{kind=link}
The Databricks Information Intelligence Platform affords unparalleled flexibility, permitting customers to entry practically instantaneous, horizontally scalable compute sources. This ease of creation can result in unchecked cloud prices if not correctly managed.
Implement Observability to Monitor & Chargeback Value
The way to successfully use observability to trace & cost again prices in Databricks
When working with advanced technical ecosystems, proactively understanding the unknowns is vital to sustaining platform stability and controlling prices. Observability supplies a approach to analyze and optimize methods based mostly on the information they generate. That is totally different from monitoring, which focuses on figuring out new patterns relatively than monitoring identified points.
Key options for price monitoring in Databricks
Tagging: Use tags to categorize sources and expenses. This permits for extra granular price allocation.
System Tables: Leverage system tables for automated price monitoring and chargeback. Cloud-native price monitoring instruments: Make the most of these instruments for insights into prices throughout all sources.
What are System Tables & learn how to use them
Databricks present nice observability capabilities utilizing System tables are Databricks-hosted analytical shops of a buyer account’s operational knowledge discovered within the system catalog. They supply historic observability throughout the account and embody user-friendly tabular info on platform telemetry. .Key insights like Billing utilization knowledge can be found in system tables (this at present solely contains DBU’s Checklist Value), with every utilization file representing an hourly mixture of a useful resource’s billable utilization.
