{kind=link}
benchmark is one which clearly exhibits which fashions are higher and that are worse. The Databricks Mosaic Analysis workforce is devoted to discovering nice measurement instruments that enable researchers to judge experiments. The Mosaic Analysis Gauntlet is our set of benchmarks for evaluating the standard of fashions and consists of 39 publicly accessible benchmarks break up throughout 6 core competencies: language understanding, studying comprehension, symbolic downside fixing, world information, commonsense, and programming. As a way to prioritize the metrics which can be most helpful for analysis duties throughout mannequin scales, we examined the benchmarks utilizing a collection of more and more superior fashions.
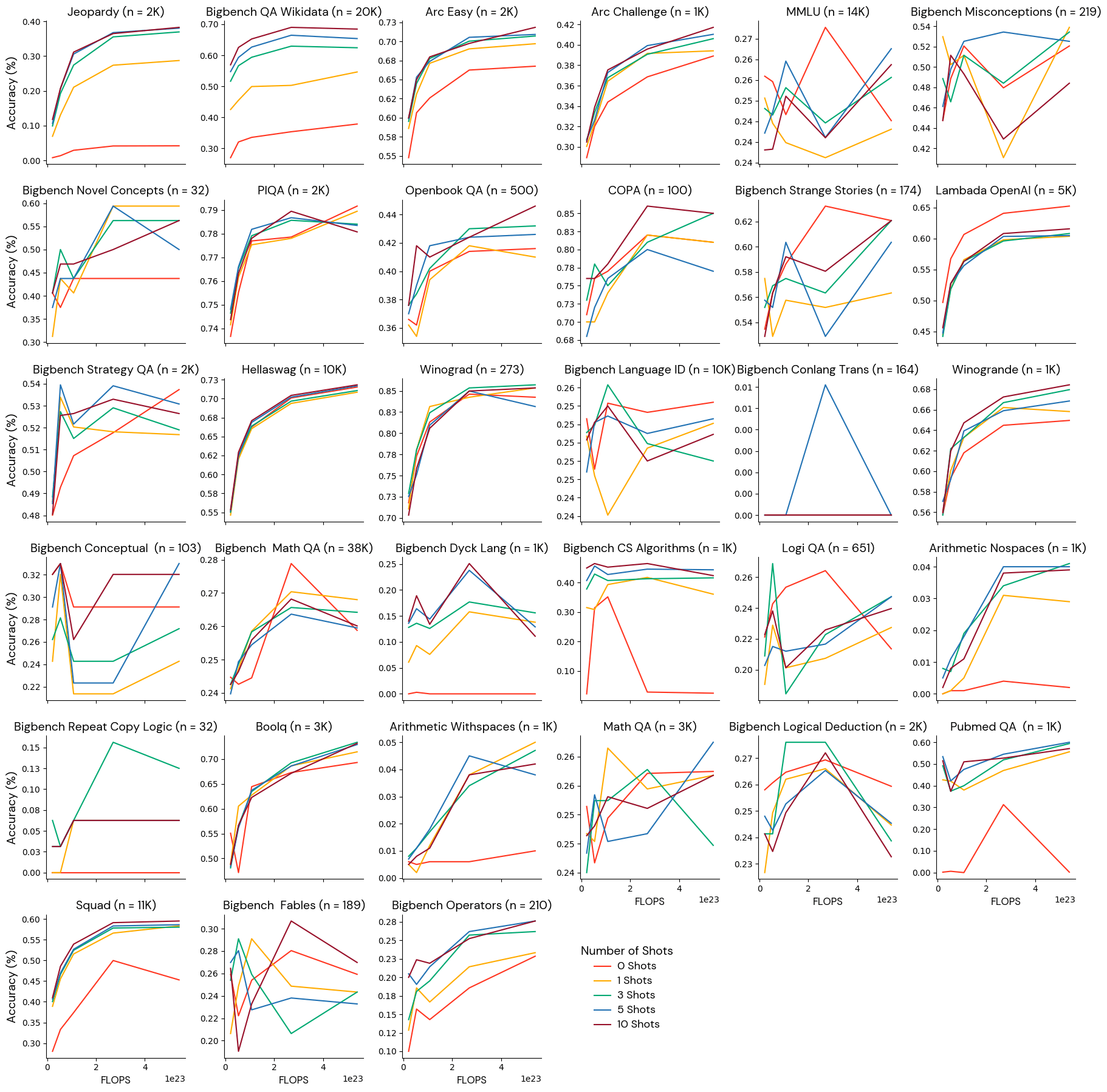
Latest analysis, notably the Chinchilla paper from DeepMind, has demonstrated that scaling up language fashions by growing each their parameter rely and coaching information dimension results in vital efficiency enhancements. To establish a dependable set of benchmarks, we will leverage the well-established relationship between a mannequin’s efficiency and its scale. Assuming that scaling legal guidelines are a stronger floor reality than every particular person benchmark, we examined which benchmarks may rank order the fashions accurately from least to most coaching FLOPS.
