{kind=link}
Databricks Runtime 14.3 features a new functionality that permits customers to entry and analyze Structured Streaming‘s inside state knowledge: the State Reader API. The State Reader API units itself other than well-known Spark knowledge codecs comparable to JSON, CSV, Avro, and Protobuf. Its major objective is facilitating the event, debugging, and troubleshooting of stateful Structured Streaming workloads. Apache Spark 4.0.0 – anticipated to be launched later this yr – will embrace the State Reader API.
What challenges does the brand new API tackle?
Apache Spark™’s Structured Streaming gives varied stateful capabilities. If you would like to be taught extra about these, you need to begin by studying “A number of Stateful Operators in Structured Streaming,” which explains stateful operators, watermarks, and state administration.
The State Reader API lets you question the state knowledge and metadata. This API solves a number of issues for builders. Builders usually resort to extreme logging for debugging attributable to difficulties in understanding the state retailer throughout growth, resulting in slower venture progress. Testing challenges come up from the complexity of dealing with occasion time and unreliable exams, prompting some to bypass essential unit exams. In manufacturing, analysts wrestle with knowledge inconsistencies and entry limitations, with time-consuming coding workarounds typically wanted to resolve pressing points.
A two-part API
Two new DataFrame format choices make up the State Reader API: state-metadata and statestore. The state-metadata knowledge format gives high-level details about what’s saved within the state retailer, whereas the statestore knowledge format permits a granular have a look at the key-value knowledge itself. When investigating a manufacturing difficulty, you may begin with the state-metadata format to achieve a high-level understanding of the stateful operators in use, what batch IDs are concerned, and the way the information is partitioned. Then, you should use the statestore format to examine the precise state keys and values or to carry out analytics on the state knowledge.
Utilizing the State Reader API is easy and will really feel acquainted. For each codecs, you should present a path to the checkpoint location the place state retailer knowledge is persevered. This is easy methods to use the brand new knowledge codecs:
- State retailer overview:
spark.learn.format("state-metadata").load("<checkpointLocation>") - Detailed state knowledge:
spark.learn.format("statestore").load("<checkpointLocation>")
For extra data on non-compulsory configurations and the entire schema of the returned knowledge, see the Databricks documentation on studying Structured Streaming state data. Be aware that you may learn state metadata data for Structured Streaming queries run on Databricks Runtime 14.2 or above.
Earlier than we get into the small print of utilizing the State Reader API, we have to arrange an instance stream that features stateful operations.
Instance: Actual-time advert billing
Suppose your job is to construct a pipeline to assist with the billing course of associated to a streaming media firm’s advertisers. Let’s assume that viewers utilizing the service are proven commercials periodically from varied advertisers. If the consumer clicks on an advert, the media firm wants to gather this reality in order that it might cost the advertiser and get the suitable credit score for the advert click on. Another assumptions:
- For a viewing session, a number of clicks inside a 1-minute interval ought to be “deduplicated” and counted as one click on.
- A 5-minute window defines how usually the mixture counts ought to be output to a goal Delta desk for an advertiser.
- Assume {that a} consumer of the streaming media utility is uniquely recognized by a
profile_idincluded within the occasion knowledge.
On the finish of this put up we’ll present the supply code for producing the pretend occasion stream. For now, we’ll concentrate on the supply code that:
- Consumes the stream
- Deduplicates the occasion clicks
- Aggregates the variety of advert clicks (by distinctive
profile_ids) for everyadvertiser_id - Outputs the outcomes to a Delta desk
The supply knowledge
First, let us take a look at the occasion knowledge. The code used to generate this knowledge could be discovered within the Appendix of this text.
Consider a profile_id as representing a novel human consumer streaming from the media app. The occasion knowledge conveys what advert was proven to the consumer (profile_id) at a given timestamp and whether or not or not they clicked the advert.
