{kind=link}
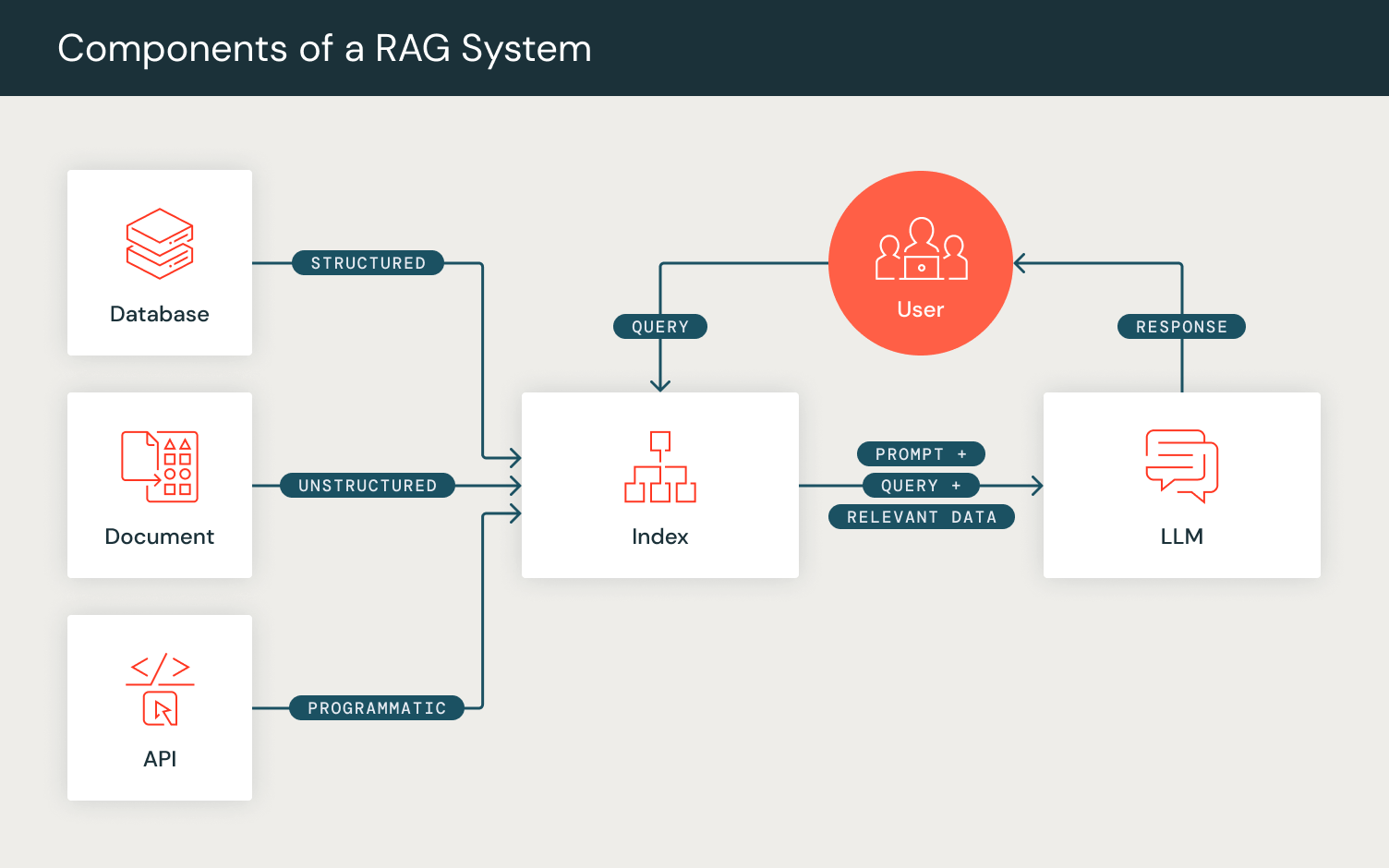
Massive language fashions (LLMs) have generated curiosity in efficient human-AI interplay by means of optimizing prompting methods. “Immediate engineering” is a rising methodology for tailoring mannequin outputs, whereas superior methods like Retrieval Augmented Technology (RAG) improve LLMs’ generative capabilities by fetching and responding with related data.