The way to allow system tables
System tables are managed by Unity Catalog and require a Unity Catalog-enabled workspace to entry. They embody knowledge from all workspaces however can solely be queried from enabled workspaces. Enabling system tables occurs on the schema degree – enabling a schema allows all its tables. Admins should manually allow new schemas utilizing the API.

What are Databricks tags & learn how to use them
Databricks tagging allows you to apply attributes (key-value pairs) to sources for higher group, search, and administration. For monitoring price and cost again groups can tag their databricks jobs and compute (Clusters, SQL warehouse), which will help them monitor utilization, prices, and attribute them to particular groups or items.
The way to apply tags
Tags may be utilized to the next databricks sources for monitoring utilization and value:
- Databricks Compute
- Databricks Jobs
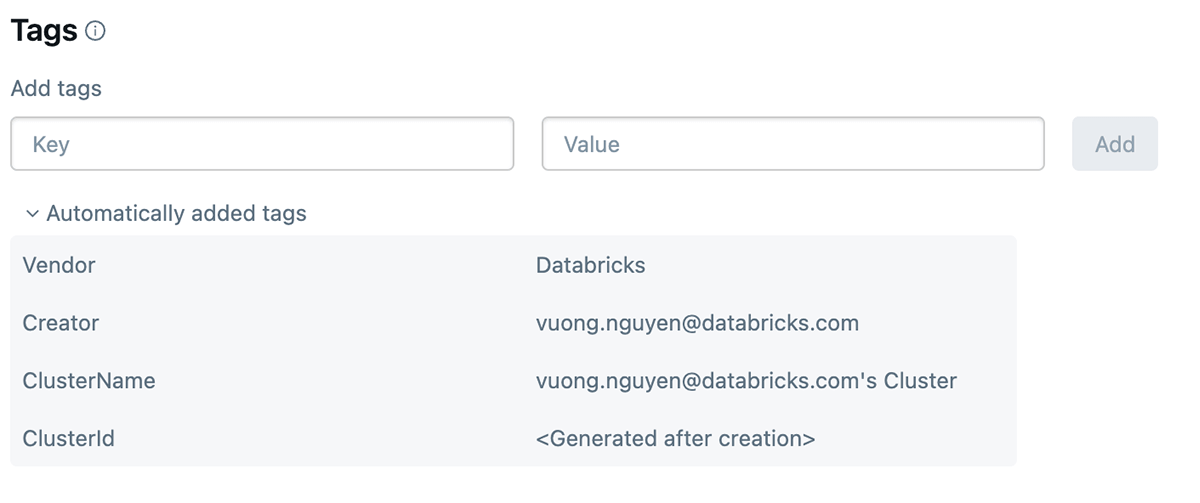
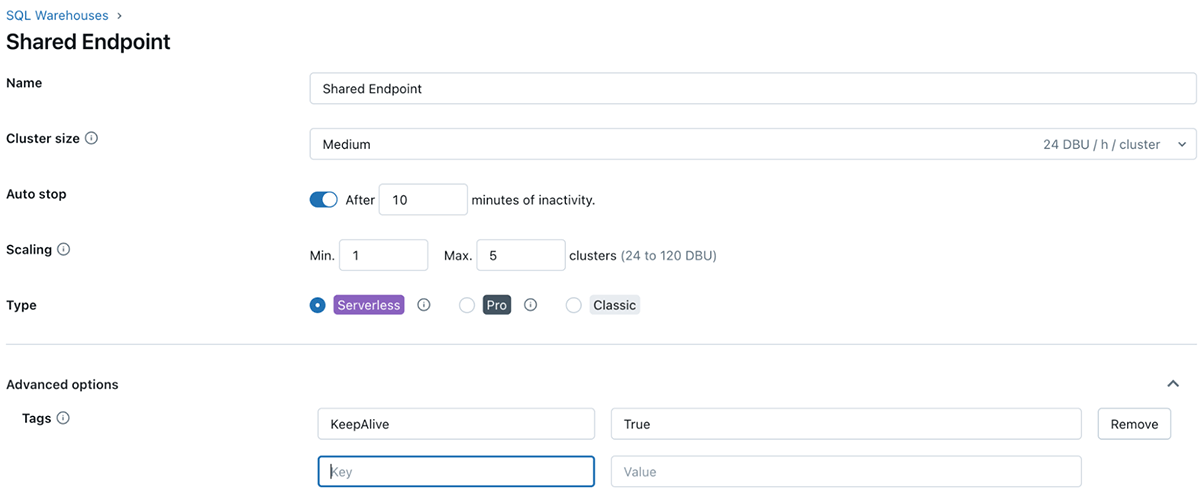
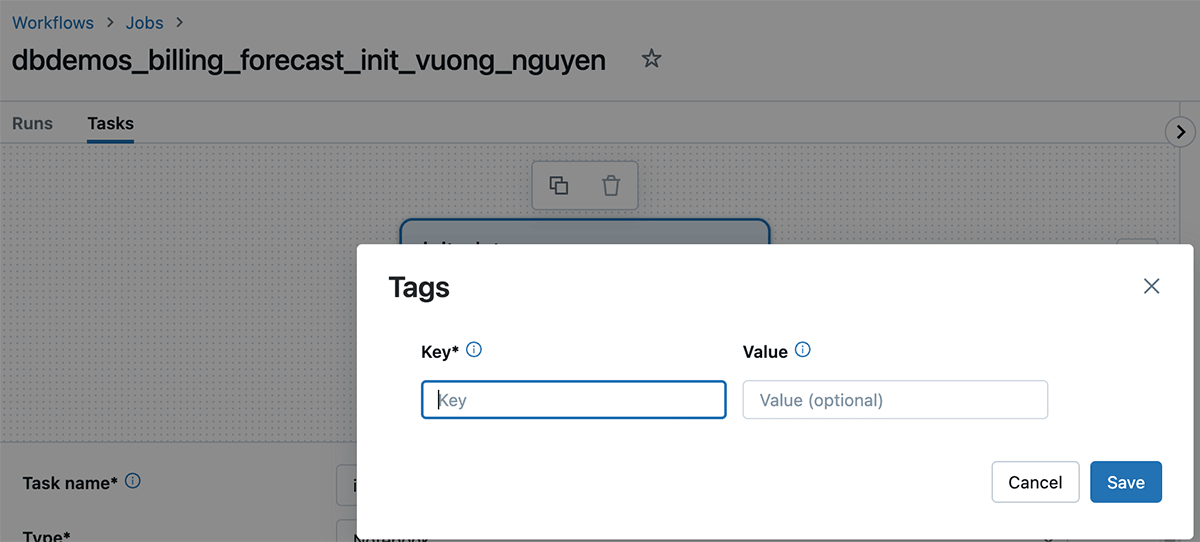
As soon as these tags are utilized, detailed price evaluation may be carried out utilizing the billable utilization system tables.
The way to establish price utilizing cloud native instruments
To observe price and precisely attribute Databricks utilization to your group’s enterprise items and groups (for chargebacks, for instance), you possibly can tag workspaces (and the related managed useful resource teams) in addition to compute sources.