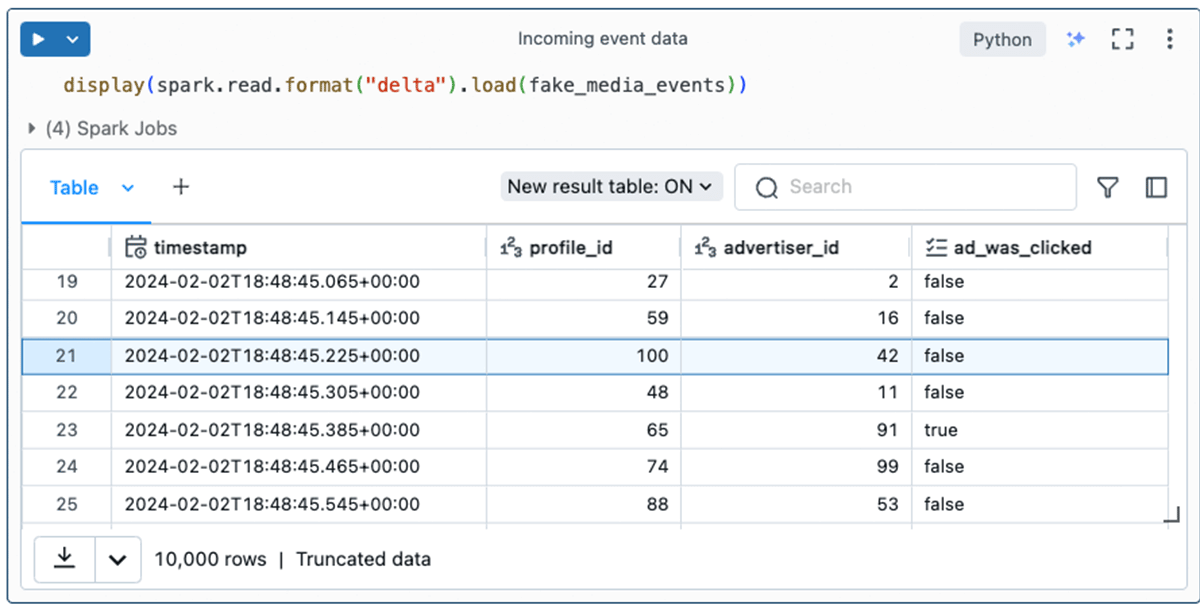
Deduplicating data
The second step within the course of is to drop duplicates, a finest follow with streaming pipelines. This is smart, for instance, to make sure that a fast click-click just isn’t counted twice.
The withWatermark methodology specifies the window of time between which duplicate data (for a similar profile_id and advertiser_id) are dropped so they do not transfer any additional alongside within the stream.

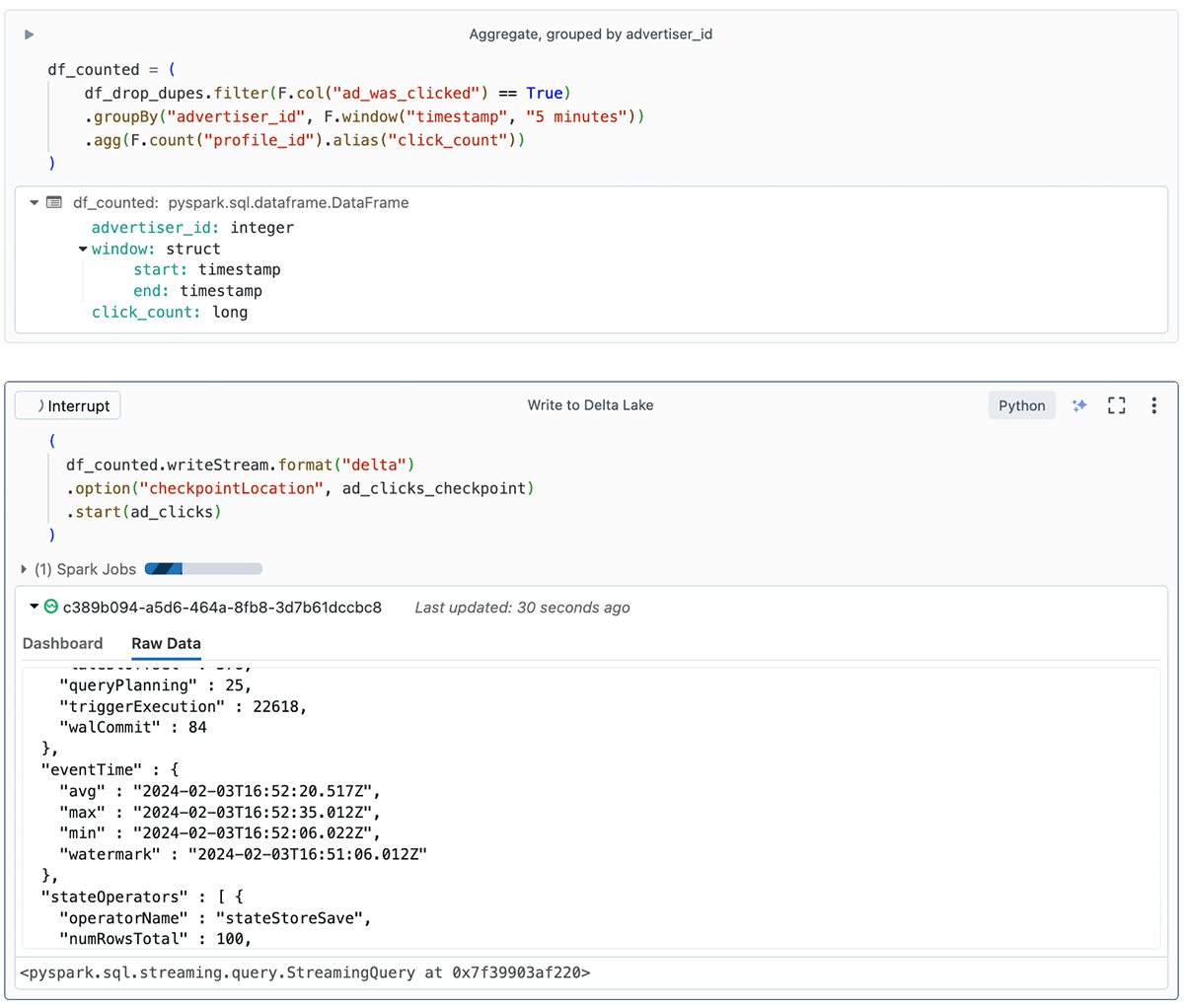
Aggregating data and writing outcomes
The final step to trace advert billing is to persist the overall variety of clicks per advertiser for every 5-minute window.
In abstract, the code is aggregating knowledge in nonoverlapping 5-minute intervals (tumbling home windows), and counting the clicks per advertiser inside every of those home windows.
Within the screenshot, chances are you’ll discover that the “Write to Delta Lake” cell reveals some helpful details about the stream on the Uncooked Knowledge tab. This contains watermark particulars, state particulars, and statistics like numFilesOutstanding and numBytesOutstanding. These streaming metrics are very helpful for growth, debugging, and troubleshooting.