We educated 5 fashions with progressively bigger quantities of coaching information: from a ratio of 20 tokens per parameter to a ratio of 500 tokens per parameter. Every mannequin had 3 billion parameters, so the full FLOPS ranged from 2.1e22 to five.4e23 FLOPS. We then chosen the metrics that monotonically ranked the fashions from the least to probably the most coaching FLOPS.
Outcomes
We sorted the metrics into 4 teams: (1) well-behaved and strong to few-shot settings, (2) well-behaved given a sure variety of few-shot examples, (3) not higher than noise, and (4) poorly behaved.
Group 1: Effectively-behaved metrics strong to few-shot settings
These benchmarks reliably ordered fashions by coaching scale and monotonically improved at any variety of photographs. We imagine that these benchmarks can present a dependable analysis sign for fashions on this vary.
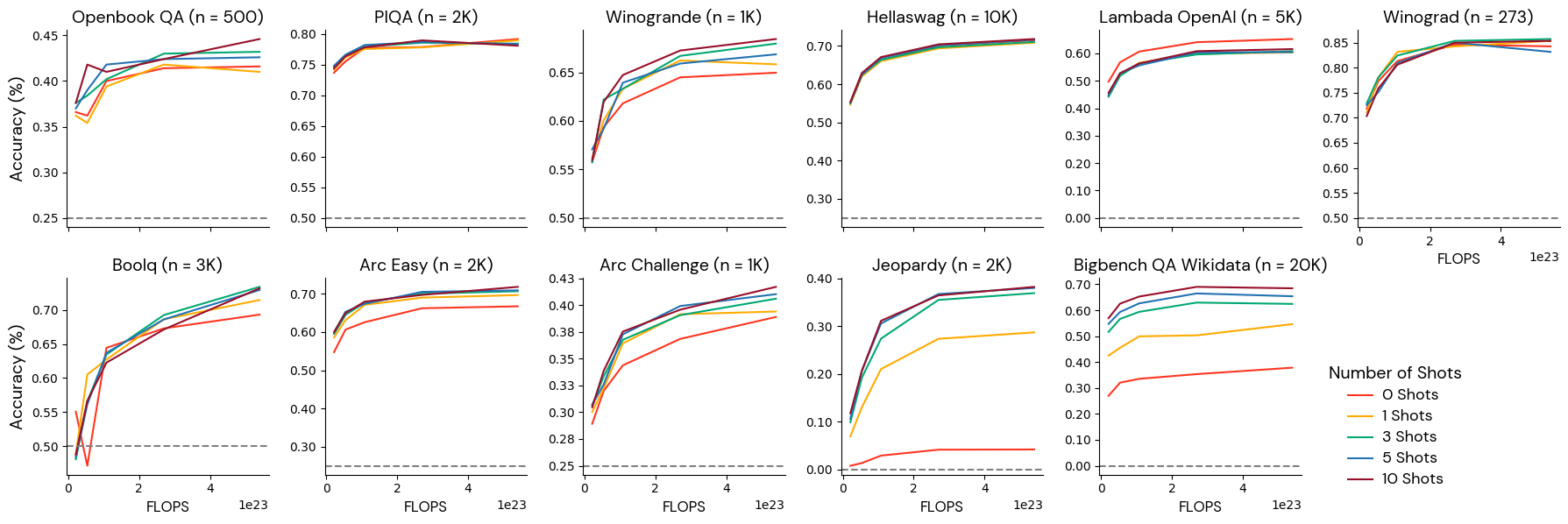
Group 2: Effectively-behaved at particular few-shot settings
These benchmarks had been monotonically associated to the mannequin scale at some few-shot settings however unrelated to the mannequin scale at different few-shot settings. For instance, BigBench Technique QA was monotonically associated to the mannequin scale if supplied with 0 photographs however was anti-correlated with the dimensions if given 1 shot. We suggest utilizing these metrics with a dependable few-shot setting.