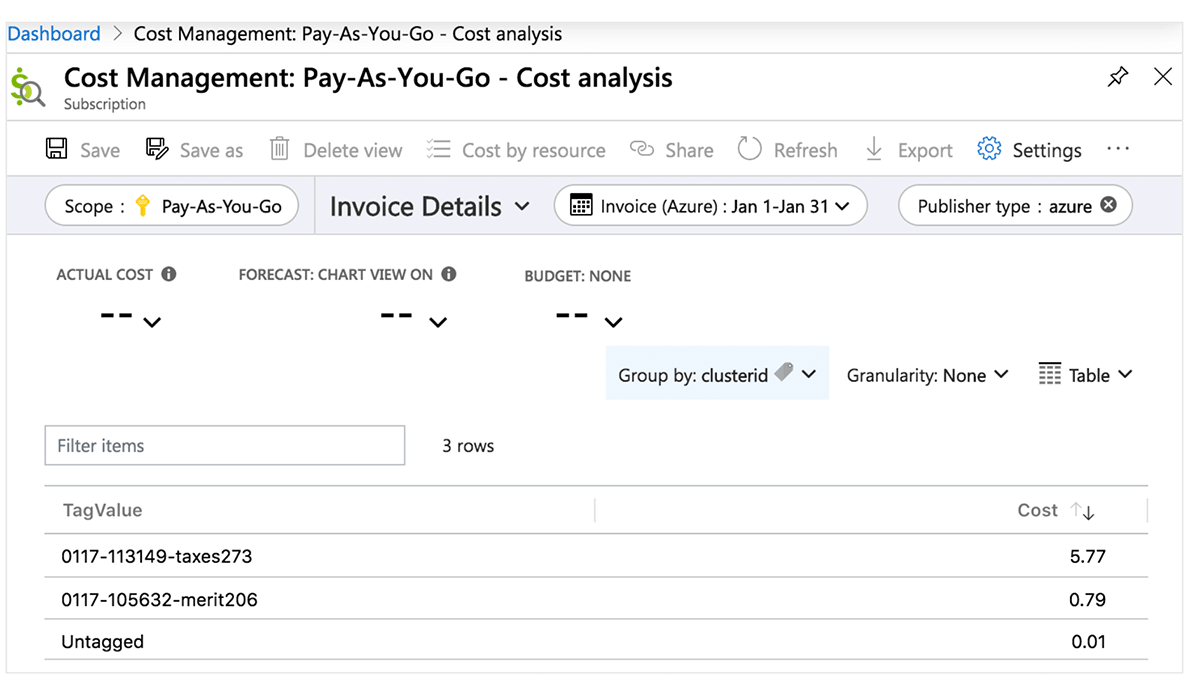
Azure Value Middle
The next desk elaborates Azure Databricks objects the place tags may be utilized. These tags can propagate to detailed price evaluation stories you can entry within the portal and to the billable utilization system desk. Discover extra particulars on tag propagation and limitations in Azure.
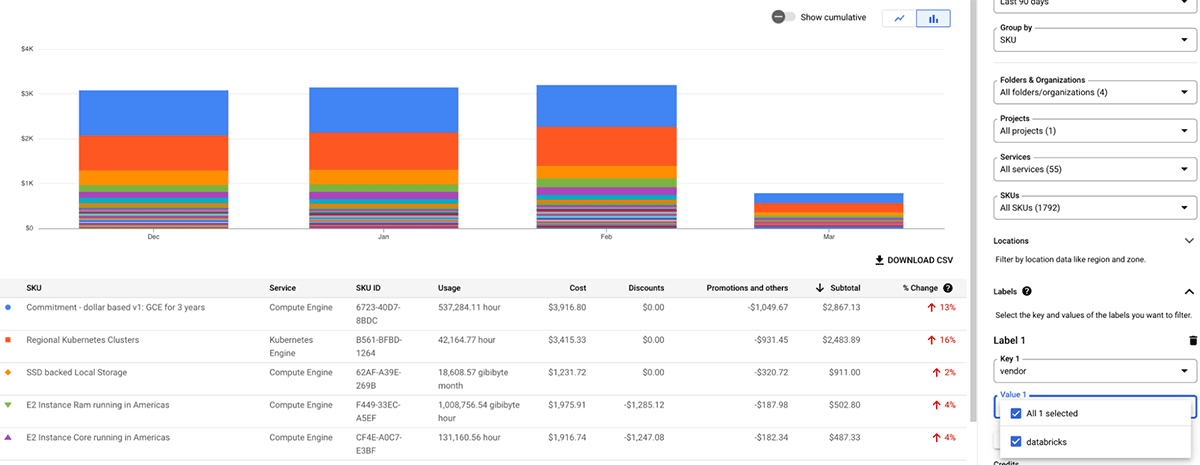
AWS Value Explorer
The next desk elaborates AWS Databricks Objects the place tags may be utilized.These tags can propagate each to utilization logs and to AWS EC2 and AWS EBS situations for price evaluation. Databricks recommends utilizing system tables (Public Preview) to view billable utilization knowledge. Discover extra particulars on tags propagation and limitations in AWS.