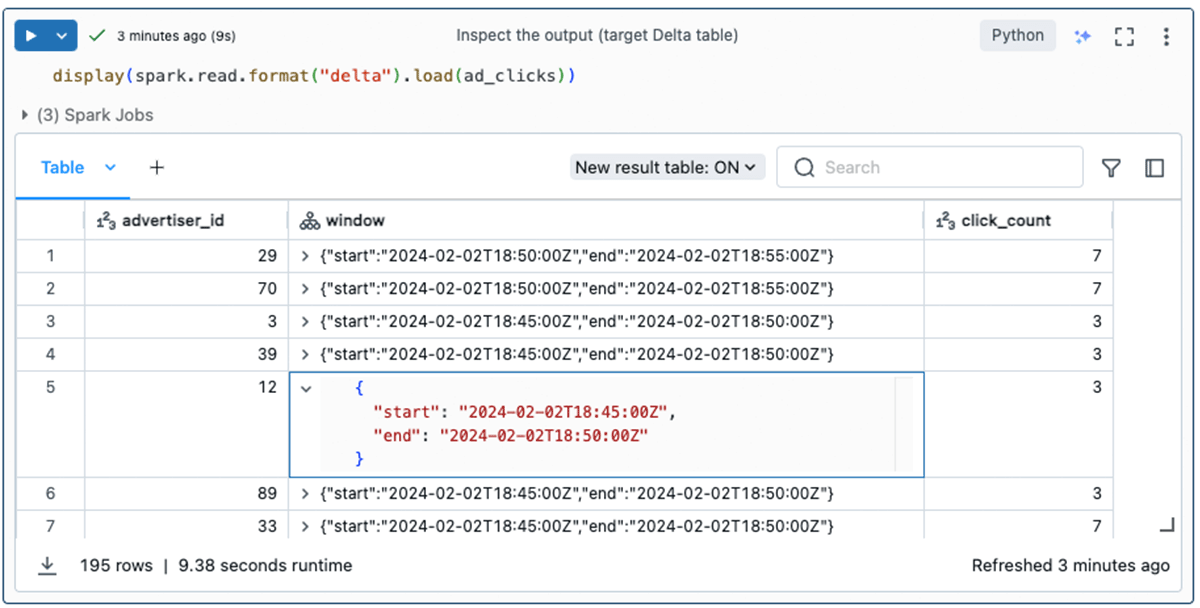
Lastly, the vacation spot Delta desk is populated with an advertiser_id, the variety of advert clicks (click_count), and the time-frame (window) throughout which the occasions happened.
Utilizing the State Reader API
Now that we have walked by way of a real-world stateful streaming job, let’s examine how the State Reader API may also help. First, let’s discover the state-metadata knowledge format to get a high-level image of the state knowledge. Then, we’ll see easy methods to get extra granular particulars with the statestore knowledge format.
Excessive-level particulars with state-metadata
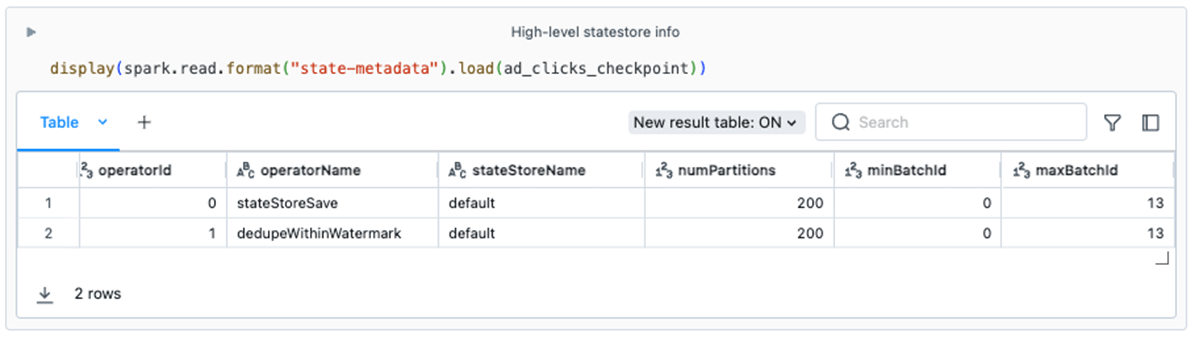
The knowledge from state-metadata on this instance may also help us spot some potential points:
- Enterprise logic. You’ll discover that this stream has two stateful operators. This data may also help builders perceive how their streams are utilizing the state retailer. For instance, some builders may not remember that
dedupeWithinWatermark(the underlying operator for the PySpark methodologydropDuplicatesWithinWatermark) leverages the state retailer. - State retention. Ideally, as a stream progresses over time, state knowledge is getting cleaned up. This could occur routinely with some stateful operators. Nevertheless, arbitrary stateful operations (e.g.,
FlatMapGroupsWithState) require that the developer be aware of and code the logic for dropping or expiring state knowledge. If theminBatchIddoesn’t enhance over time, this could possibly be a purple flag indicating that the state knowledge footprint may develop unbounded, resulting in eventual job degradation and failure. - Parallelism. The default worth for
spark.sql.shuffle.partitionsis200. This configuration worth dictates the variety of state retailer situations which are created throughout the cluster. For some stateful workloads, 200 could also be unsuitable.