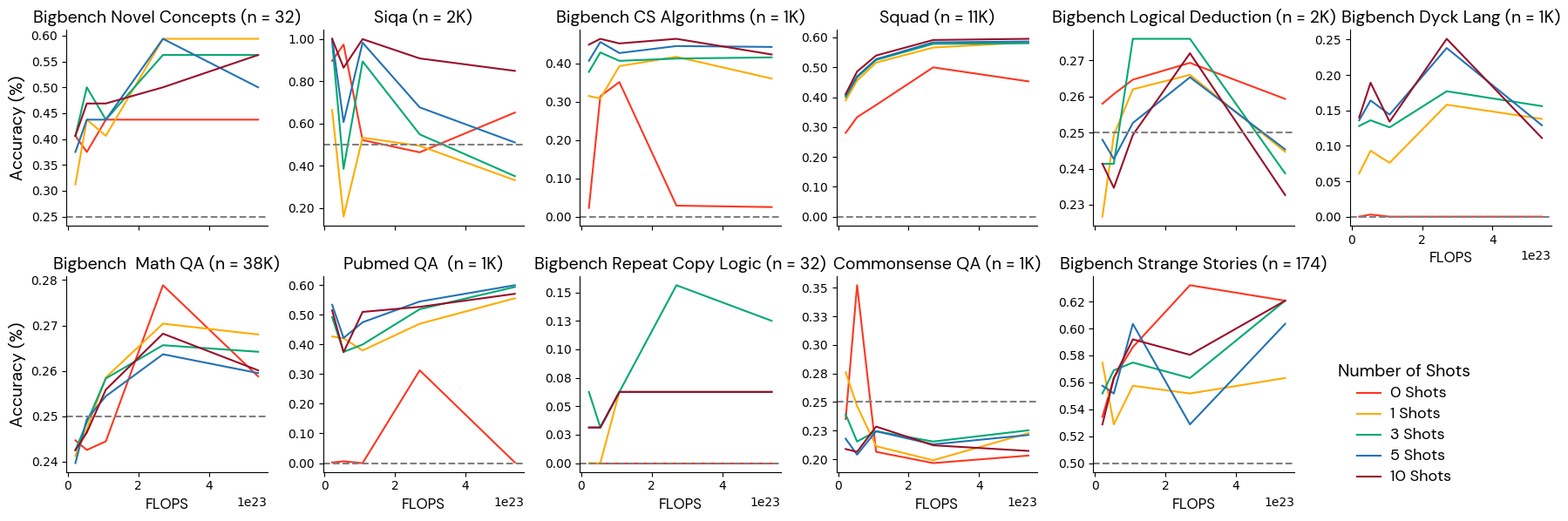
Group 3: Poorly behaved benchmarks
These benchmarks didn’t monotonically enhance with extra token length at this mannequin scale. Some benchmarks on this class truly received worse with scale. These benchmarks may mislead researchers about what choices to make with their experimental outcomes. We hypothesize that this conduct could also be because of the truth that benchmarks on this class include label imbalance (if one reply is extra frequent than the others, fashions could be biased and provides the extra frequent reply), low data content material (the identical query is repeatedly requested with solely minor variations), or inter-labeler disagreement (two consultants wanting on the identical query dispute the right reply). Guide inspection and filtering of those benchmarks could also be required.