| AWS Databricks Object | Tagging Interface (UI) | Tagging Interface (API) |
|---|---|---|
| Workspace | N/A | Account API |
| Pool | Swimming pools UI within the Databricks workspace | Occasion Pool API |
| All-purpose & Job compute | Compute UI within the Databricks workspace | Clusters API |
| SQL Warehouse | SQL warehouse UI within the Databricks workspace | Warehouse API |
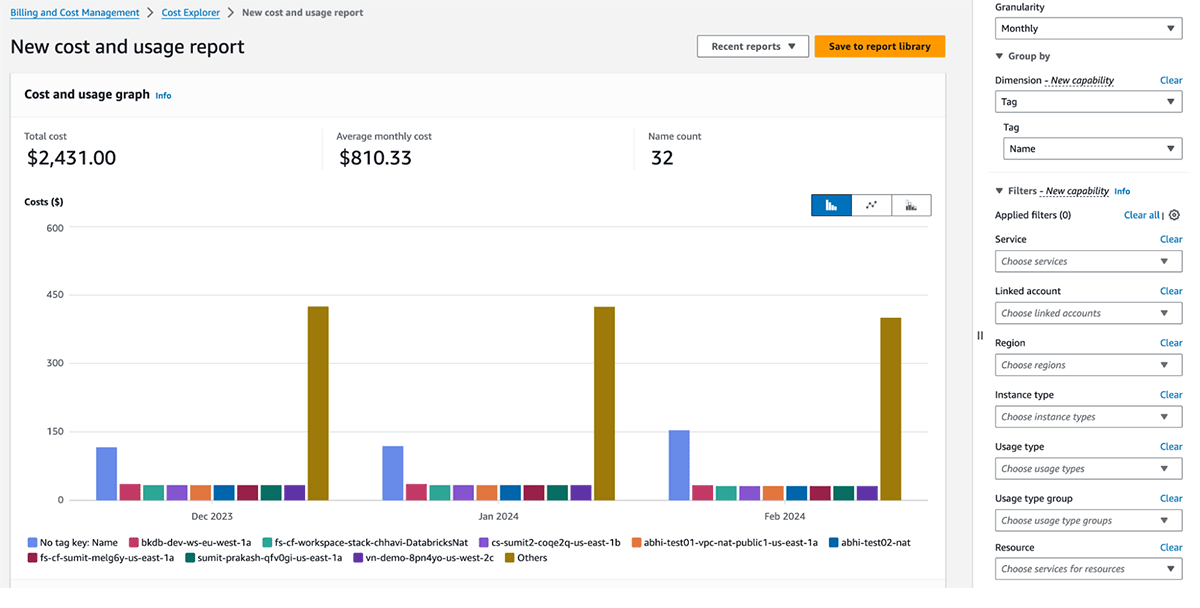
GCP Value administration and billing
The next desk elaborates GCP databricks objects the place tags may be utilized. These tags/labels may be utilized to compute sources. Discover extra particulars on tags/labels propagation and limitations in GCP.
The Databricks billable utilization graphs within the account console can mixture utilization by particular person tags. The billable utilization CSV stories downloaded from the identical web page additionally embody default and customized tags. Tags additionally propagate to GKE and GCE labels.
