{kind=link}
At Databricks, we’re dedicated to constructing probably the most environment friendly and performant coaching instruments for large-scale AI fashions. With the current launch of DBRX, we’ve highlighted the ability of Combination-of-Consultants (MoE) fashions, which give a considerable enchancment in coaching and inference effectivity. At present, we’re excited to announce that MegaBlocks, the open-source library used to coach DBRX, is turning into an official Databricks venture. We’re additionally releasing our MegaBlocks integration into our open supply coaching stack, LLMFoundry. Together with these open supply releases, we’re onboarding clients to our optimized inside variations who’re able to get peak efficiency at scale.
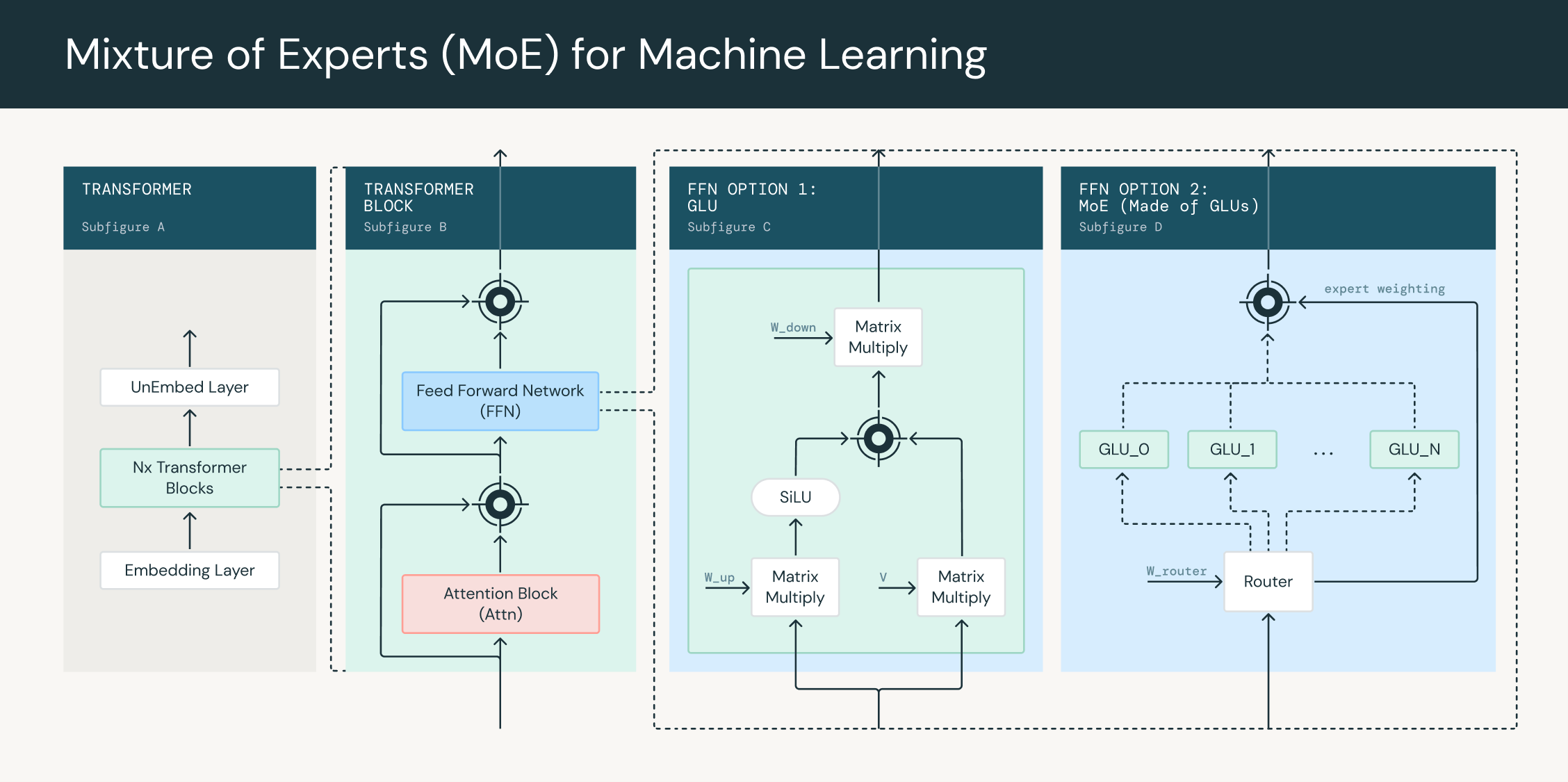
What’s a Combination of Consultants Mannequin?
