{kind=link}
We launched Ray help public preview final 12 months and since then, lots of of Databricks prospects have been utilizing it for number of use circumstances comparable to multi-model hierarchical forecasting, LLM finetuning, and Reinforcement studying. Immediately, we’re excited to announce the final availability of Ray help on Databricks. Ray is now included as a part of the Machine Studying Runtime ranging from model 15.0 onwards, making it a first-class providing on Databricks. Prospects can begin a Ray cluster with none extra installations, permitting you to get began utilizing this highly effective framework throughout the built-in suite of merchandise that Databricks has to supply, comparable to Unity Catalog, Delta Lake, MLflow, and Apache Spark
A Harmonious Integration: Ray and Spark on Databricks
The final availability of Ray on Databricks expands the selection of operating distributed ML AI workloads on Databricks and new Python workloads. It creates a cohesive ecosystem the place logical parallelism and knowledge parallelism thrive collectively. Ray enhances Databricks’ choices by providing a further, different logical parallelism strategy to processing Python code that isn’t as closely depending on knowledge partitioning as ML workloads which can be optimized for Spark are.
One of the crucial thrilling facets of this integration lies within the interoperability with Spark DataFrames. Historically, transitioning knowledge between completely different processing frameworks might be cumbersome and resource-intensive, usually involving expensive write-read cycles. Nonetheless, with Ray on Databricks, the platform facilitates direct, in-memory knowledge transfers between Spark and Ray, eliminating the necessity for intermediate storage or costly knowledge translation processes. This interoperability ensures that knowledge will be manipulated effectively in Spark after which handed seamlessly to Ray, all with out leaving the data-efficient and computationally wealthy setting of Databricks.
“At Marks & Spencer, forecasting is on the coronary heart of our enterprise, enabling use circumstances comparable to stock planning, gross sales probing, and provide chain optimization. This requires strong and scalable pipelines to ship our use circumstances. At M&S, we have harnessed the ability of Ray on Databricks to experiment and ship production-ready pipelines from mannequin tuning, coaching, and prediction. This has enabled us to confidently ship end-to-end pipelines utilizing Spark’s scalable knowledge processing capabilities with Ray’s scalable ML workloads.”
— Joseph Sarsfield, Senior ML Engineer, Marks and Spencer
Empowering New Purposes with Ray on Databricks
The combination between Ray and Databricks opens doorways to a myriad of purposes, every benefiting from the distinctive strengths of each frameworks:
- Reinforcement Studying: Deploying superior fashions for autonomous autos and robotics, profiting from Ray’s distributed computing utilizing RLlib.
- Distributed Customized Python Purposes: Scaling customized Python purposes throughout clusters for duties requiring advanced computation.
- Deep Studying Coaching: Providing environment friendly options for deep studying duties in laptop imaginative and prescient and language fashions, leveraging Ray’s distributed nature.
- Excessive-Efficiency Computing (HPC): Addressing large-scale duties like genomics, physics, and monetary calculations with Ray’s capability for high-performance computing workloads.
- Distributed Conventional Machine Studying: Enhancing the distribution of conventional machine studying fashions, like scikit-learn or forecasting fashions, throughout clusters.
- Enhancing Python Workflows: Distributing customized Python duties beforehand restricted to single nodes, together with these requiring advanced orchestration or communication between duties.
- Hyperparameter Search: Offering options to Hyperopt for hyperparameter tuning, using Ray Tune for extra environment friendly searches.
- Leveraging the Ray Ecosystem: Integrating with the expansive ecosystem of open-source libraries and instruments inside Ray, enriching the event setting.
- Massively Parallel Knowledge Processing: Combining Spark and Ray to enhance upon UDFs or foreach batch features – ideally suited for processing non-tabular knowledge like audio or video.
Beginning a Ray Cluster
Initiating a Ray cluster on Databricks is remarkably easy, requiring only some traces of code. This seamless initiation, coupled with Databricks’ scalable infrastructure, ensures that purposes transition easily from growth to manufacturing, leveraging each the computational energy of Ray and the information processing capabilities of Spark on Databricks.
Ranging from Databricks Machine Studying Runtime 15.0, Ray is pre-installed and totally arrange on the cluster. You can begin a Ray cluster utilizing the next code as steering (relying in your cluster configuration, you’ll want to modify these arguments to suit the obtainable assets in your cluster):
from ray.util.spark import setup_ray_cluster, shutdown_ray_cluster
setup_ray_cluster(
num_worker_nodes=2,
num_cpus_per_node=4,
autoscale = True,
collect_log_to_path="/dbfs/path/to/ray_collected_logs"
)
# Move any customized configuration to ray.init()
ray.init(ignore_reinit_error=True)This strategy begins a Ray cluster on prime of the extremely scalable and managed Databricks Spark cluster. As soon as began and obtainable, this Ray cluster can seamlessly combine with the opposite Databricks options, infrastructure, and instruments that Databricks offers. You may as well leverage enterprise options comparable to dynamic autoscaling, launching a mix of on-demand and spot situations, and cluster insurance policies. You may simply swap from an interactive cluster throughout code authoring to a job cluster for long-running jobs.