| GCP Databricks Object | Tagging Interface (UI) | Tagging Interface (API) |
|---|---|---|
| Pool | Swimming pools UI within the Databricks workspace | Occasion Pool API |
| All-purpose & Job compute | Compute UI within the Databricks workspace | Clusters API |
| SQL Warehouse | SQL warehouse UI within the Databricks workspace | Warehouse API |
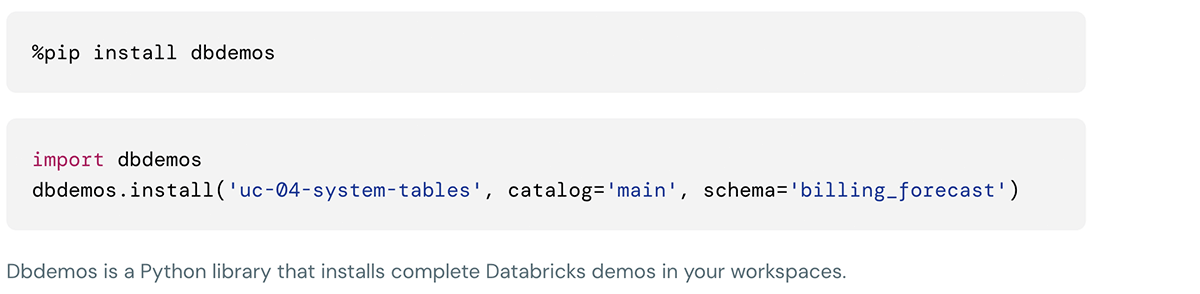
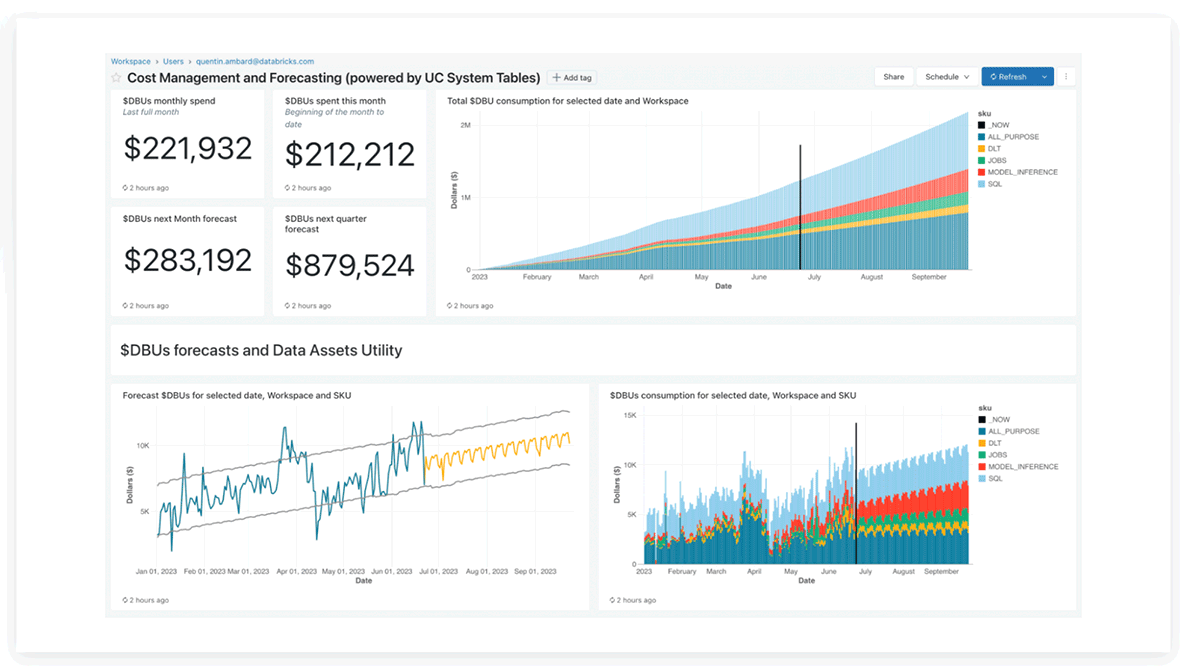
Databricks System tables Lakeview dashboard
The Databricks product workforce has offered precreated lakeview dashboards for price evaluation and forecasting utilizing system tables, which clients can customise as effectively.
This demo may be put in utilizing following instructions within the databricks notebooks cell:
Greatest Practices to Maximize Worth
When working workloads on Databricks, selecting the best compute configuration will considerably enhance the fee/efficiency metrics. Under are some sensible price optimizations strategies:
Utilizing the appropriate compute sort for the appropriate job
For interactive SQL workloads, SQL warehouse is essentially the most cost-efficient engine. Much more environment friendly might be Serverless compute, which comes with a really quick beginning time for SQL warehouses and permits for shorter auto-termination time.
