples will probably be processed per system in every step.
- gradient_accumulation_steps: This defines the variety of Grad Accumulation steps earlier than performing a parameter replace. It successfully will increase the batch measurement by accumulating gradients over a number of steps. Right here, it’s set to 4, that means gradients will probably be amassed over 4 steps earlier than updating the mannequin parameters.
- warmup_steps: This units the variety of warm-up steps throughout coaching, regularly rising the Studying Charge from 0 to the supplied worth. Right here, it’s set to five, so the Studying Charge will linearly enhance over the primary 5 steps.
- max_steps: This defines the overall variety of coaching steps to carry out. Right here, it’s set to 50, that means the coaching will cease after 50 steps.
- learning_rate: This tells the primary Studying Charge used for coaching. Right here, it’s set to 2e-4 (2 multiplied by 10 to the ability of -4).
- fp16 and bf16: These arguments management the precision used for coaching. fp16 is for half-precision (16-bit) coaching if the GPU helps it, whereas bf16 is for bfloat16 coaching if supported.
- logging_steps: This units the interval at which coaching metrics and losses are logged. We set it to 1, so logs are printed after each coaching step.
- optim: This tells the optimizer to make use of for coaching. Right here, we set it to ‘paged_adamw_8bit’, a specialised optimizer for memory-efficient coaching.
- weight_decay: This defines the load Decay Charge that we want for regularization. Right here, it’s set to 0.01.
- lr_scheduler_type: This tells what Studying Charge Scheduler to make use of throughout coaching.
Passing Coaching Arguments
Lastly, we’re achieved creating our Coaching Arguments. We move these Coaching Arguments to the SFTTrainer, to the args variable. Aside from the TrainingArguments, we even move within the beneath parameters:
- mannequin: This tells the mannequin to be skilled. In our code, it’s the mannequin variable outlined earlier.
- tokenizer: This tells the tokenizer used to course of the textual content knowledge. Right here, it’s the tokenizer variable outlined earlier.
- train_dataset: This tells the coaching dataset, which is the information variable containing formatted textual content knowledge.
- dataset_text_field: This tells the identify of the sector within the dataset that incorporates the formatted textual content. Right here, it’s “formatted_text”.
- max_seq_length: This defines the utmost sequence size for the enter and output sequences. Right here, it’s set to max_seq_length, which is a variable outlined earlier.
- dataset_num_proc: This tells the variety of staff to work with to tokenize the information. Listed below are giving it a worth of two.
- packing: This can be a boolean flag that tells if we must always use sequence packing throughout coaching. It’s set to false as a result of we’re coping with bigger sequences of information.
- args: This tells the coaching arguments object created earlier, which incorporates completely different coaching parameters.
We’re lastly achieved with defining our Coach for coaching our quantized Gemma 7B Giant Language Mannequin. Now we are going to run the coach to begin the coaching course of. To do that, we write the beneath command:
trainer_stats = coach.prepare()Operating the above will begin the coaching course of. It may well take as much as half-hour within the Google Colab to coach this mannequin. Lastly, after half-hour, the mannequin will probably be fine-tuned on the Code Dataset:
Producing Code with Gemma
Now, we are going to take a look at the fine-tuned Gemma 7B that’s skilled on the Code Dataset. Earlier than that, let’s outline some helper features that can allow us to create the Immediate in Alpaca Format.
def format_test(x):
if x['input']:
formatted_text = f"""Beneath is an instruction that describes a process.
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Enter:
{x['input']}
### Response:
"""
else:
formatted_text = f"""Beneath is an instruction that describes a process.
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Response:
"""
return formatted_textThis perform format_test() may be very a lot much like the perform that we’ve outlined throughout our Dataset processing stage. The one distinction right here is that we solely take within the enter and instruct., from the information this time and go away the output in order that the mannequin will generate it.
Let’s attempt to visualize an instance Immediate with this perform:
Immediate = format_test(knowledge[155])
print(Immediate)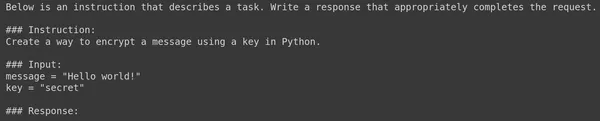
Now let’s take within the fine-tuned mannequin, give this enter, and see what output it generates.
Python Code Implementation
from transformers import TextStreamer
FastLanguageModel.for_inference(mannequin) # Allow native 2x quicker inference
inputs = tokenizer(
[
Prompt
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = mannequin.generate(**inputs, streamer = text_streamer, max_new_tokens = 512)
- Imports the TextStreamer class from the transformers library. TextStreamer is used to generate textual content incrementally, one token at a time.
- Allows quicker inference for the language mannequin utilizing FastLanguageModel.for_inference(mannequin).
- Then we tokenize the supplied Immediate with the pre-trained tokenizer. The Tokenized Immediate is then transformed right into a PyTorch tensor and moved to the GPU.
- Then we initialize a TextStreamer object with the identical tokenizer.
