The generative AI revolution is remodeling the way in which that groups work, and Databricks Assistant leverages one of the best of those developments. It means that you can question knowledge by way of a conversational interface, making you extra productive inside your Databricks Workspace. The Assistant is powered by DatabricksIQ, the Information Intelligence Engine for Databricks, serving to to make sure your knowledge is secured and responses are correct and tailor-made to the specifics of your enterprise. Databricks Assistant helps you to describe your job in pure language to generate, optimize, or debug complicated code with out interrupting your developer expertise.
On this submit, we broaden on weblog 5 tricks to get probably the most out of your Databricks Assistant and deal with how the Assistant can enhance the lifetime of Information Engineers by eliminating tedium, growing productiveness and immersion, and accelerating time to worth. We’ll comply with up with a sequence of posts targeted on completely different knowledge practitioner personas, so keep tuned for upcoming entries targeted on knowledge scientists, SQL analysts, and extra.
Ingestion
When working with Databricks as an information engineer, ingesting knowledge into Delta Lake tables is commonly step one. Let’s check out two examples of how the Assistant helps load knowledge, one from APIs, and one from information in cloud storage. For every, we are going to share the immediate and outcomes. As talked about within the 5 ideas weblog, being particular in a immediate offers one of the best outcomes, a method persistently used on this article.
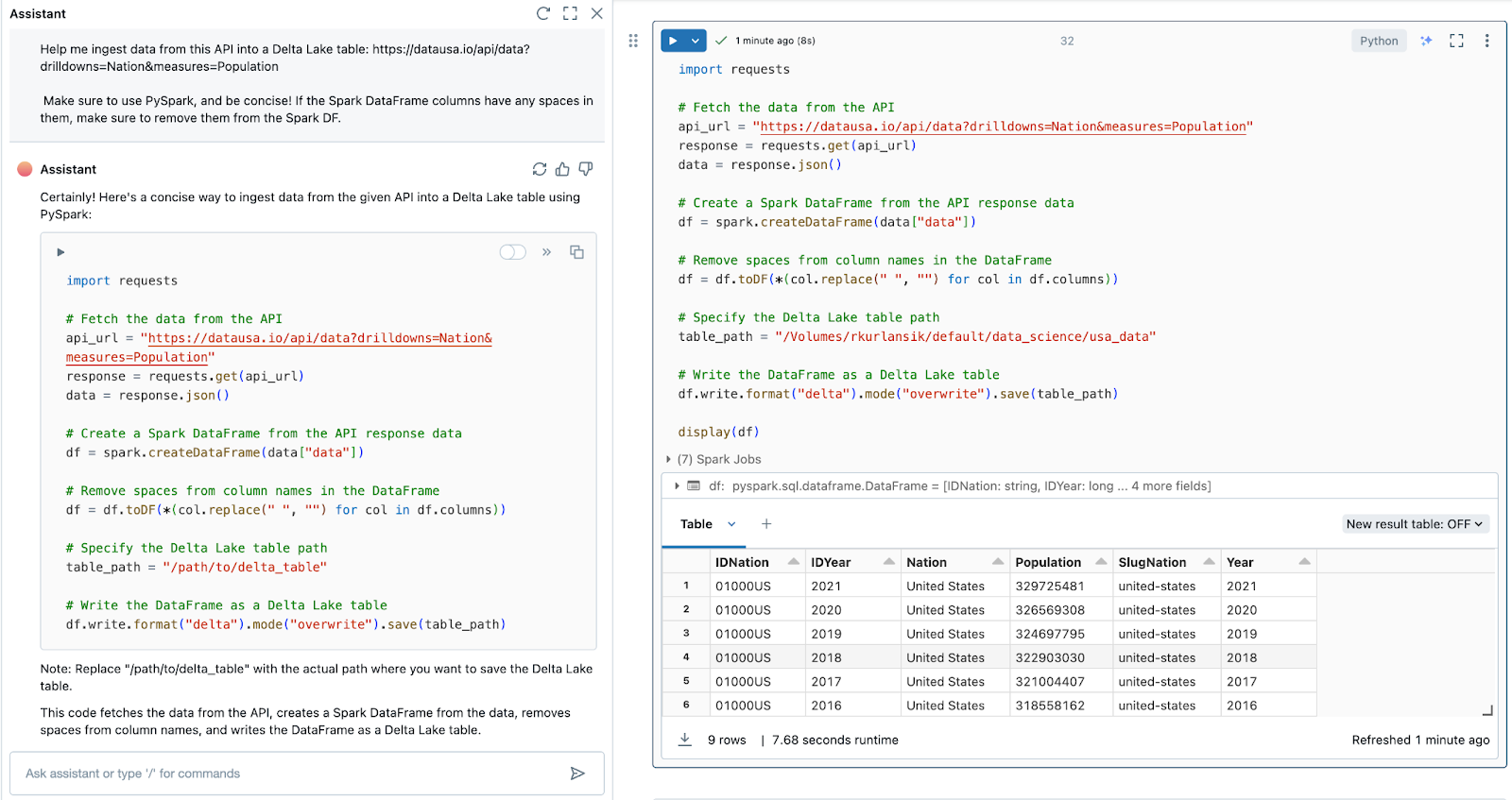
To get knowledge from the datausa.io API and cargo it right into a Delta Lake desk with Python, we used the next immediate:
Assist me ingest knowledge from this API right into a Delta Lake desk: https://datausa.io/api/knowledge?drilldowns=Nation&measures=Inhabitants
Ensure that to make use of PySpark, and be concise! If the Spark DataFrame columns have any areas in them, be sure to take away them from the Spark DF.