For non-interactive workloads, Jobs clusters price considerably lower than an all-purpose clusters. Multitask workflows can reuse compute sources for all duties, bringing prices down even additional
Selecting the correct occasion sort
Utilizing the most recent technology of cloud occasion sorts will virtually at all times deliver efficiency advantages, as they arrive with the very best efficiency and newest options. On AWS, Graviton2-based Amazon EC2 situations can ship as much as 3x higher price-performance than comparable Amazon EC2 situations.
Based mostly in your workloads, additionally it is vital to select the appropriate occasion household. Some easy guidelines of thumb are:
- Reminiscence optimized for ML, heavy shuffle & spill workloads
- Compute optimized for Structured Streaming workloads, upkeep jobs (e.g. Optimize & Vacuum)
- Storage optimized for workloads that profit from caching, e.g. ad-hoc & interactive knowledge evaluation
- GPU optimized for particular ML & DL workloads
- Common goal in absence of particular necessities
Selecting the Proper Runtime
The newest Databricks Runtime (DBR) often comes with improved efficiency and can virtually at all times be sooner than the one earlier than it.
Photon is a high-performance Databricks-native vectorized question engine that runs your SQL workloads and DataFrame API calls sooner to scale back your whole price per workload. For these workloads, enabling Photon might deliver important price financial savings.
Leveraging Autoscaling in Databricks Compute
Databricks supplies a singular characteristic of cluster autoscaling making it simpler to attain excessive cluster utilization since you don’t must provision the cluster to match a workload. That is notably helpful for interactive workloads or batch workloads with various knowledge load. Nevertheless, traditional Autoscaling doesn’t work with Structured Streaming workloads, which is why now we have developed Enhanced Autoscaling in Delta Dwell Tables to deal with streaming workloads that are spiky and unpredictable.
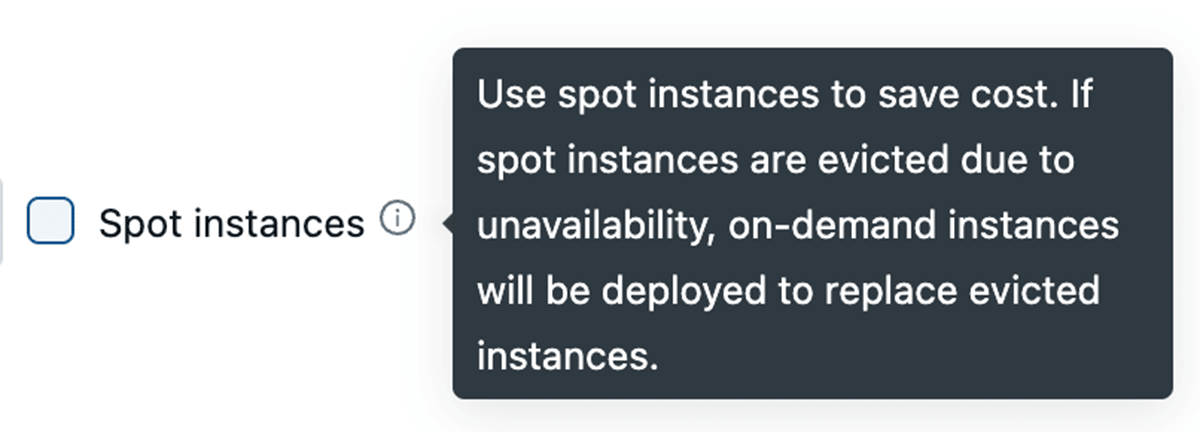
Leveraging Spot Situations
All main cloud suppliers supply spot situations which let you entry unused capability of their knowledge facilities for as much as 90% lower than common On-Demand situations. Databricks lets you leverage these spot situations, with the power to fallback to On-Demand situations mechanically in case of termination to reduce disruption. For cluster stability, we advocate utilizing On-Demand driver nodes.