A Combination of Consultants (MoE) mannequin is a machine studying mannequin that mixes the outputs of a number of knowledgeable networks, or “specialists,” to make a prediction. Every knowledgeable focuses on a selected area of the enter house, and a gating community determines the right way to mix the specialists’ outputs for a given enter.
Within the context of transformer networks, every feed-forward block will be changed with an MoE layer. This layer consists of a number of knowledgeable networks, every with its personal set of parameters, and a gating community that determines the right way to weight the outputs of the specialists for every enter token. The gating community is usually a linear layer feed-forward community that takes in every token as enter and produces a set of weights as output. A token project algorithm makes use of these weights to decide on which tokens are routed to which specialists. Throughout coaching, the gating community learns to assign inputs to the specialists, permitting the mannequin to specialize and enhance its efficiency.
MoE layers can be utilized to extend the parameter counts of transformer networks with out growing the variety of operations used to course of every token. It is because the gating community sends tokens to a fraction F < 1 of the overall knowledgeable set. An MoE community is an N parameter community, however solely has to do the computation of an N * F parameter community. For instance, DBRX is a 132B parameter mannequin however solely has to do as a lot computation as a 36B parameter mannequin.
Taking Possession of MegaBlocks
MegaBlocks is an environment friendly MoE implementation initially created by Trevor Gale as a part of his analysis into sparse coaching. MegaBlocks introduces the thought of utilizing sparse matrix multiplication to compute all specialists in parallel even when a distinct variety of tokens is assigned to every knowledgeable. Because the venture has gained recognition, it has turn out to be a core part of quite a few stacks, together with HuggingFace’s Nanotron, EleutherAI’s GPT-NeoX, Mistral’s reference implementation of Mixtral 8x7B, and naturally, our implementation of DBRX.
Databricks is worked up to take possession of this venture and supply long run help for the open supply neighborhood constructing round it. Trevor will proceed to function a co-maintainer and actively be concerned within the roadmap. We’ve transferred the repository to its new residence at databricks/megablocks on GitHub, the place we are going to proceed to develop and help the venture. Our fast roadmap focuses on upgrading the venture to be manufacturing grade, together with committing Databricks GPUs for CI/CD and establishing common launch cadences, and making certain an extensible design to additional allow sparsity analysis. In case you’re concerned about getting concerned, we’d love to listen to function requests on the points web page!
Open Sourcing LLMFoundry Integration
Whereas MegaBlocks offers an implementation of MoE layers, it requires a bigger framework round it to implement a complete Transformer, present a parallelism technique, and prepare performantly at scale. We’re excited to open supply our integration of MegaBlocks into LLMFoundry, our open supply coaching stack for giant AI fashions. LLMFoundry offers an extensible and configurable implementation of a transformer built-in with PyTorch FSDP, enabling large-scale MoE coaching. This integration served as a core part to coaching DBRX, enabling scaling to 130B+ parameter fashions.
Current YAMLs can simply be tweaked to incorporate MoE layers:
mannequin:
identify: mpt_causal_lm
...
ffn_config:
ffn_type: mb_dmoe
moe_num_experts: 16 # 16 whole specialists (like Dbrx)
moe_top_k: 4 # 4 energetic specialists (like Dbrx)
moe_world_size: 8 # 8-way knowledgeable parallelism
...Optimized Coaching at Databricks
Together with MegaBlocks, we’ve constructed all kinds of strategies devoted to optimizing efficiency on hundreds of GPUs. Our premium providing contains customized kernels, 8-bit help, and linear scaling to attain far superior efficiency, particularly for giant fashions at scale. We’re extremely excited to start out onboarding clients onto our subsequent era MoE platform. Contact us right this moment to get began!