Granular particulars with statestore
The statestore knowledge format gives a solution to examine and analyze granular state knowledge, together with the contents of the keys and values used for every stateful operation within the state retailer database. These are represented as Structs within the DataFrame’s output:
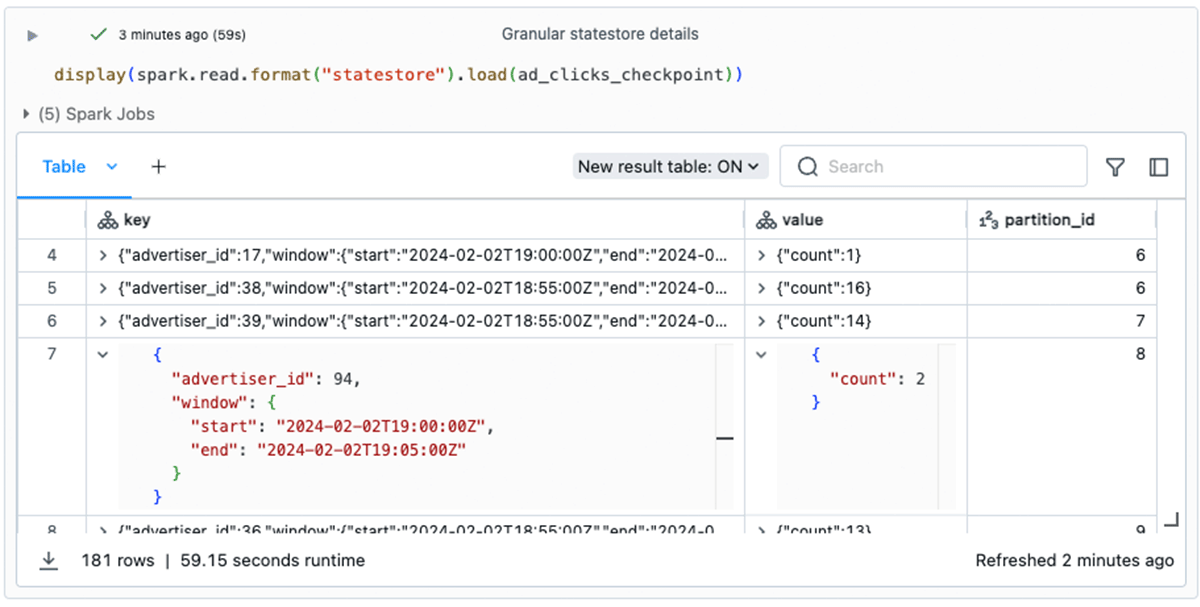
Gaining access to this granular state knowledge helps speed up the event of your stateful streaming pipeline by eradicating the necessity to embrace debugging messages all through your code. It may also be essential for investigating manufacturing points. For example, in the event you obtain a report of a significantly inflated variety of clicks for a specific advertiser, inspecting the state retailer data can direct your investigation when you’re debugging the code.