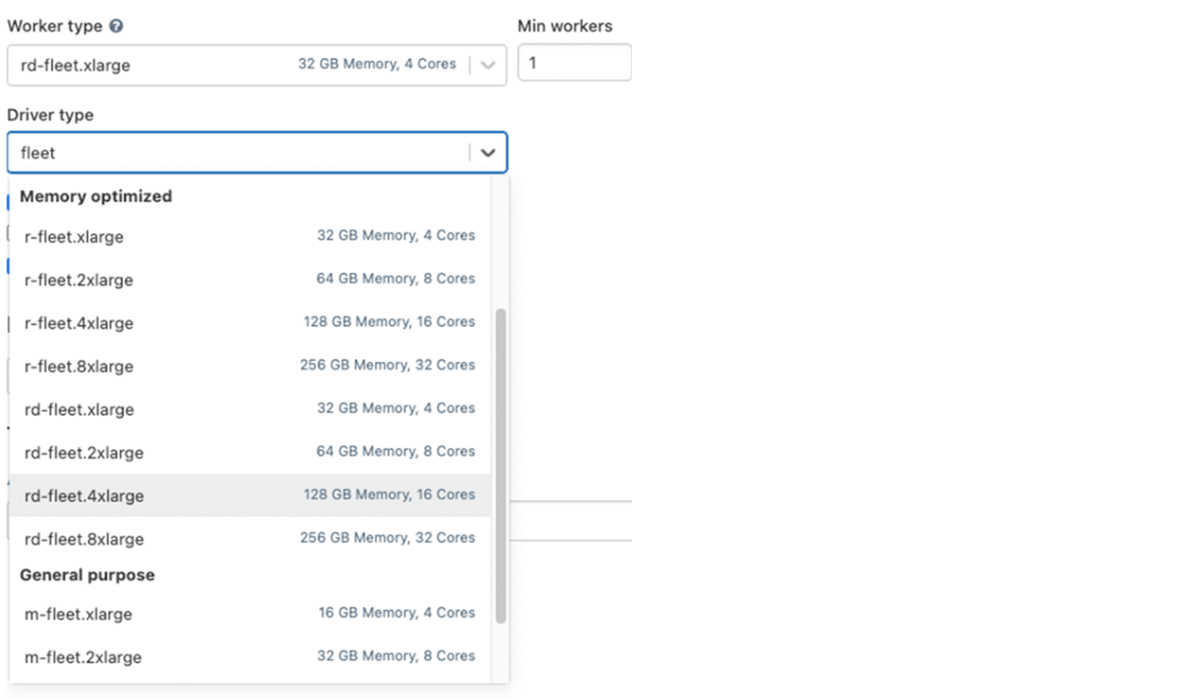
Leveraging Fleet occasion sort (on AWS)
Underneath the hood, when a cluster makes use of one in all these fleet occasion sorts, Databricks will choose the matching bodily AWS occasion sorts with the very best worth and availability to make use of in your cluster.
Cluster Coverage
Efficient use of cluster insurance policies permits directors to implement price particular restrictions for finish customers:
- Allow cluster auto termination with an affordable worth (for instance, 1 hour) to keep away from paying for idle instances.
- Be certain that solely cost-efficient VM situations may be chosen
- Implement necessary tags for price chargeback
- Management general price profile by limiting per-cluster most price, e.g. max DBUs per hour or max compute sources per person
AI-powered Value Optimisation
The Databricks Information Intelligence Platform integrates superior AI options which optimizes efficiency, reduces prices, improves governance, and simplifies enterprise AI software growth. Predictive I/O and Liquid Clustering improve question speeds and useful resource utilization, whereas clever workload administration optimizes autoscaling for price effectivity. General, Databricks’ platform affords a complete suite of AI instruments to drive productiveness and value financial savings whereas enabling modern options for industry-specific use circumstances.
Liquid clustering
Delta Lake liquid clustering replaces desk partitioning and ZORDER to simplify knowledge format choices and optimize question efficiency. Liquid clustering supplies flexibility to redefine clustering keys with out rewriting present knowledge, permitting knowledge format to evolve alongside analytical wants over time.