DSPy, developed by the Stanford NLP Group, has emerged as a framework for constructing compound AI methods by means of “programming, not prompting, basis fashions.” DSPy now helps integrations with Databricks developer endpoints for Mannequin Serving and Vector Search.
Engineering Compound AI
These prompting methods sign a shift in the direction of complicated “prompting pipelines” the place AI builders incorporate LLMs, retrieval fashions (RMs), and different elements whereas creating compound AI methods.
Programming not Prompting: DSPy
DSPy optimizes AI-driven methods efficiency by composing LLM calls alongside different computational instruments in the direction of downstream activity metrics. In contrast to conventional “immediate engineering,” DSPy automates immediate tuning by translating user-defined pure language signatures into full directions and few-shot examples. Mirroring end-to-end pipeline optimization as in PyTorch, DSPy permits customers to outline and compose AI methods layer by layer whereas optimizing for the specified goal.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
tremendous().__init__()
# declare three modules: the retriever, a question generator, and a solution generator
self.retrieve = retriever_model
self.generate_answer = dspy.Predict("context, question -> reply")
def ahead(self, question):
retrieved_context = self.retrieve(question)
context, context_ids = retrieved_context.docs, retrieved_context.doc_ids
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(reply=prediction.reply)Packages in DSPy have two essential strategies:
- Initialization: Customers can outline the elements of their prompting pipelines as DSPy layers. For example, to account for the steps concerned in RAG, we outline a retrieval layer and a era layer.
- We outline a retrieval layer `dspy.Retrieve` which makes use of the user-configured RM to retrieve a set of related passages/paperwork for an inputted search question.
- We then initialize our era layer, for which we use the `dspy.Predict` module, which internally prepares the immediate for era. To configure this era layer, we outline our RAG activity in a pure language signature format, specified by a set of enter fields (“context, question”) and the anticipated output subject (“reply”). This module then internally codecs the immediate to match this outlined formatting, after which returns the era from the user-configured LM.
- Ahead: Akin to PyTorch ahead passes, the DSPy program ahead perform permits for consumer composition of the prompting pipeline logic. By utilizing the layers we initialized, we arrange the computational movement of RAG by retrieving a set of passages given a question after which utilizing these passages as context alongside the question to generate a solution, outputting the anticipated output in a DSPy dictionary object.
Let’s check out RAG in motion utilizing the DSPy program and DBRX’s era.
For this instance, we use a pattern query from the HotPotQA Dataset which incorporates questions that require a number of steps to infer the proper reply.
question = "The Wings entered a brand new period, following the retirement of which Canadian retired skilled ice hockey participant and present common supervisor of the Tampa Bay Lightning of the Nationwide Hockey League (NHL)?"
reply = "Steve Yzerman"Let’s first configure our LM and RM in DSPy. DSPy gives a wide range of language and retrieval mannequin integrations, and customers can set these parameters to make sure any DSPy outlined program runs by means of these configurations.
dspy.settings.configure(lm=lm, rm=retriever_model)Let’s now declare our outlined DSPy RAG program and easily move within the query because the enter.
rag = RAG()
rag(question=question)Through the retrieval step, the question is handed to the self.retrieve layer which outputs the top-3 related passages, that are internally formatted as beneath:
[1] «Steve Yzerman | Stephen Gregory "Steve" Yzerman ( ; born Might 9, 1965) is a Canadian retired skilled ice hockey participant and present common supervisor of the Tampa Bay Lightning of the Nationwide Hockey League (NHL). He is ...»
[2] «2006–07 Detroit Pink Wings season | The 2006–07 Detroit Pink Wings season was the ...»
[3] «Record of Tampa Bay Lightning common managers | The Tampa Bay Lightning are ...»With these retrieved passages, we are able to move this alongside our question into the dspy.Predict module self.generate_answer, matching the pure language signature enter fields “context, question”. This internally applies some primary formatting and phrasing, and allows you to direct the mannequin along with your precise activity description with out immediate engineering the LM.
As soon as the formatting is asserted, the enter fields “context” and “question” are populated and the ultimate immediate is distributed to DBRX:
Given the fields `context`, `question`, produce the fields `reply`.
---
Comply with the next format.
Context: ${context}
Question: ${question}
Reasoning: Let's suppose step-by-step so as to ${produce the reply}. We ...