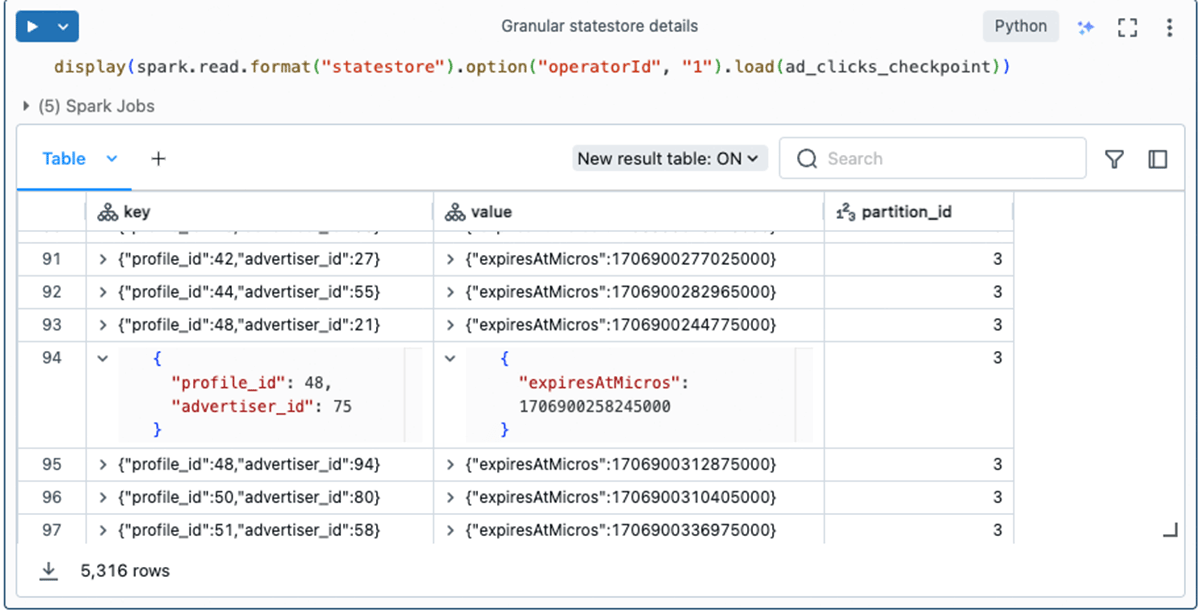
In case you have a number of stateful operators, you should use the operatorId choice to examine the granular particulars for every operator. As you noticed within the earlier part, the operatorId is without doubt one of the values included within the state-metadata output. For instance, right here we question particularly for dedupeWithinWatermark‘s state knowledge:
Performing analytics (detecting skew)
You should utilize acquainted methods to carry out analytics on the DataFrames surfaced by the State Reader API. In our instance, we will examine for skew as follows:
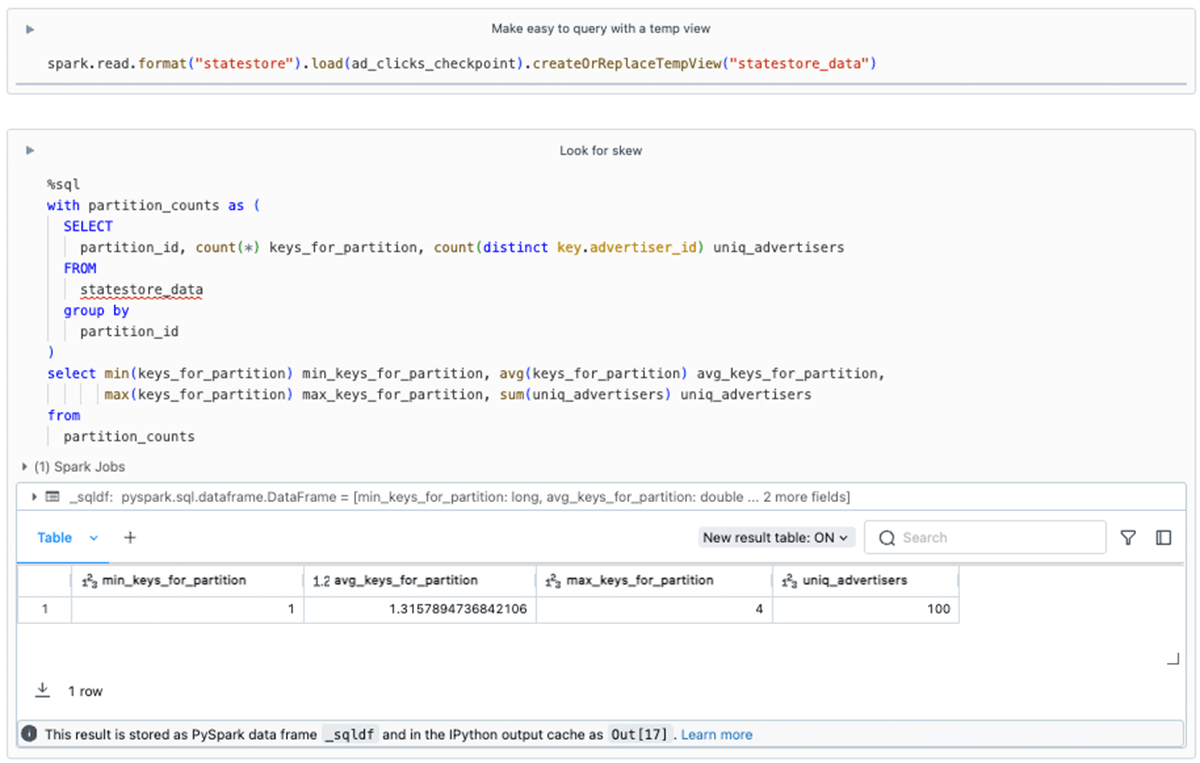
Mixed with the insights from our use of the state-metadata API, we all know that there are 200 partitions. Nevertheless, we see right here that there are some partitions the place simply 3 of the 100 distinctive advertisers have state maintained. For this toy instance, we need not fear, however in massive workloads proof of skew ought to be investigated as it might result in efficiency and useful resource points.