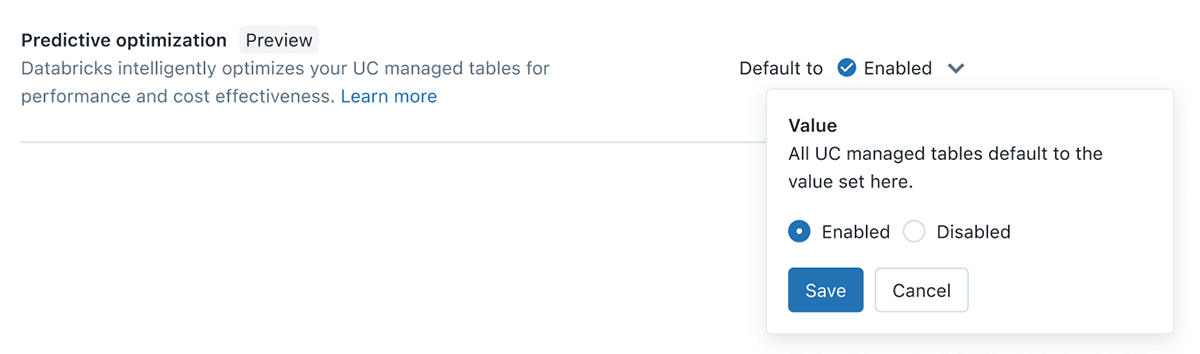
Predictive Optimization
Information engineers on the lakehouse might be conversant in the necessity to often OPTIMIZE & VACUUM their tables, nonetheless this creates ongoing challenges to determine the appropriate tables, the suitable schedule and the appropriate compute dimension for these duties to run. With Predictive Optimization, we leverage Unity Catalog and Lakehouse AI to find out the very best optimizations to carry out in your knowledge, after which run these operations on purpose-built serverless infrastructure. This all occurs mechanically, guaranteeing the very best efficiency with no wasted compute or guide tuning effort.
Materialized View with Incremental Refresh
In Databricks, Materialized Views (MVs) are Unity Catalog managed tables that enable customers to precompute outcomes based mostly on the most recent model of knowledge in supply tables. Constructed on prime of Delta Dwell Tables & serverless, MVs scale back question latency by pre-computing in any other case sluggish queries and often used computations. When attainable, outcomes are up to date incrementally, however outcomes are equivalent to people who can be delivered by full recomputation. This reduces computational price and avoids the necessity to preserve separate clusters
Serverless options for Mannequin Serving & Gen AI use circumstances
To raised help mannequin serving and Gen AI use circumstances, Databricks have launched a number of capabilities on prime of our serverless infrastructure that mechanically scales to your workflows with out the necessity to configure situations and server sorts.
- Vector Search: Vector index that may be synchronized from any Delta Desk with 1-click – no want for advanced, customized constructed knowledge ingestion/sync pipelines.
- On-line Tables: Totally serverless tables that auto-scale throughput capability with the request load and supply low latency and excessive throughput entry to knowledge of any scale
- Mannequin Serving: extremely obtainable and low-latency service for deploying fashions. The service mechanically scales up or down to satisfy demand adjustments, saving infrastructure prices whereas optimizing latency efficiency
Predictive I/O for updates and Deletes
With these AI powered options Databricks SQL now can analyze historic learn and write patterns to intelligently construct indexes and optimize workloads. Predictive I/O is a set of Databricks optimizations that enhance efficiency for knowledge interactions. Predictive I/O capabilities are grouped into the next classes:
- Accelerated reads scale back the time it takes to scan and skim knowledge. It makes use of deep studying strategies to attain this. Extra particulars may be discovered on this documentation
- Accelerated updates scale back the quantity of knowledge that must be rewritten throughout updates, deletes, and merges.Predictive I/O leverages deletion vectors to speed up updates by lowering the frequency of full file rewrites throughout knowledge modification on Delta tables. Predictive I/O optimizes
DELETE,MERGE, andUPDATEoperations.Extra particulars may be discovered on this documentation
Predictive I/O is unique to the Photon engine on Databricks.
Clever workload administration (IWM)
One of many main ache factors of technical platform admins is to handle totally different warehouses for small and huge workloads and ensure code is optimized and positive tuned to run optimally and leverage the total capability of the compute infrastructure. IWM is a set of options that helps with above challenges and helps run these workloads sooner whereas preserving the fee down. It achieves this by analyzing actual time patterns and guaranteeing that the workloads have the optimum quantity of compute to execute the incoming SQL statements with out disrupting already-running queries.
The correct FinOps basis – by way of tagging, insurance policies, and reporting – is essential for transparency and ROI in your Information Intelligence Platform. It helps you understand enterprise worth sooner and construct a extra profitable firm.
Use serverless and DatabricksIQ for speedy setup, cost-efficiency, and computerized optimizations that adapt to your workload patterns. This results in decrease TCO, higher reliability, and easier, more cost effective operations.