Reply: ${reply}
---
Context:
[1] «Steve Yzerman | Stephen Gregory "Steve" Yzerman ( ; born Might 9, 1965) is a Canadian retired skilled ice hockey participant and present common supervisor of the Tampa Bay Lightning of the Nationwide Hockey League (NHL). He's ...»
[2] «2006–07 Detroit Pink Wings season | The 2006–07 Detroit Pink Wings season was the ...»
[3] «Record of Tampa Bay Lightning common managers | The Tampa Bay Lightning are ...»
Question: The Wings entered a brand new period, following the retirement of which Canadian retired skilled ice hockey participant and present common supervisor of the Tampa Bay Lightning of the Nationwide Hockey League (NHL)?
Reply:DBRX generates a solution which is populated within the Reply: subject, and we are able to observe this prompt-generation by means of calling:
lm.inspect_history(n=1)This outputs the final prompt-generation from the LM with the generated reply “Steve Yzerman”, which is the proper reply!
Given the fields `context`, `question`, produce the fields `reply`.
---
Comply with the next format.
Context: ${context}
Question: ${question}
Reasoning: Let's suppose step-by-step so as to ${produce the reply}. We ...
Reply: ${reply}
---
Context:
[1] «Steve Yzerman | Stephen Gregory "Steve" Yzerman ( ; born Might 9, 1965) is a Canadian retired skilled ice hockey participant and present common supervisor of the Tampa Bay Lightning of the Nationwide Hockey League (NHL). He's ...»
[2] «2006–07 Detroit Pink Wings season | The 2006–07 Detroit Pink Wings season was the ...»
[3] «Record of Tampa Bay Lightning common managers | The Tampa Bay Lightning are ...»
Question: The Wings entered a brand new period, following the retirement of which Canadian retired skilled ice hockey participant and present common supervisor of the Tampa Bay Lightning of the Nationwide Hockey League (NHL)?
Reply: Steve Yzerman.DSPy has been extensively used throughout varied language mannequin duties corresponding to fine-tuning, in-context studying, data extraction, self-refinement, and quite a few others. This automated strategy outperforms normal few-shot prompting with human-written demonstrations by as much as 46% for GPT-3.5 and 65% for Llama2-13b-chat on pure language duties like multi-hop RAG and math benchmarks like GSM8K.
DSPy on Databricks
DSPy now helps integrations with Databricks developer endpoints for Mannequin Serving and Vector Search. Customers can configure Databricks-hosted basis mannequin APIs below the OpenAI SDK by means of dspy.Databricks. This ensures customers can consider their end-to-end DSPy pipelines on Databricks-hosted fashions. At the moment, this helps fashions on the Mannequin Serving Endpoints: chat (DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), completion (MPT 7B Instruct) and embedding (BGE Massive (En)) fashions.
Chat Fashions
lm = dspy.Databricks(mannequin='databricks-dbrx-instruct', model_type='chat', api_key = {Databricks API key}, api_base = {Databricks Mannequin Endpoint url})
lm(immediate)Completion Fashions
lm = dspy.Databricks(mannequin="databricks-mpt-7b-instruct", ...)
lm(immediate)Embedding Fashions
lm = dspy.Databricks(mannequin="databricks-bge-large-en", model_type='embeddings', ...)
lm(immediate)Retriever Fashions/Vector Search
Moreover, customers can configure retriever fashions by means of Databricks Vector Search. Following the creation of a Vector Search index and endpoint, customers can specify the corresponding RM parameters by means of dspy.DatabricksRM:
from dspy.retrieve.databricks_rm import DatabricksRM
retriever_model = DatabricksRM(databricks_index_name = index_name, databricks_endpoint = workspace_base_url, databricks_token = databricks_api_token, columns= ["id", "text", "metadata", "text_vector"], okay=3, ...)Customers can configure this globally by setting the LM and RM to corresponding Databricks endpoints and operating DSPy applications.
dspy.settings.configure(lm=llm, rm=retriever_model)With this integration, customers can construct and consider end-to-end DSPy functions, corresponding to RAG, utilizing Databricks endpoints!
Try the official DSPy GitHub repository, documentation and Discord to be taught extra about the right way to remodel generative AI duties into versatile DSPy pipelines with Databricks!