When to make use of the State Reader API
Improvement and debugging
The brand new API significantly simplifies the event of stateful streaming functions. Beforehand, builders needed to depend on debug print messages and comb by way of executor logs to confirm enterprise logic. With the State Reader API, they’ll now straight view the state, enter new data, question the state once more, and refine their code by way of iterative testing.
Take, for instance, a Databricks buyer who makes use of the flatMapGroupsWithState operator in a stateful utility to trace diagnostics for hundreds of thousands of set-top cable containers. The enterprise logic for this activity is advanced and should account for varied occasions. The cable field ID serves as the important thing for the stateful operator. By using the brand new API, builders can enter check knowledge into the stream and examine the state after every occasion, making certain the enterprise logic features appropriately.
The API additionally permits builders to incorporate extra sturdy unit exams and check circumstances that confirm the contents of the state retailer as a part of their expectations.
Taking a look at parallelism and skew
Each knowledge codecs supply insights to builders and operators relating to the distribution of keys throughout state retailer situations. The state-metadata format reveals the variety of partitions within the state retailer. Builders usually persist with the default setting of spark.sql.shuffle.partitions (200), even in massive clusters. Nevertheless, the variety of state retailer situations is set by this setting, and for bigger workloads, 200 partitions may not be adequate.
The statestore format is helpful for detecting skew, as proven earlier on this article.
Investigating manufacturing points
Investigations in knowledge analytics pipelines occur for a wide range of causes. Analysts could search to hint the origin and historical past of a document, whereas manufacturing streams could encounter bugs requiring detailed forensic evaluation, together with of state retailer knowledge.
The State Reader API just isn’t supposed for use in an always-on context (it’s not a streaming supply). Nevertheless, builders can proactively bundle a pocket book as a Workflow to assist automate the retrieval of state metadata and evaluation of the state, by way of methods like these proven earlier.
Conclusion
The State Reader API introduces much-needed transparency, accessibility, and ease of use to stateful streaming processes. As demonstrated on this article, the API’s utilization and output are simple and user-friendly, simplifying advanced investigative duties.
The State Reader API is included in Apache Spark 4.0.0 as a part of SPARK-45511. The Databricks doc Learn Structured Streaming state data explains the API’s choices and utilization.
Appendix
Supply code
Under is the supply code for the instance use case defined on this article. It can save you this as a “.py” file and import it into Databricks.