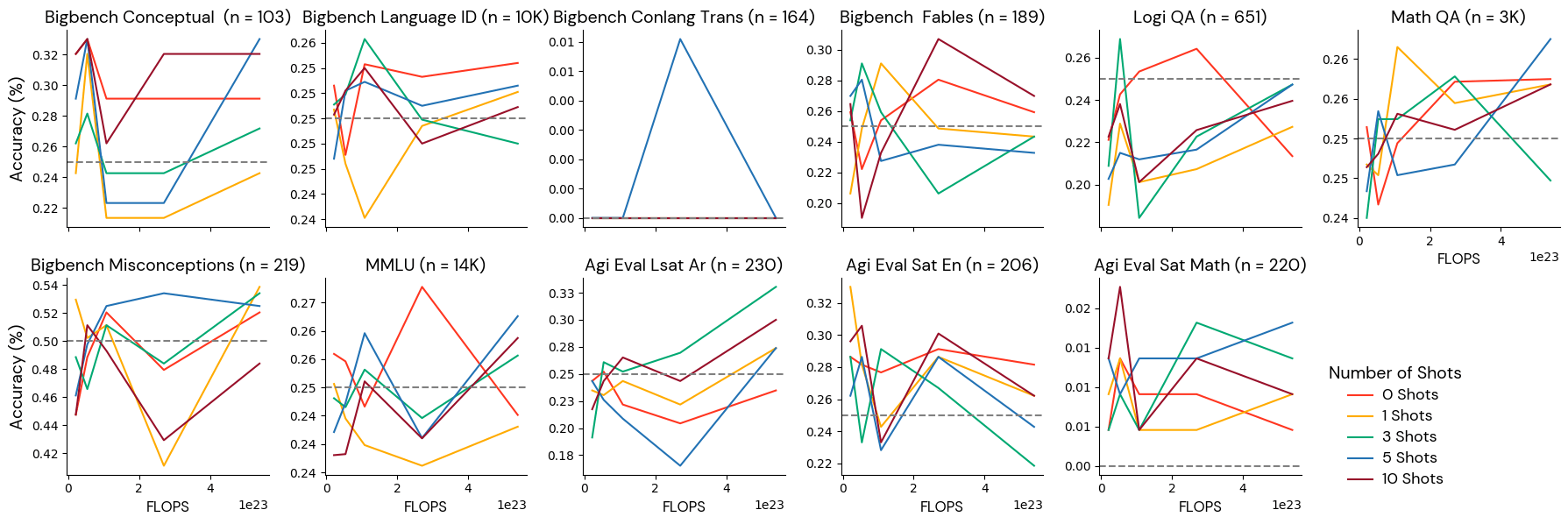
Group 4: Noise degree benchmarks
The fashions don’t do higher than random guessing on these benchmarks, and scores don’t reliably enhance with extra coaching at this scale. These benchmarks are too troublesome for fashions of this scale (2.1e22- 5.4e23 FLOPS), and researchers needs to be cautious about drawing conclusions from experiments utilizing these benchmarks for small fashions. Notice that this class consists of benchmarks which can be in style and helpful for extra succesful fashions, like MMLU, so we stored the duties on this class regardless of their tendency so as to add noise to the combination Gauntlet. We suggest utilizing warning when counting on these benchmarks for any of the combos of mannequin sizes and token counts we thought of on this examine for the reason that outcomes don’t seem informative.
Conclusion and Limitations
After operating this calibration experiment we modified the composition of our Analysis Gauntlet to take away duties from Group 3: Poorly Behaved Benchmarks. This diminished the quantity of noise in our combination rating. We stored the noisy benchmarks (Group 4) as a result of they measure efficiency on duties we’re concerned about bettering on, specifically math and MMLU. We nonetheless suggest warning when counting on the benchmarks in Group 4. We chosen a default few-shot setting for the benchmarks in Group 2 based mostly on the power and monotonicity of their correlation with FLOPS.
Whereas the connection between mannequin scale and benchmark efficiency is nicely established, it is potential that any given benchmark measures capabilities that don’t at all times enhance with mannequin scale. On this case, the choices we made utilizing this calibration methodology could be misguided. Moreover, our evaluation relied on a restricted set of mannequin scales and architectures. It is potential that totally different mannequin households would exhibit distinct scaling conduct on these benchmarks. Future work may discover a wider vary of mannequin sizes and kinds to additional validate the robustness of those findings.
Regardless of these limitations, this calibration train gave us a principled method to refining benchmark suites as fashions progress. By aligning our analysis methodology with the empirical scaling properties of language fashions, we will extra successfully monitor and examine their evolving capabilities. You’ll be able to take a look at your personal analysis metrics utilizing our analysis framework in our LLM Foundry repo. Prepared to coach your fashions on the Mosaic AI coaching infrastructure? Contact us as we speak.
Acknowledgments
Due to Mansheej Paul for the unique concept and for architecting the experiments, Sasha Doubov for coaching the fashions, and Jeremy Dohmann for creating the unique Gauntlet.