- We generate new textual content by offering the text_streamer, enter, and the utmost new tokens to the mannequin.generate() perform.
- Operating this code will Stream the output generated by the Giant Language Mannequin. It has given the next consequence.
Operating this code will stream the output generated by the Giant Language Mannequin. It has given the next consequence:
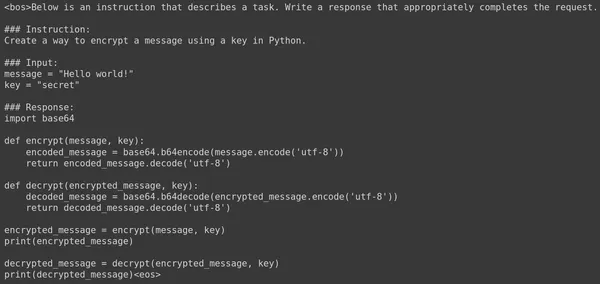
We see that the mannequin has generated the next code:
import base64
def encrypt(message, key):
encoded_message = base64.b64encode(message.encode('utf-8'))
return encoded_message.decode('utf-8')
def decrypt(encrypted_message, key):
decoded_message = base64.b64decode(encrypted_message.encode('utf-8'))
return decoded_message.decode('utf-8')
message = "Hi there World!"
key = "secret"
encrypted_message = encrypt(message, key)
print(encrypted_message)
decrypted_message = decrypt(encrypted_message, key)
print(decrypted_message)This code generated by the Gemma 7B LLM works completely nice. Let’s strive asking one other query and see the response generated. Beneath is one other Immediate and its respective reply generated by the fine-tuned Gemma 7B Giant Langage Mannequin.

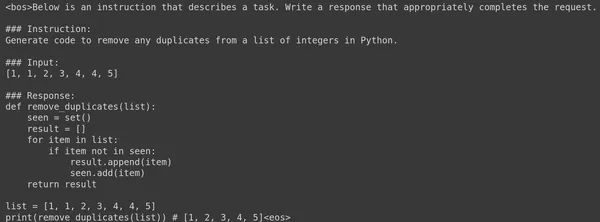
Beneath is the code generated by the Giant Language Mannequin for the supplied Immediate:
def remove_duplicates(record):
seen = set()
consequence = []
for merchandise in record:
if merchandise not in seen:
consequence.append(merchandise)
seen.add(merchandise)
return consequence
record = [1, 1, 2, 3, 4, 4, 5]
print(remove_duplicates(record)) # [1, 2, 3, 4, 5]
Even the above code works completely nice. We see that fine-tuning Google Gemma 7B Giant Language Mannequin in simply 60 steps has resulted in an excellent code-generating mannequin. The LLM is even in a position to perceive the formatting accurately and generate the response in the identical Alpaca format.
Conclusion
The mixing of Google’s Gemma with Unsloth for code era from pure language queries has proven potential in enhancing developer productiveness. Gemma, a strong Giant Language Mannequin, can convert English queries into complicated code statements, whereas Unsloth improves coaching effectivity and reminiscence utilization. This synergy enhances code era capabilities in Pure Language Processing (NLP) functions, fostering new methods and enhancing software program improvement effectivity.
Key Takeaways
- Google Gemma, supplies nice Language Comprehension and Reasoning Talents, making it a fantastic alternative for code-generation duties.
- Unsloth, an optimized library for fine-tuning Giant Language Fashions, enormously boosts coaching velocity reduces reminiscence, and will increase general effectivity.
- Creating the atmosphere includes putting in vital libraries and configuring parameters just like the sequence size and knowledge kind.
- Superb-tuning Google Gemma with supplied coaching arguments and dealing with the SFTTrainer class facilitates environment friendly mannequin coaching on code datasets.
- Producing code with fine-tuned Gemma includes offering Prompts in Alpaca format and dealing with the TextStreamer class for incremental textual content era.
- Sensible examples present the efficacy of the fine-tuned Gemma 7B mannequin in precisely producing code responses from Pure Language Prompts, displaying its potential in enhancing software program improvement workflows.
Continuously Requested Questions
A. Google Gemma is a household of open-source massive language fashions (LLMs). These fashions are lighter variants of Google’s Gemini fashions and exhibit good Comprehension and Reasoning Talents. Gemma’s capabilities span varied duties like query answering, code era, and extra.
A. Unsloth, an optimized library, accelerates and improves the effectivity of LLM fine-tuning. It supplies nice velocity and reminiscence enhancements, making it the go-to alternative for fine-tuning fashions like Gemma.
A. The Token Bender Code Directions dataset incorporates directions and corresponding code outputs in an Alpaca-style chat format.
A. The dataset is first transformed into an Alpaca-style format, the place every row consists of an Instruct., an Enter, and the specified code output. This format helps the mannequin study the connection between pure language directions and code.
A. Outline a number of coaching arguments: Batch Dimension, Gradient Accumulation Steps, Studying Charge, and the variety of coaching steps. These parameters management how the mannequin learns from the information.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Creator’s discretion.