# Databricks pocket book supply
# DBTITLE 1,Greatest follow is to make use of RocksDB state retailer implementation
spark.conf.set(
"spark.sql.streaming.stateStore.providerClass",
"com.databricks.sql.streaming.state.RocksDBStateStoreProvider")
# COMMAND ----------
# DBTITLE 1,Imports
import random
import pyspark.sql.features as F
import pyspark.sql.varieties as T
# COMMAND ----------
# DBTITLE 1,Directories for the demo. Change, as wanted
demo_root = "/Volumes/essential/default/ad_click_demo"
fake_media_events = f"{demo_root}/bronze_event_data"
fake_media_events_checkpoint = f"{demo_root}/bronze_event_checkpoint"
ad_clicks = f"{demo_root}/silver_clicks"
ad_clicks_checkpoint = f"{demo_root}/silver_clicks_checkpoint"
dbutils.fs.rm(f"{demo_root}", True)
# COMMAND ----------
# DBTITLE 1,UDFs for random knowledge
random_profile_id = udf(lambda: random.randint(1, 100), T.IntegerType())
random_advertiser_id = udf(lambda: random.randint(1, 100), T.IntegerType())
random_ad_was_clicked = udf(lambda: (random.randint(0, 100) <= 10), T.BooleanType())
# COMMAND ----------
# DBTITLE 1,Faux knowledge DataFrame
event_dataframe = (
# pretend data per second
spark.readStream.format("charge").choice("rowsPerSecond", "100").load()
.withColumn("profile_id", random_profile_id())
.withColumn("advertiser_id", random_advertiser_id())
.withColumn("ad_was_clicked", random_ad_was_clicked()).drop("worth")
)
# COMMAND ----------
# DBTITLE 1,Stream to an occasion desk
event_dataframe.writeStream
.format("delta")
.choice("checkpointLocation", f"{demo_root}/tmp/fake_media_events_checkpoint/")
.begin(fake_media_events)
# COMMAND ----------
# MAGIC %md
# MAGIC Earlier than continuing, wait till the stream is operating...
# COMMAND ----------
# DBTITLE 1,Incoming occasion knowledge
show(spark.learn.format("delta").load(fake_media_events))
# COMMAND ----------
# DBTITLE 1,Learn and set 1 minute watermark
df_stream = (
spark.readStream.format("delta").load(fake_media_events)
.withWatermark("timestamp", "1 minutes")
)
# COMMAND ----------
# DBTITLE 1,Drop duplicates obtained throughout the 1-minute watermark
df_drop_dupes = df_stream.dropDuplicatesWithinWatermark(["profile_id", "advertiser_id"])
# COMMAND ----------
# DBTITLE 1,Mixture, grouped by advertiser_id
df_counted = (
df_drop_dupes.filter(F.col("ad_was_clicked") == True)
.groupBy("advertiser_id", F.window("timestamp", "5 minutes"))
.agg(F.depend("profile_id").alias("click_count"))
)
# COMMAND ----------
# DBTITLE 1,Write to Delta Lake
(
df_counted.writeStream.format("delta")
.choice("checkpointLocation", ad_clicks_checkpoint)
.begin(ad_clicks)
)
# COMMAND ----------
# MAGIC %md
# MAGIC Earlier than continuing, wait till the stream is operating...
# COMMAND ----------
# DBTITLE 1,Excessive-level statestore data
show(spark.learn.format("state-metadata").load(ad_clicks_checkpoint))
# COMMAND ----------
# DBTITLE 1,Granular statestore particulars
show(spark.learn.format("statestore").load(ad_clicks_checkpoint))
# COMMAND ----------
# DBTITLE 1,Granular statestore particulars
show(spark.learn.format("statestore").choice("operatorId", "1").load(ad_clicks_checkpoint))
# COMMAND ----------
# DBTITLE 1,Make simple to question with a temp view
spark.learn.format("statestore").load(ad_clicks_checkpoint).createOrReplaceTempView("statestore_data")
# COMMAND ----------
# DBTITLE 1,Search for skew
# MAGIC %sql
# MAGIC with partition_counts as (
# MAGIC SELECT
# MAGIC partition_id, depend(*) keys_for_partition, depend(distinct key.advertiser_id) uniq_advertisers
# MAGIC FROM
# MAGIC statestore_data
# MAGIC group by
# MAGIC partition_id
# MAGIC )
# MAGIC choose min(keys_for_partition) min_keys_for_partition, avg(keys_for_partition) avg_keys_for_partition,
# MAGIC max(keys_for_partition) max_keys_for_partition, sum(uniq_advertisers) uniq_advertisers
# MAGIC from
# MAGIC partition_counts
# COMMAND ----------
# DBTITLE 1,Examine the output (goal Delta desk)
show(spark.learn.format("delta").load(ad_clicks))