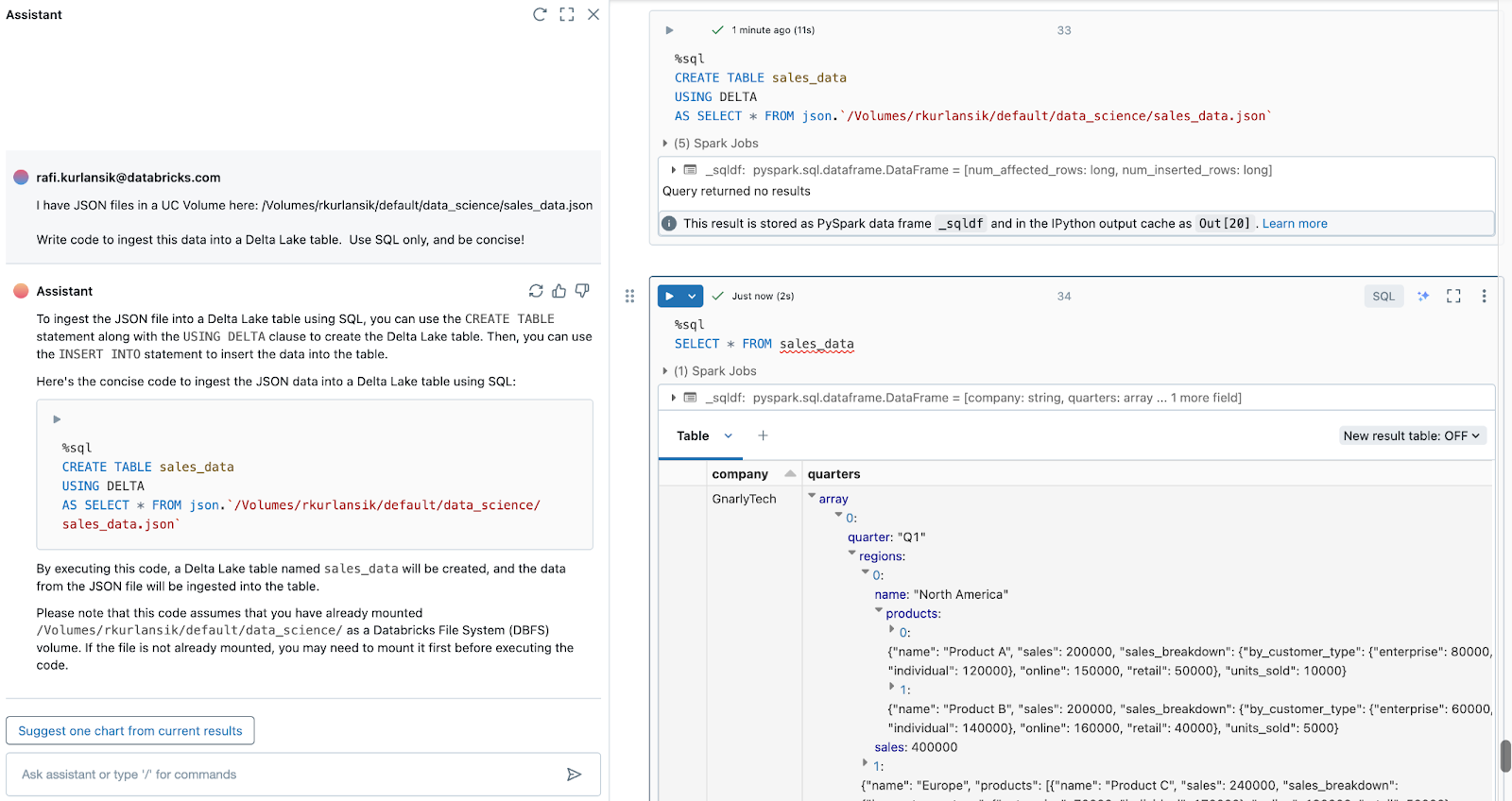
An identical immediate can be utilized to ingest JSON information from cloud storage into Delta Lake tables, this time utilizing SQL:
I’ve JSON information in a UC Quantity right here: /Volumes/rkurlansik/default/data_science/sales_data.json
Write code to ingest this knowledge right into a Delta Lake desk. Use SQL solely, and be concise!