To go from operating Ray on a laptop computer to 1000’s of nodes on the cloud is only a matter of including just a few traces of code utilizing the previous setup_ray_cluster perform. Databricks manages the scalability of the Ray cluster by means of the underlying Spark cluster and is so simple as altering the variety of specified employee nodes and assets devoted to the Ray cluster.
“Over the previous 12 months and a half, we’ve also used Ray in our utility. Our expertise with Ray has been overwhelmingly optimistic, because it has constantly delivered dependable efficiency with none sudden errors or points. Its impression on our utility’s pace efficiency has been significantly noteworthy, with the implementation of Ray Cluster in Databricks taking part in an important position in decreasing processing instances by no less than half. In some situations, we’ve noticed a powerful enchancment of over 4X. All of this with none extra value. Furthermore, the Ray Dashboard has been invaluable in offering insights into reminiscence consumption for every activity, permitting us to ensure we’ve the optimized configuration for our utility”
— Juliana Negrini de Araujo, Senior Machine Studying Engineer, Cummins
Enhancing Knowledge Science on Databricks: Ray with MLflow and Unity Catalog
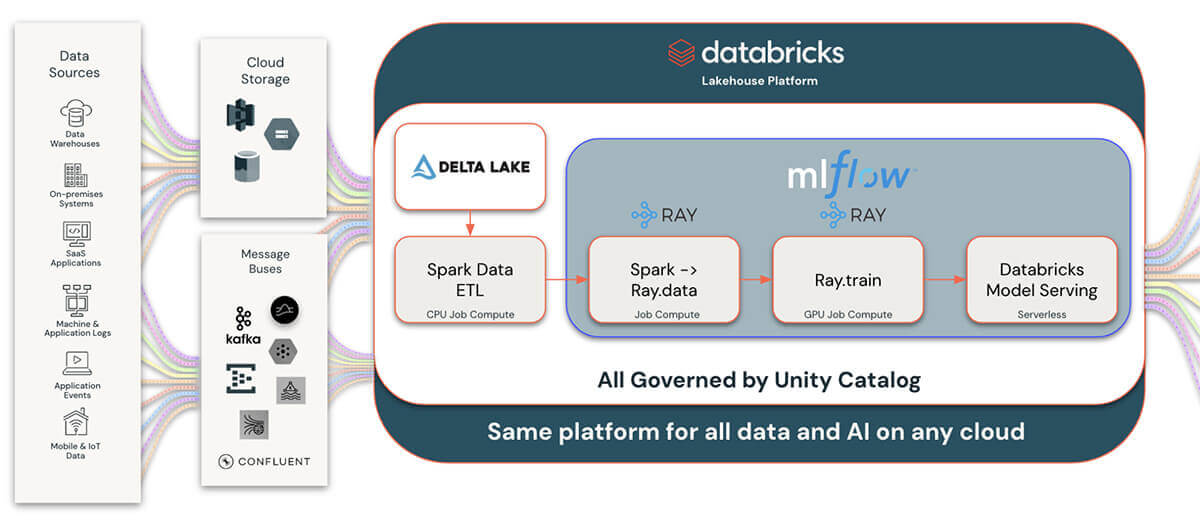
Databricks enhances knowledge science workflows by integrating Ray with three key managed companies: MLflow for lifecycle administration, Unity Catalog for knowledge governance, and Mannequin Serving for MLOps. This integration streamlines the monitoring, optimizing, and deploying of machine studying fashions developed with Ray, leveraging MLflow for seamless mannequin lifecycle administration. Knowledge scientists can effectively monitor experiments, handle mannequin variations, and deploy fashions into manufacturing, all inside Databricks’ unified platform.
Unity Catalog additional helps this ecosystem by providing strong knowledge governance, enabling clear lineage, and sharing machine studying artifacts created with Ray. This ensures knowledge high quality and compliance throughout all belongings, fostering efficient collaboration inside safe and controlled environments.
Combining Unity Catalog and our Delta Lake integration with Ray permits for a lot wider and extra complete integration with the remainder of the information and AI panorama. This offers Ray customers and builders an unparalleled skill to combine with extra knowledge sources than ever. Writing knowledge that’s generated from Ray purposes to Delta Lake and Unity Catalog additionally permits for connecting to the huge ecosystem of knowledge and enterprise intelligence instruments.
This mixture of Ray, MLflow, Unity Catalog, and Databricks Mannequin Serving on Databricks simplifies and accelerates the deployment of superior knowledge science options, offering a complete, ruled platform for innovation and collaboration in machine studying initiatives.
Get Began with Ray on Databricks
The collaboration of Ray and Databricks is greater than a mere integration; it affords a good coupling of two frameworks that not solely excel at their respective strengths however, when built-in collectively, provide a uniquely highly effective resolution to your AI growth wants. This integration not solely permits builders and knowledge scientists to faucet into the huge capabilities of Databricks’ platform, together with MLflow, Delta Lake, and Unity Catalog but in addition to combine with Ray’s computational effectivity and suppleness seamlessly. To study extra, see the complete information to utilizing Ray on Databricks.