Reworking knowledge from unstructured to structured
Following tidy knowledge rules, any given cell of a desk ought to comprise a single remark with a correct knowledge kind. Complicated strings or nested knowledge buildings are sometimes at odds with this precept, and consequently, knowledge engineering work consists of extracting structured knowledge from unstructured knowledge. Let’s discover two examples the place the Assistant excels at this job – utilizing common expressions and exploding nested knowledge buildings.
Common expressions
Common expressions are a method to extract structured knowledge from messy strings, however determining the right regex takes time and is tedious. On this respect, the Assistant is a boon for all knowledge engineers who wrestle with regex.
Think about this instance utilizing the Title column from the IMDb dataset:

This column incorporates two distinct observations – movie title and launch 12 months. With the next immediate, the Assistant identifies an applicable common expression to parse the string into a number of columns.
Right here is an instance of the Title column in our dataset: 1. The Shawshank Redemption (1994). The title identify will probably be between the quantity and the parentheses, and the discharge date is between parentheses. Write a operate that extracts each the discharge date and the title identify from the Title column within the imdb_raw DataFrame.
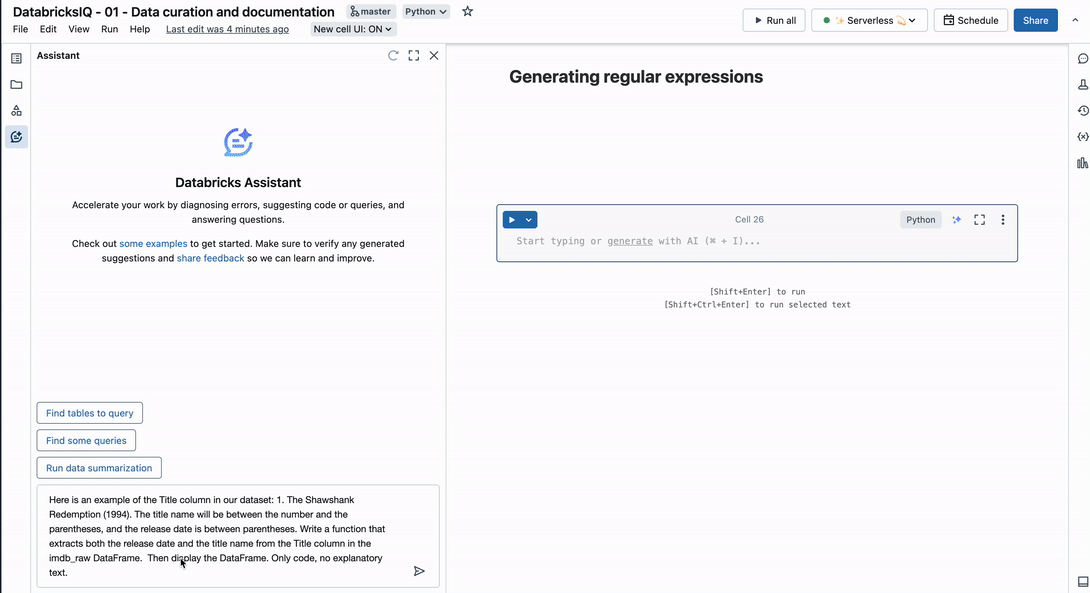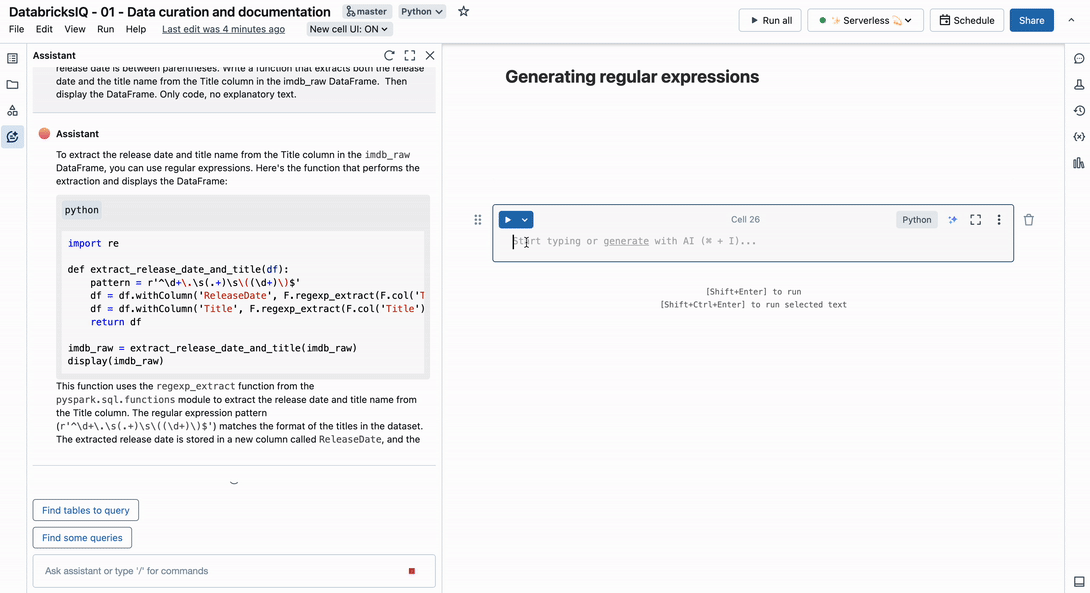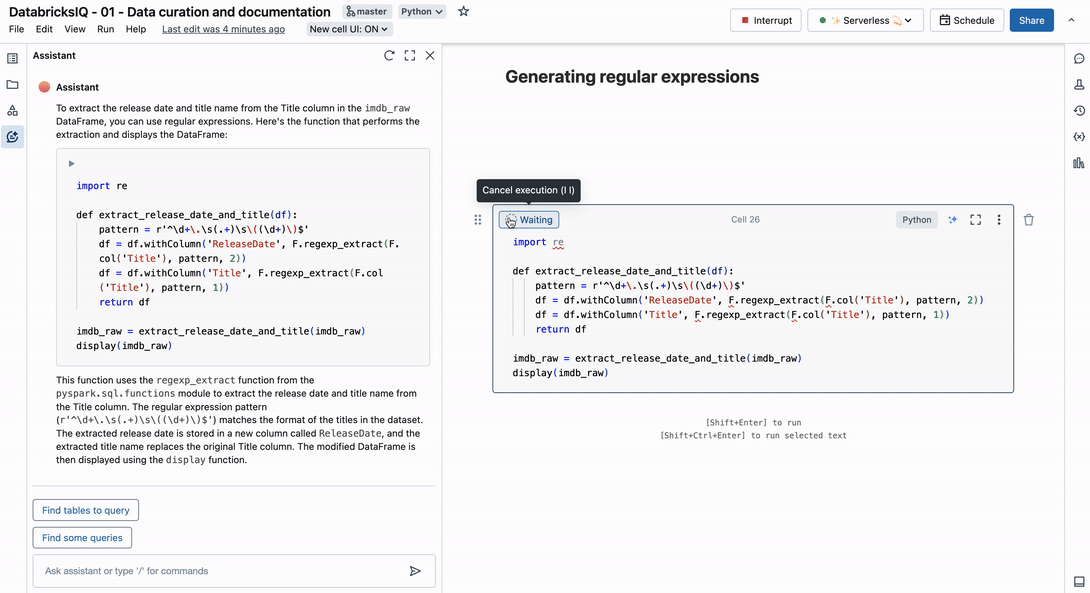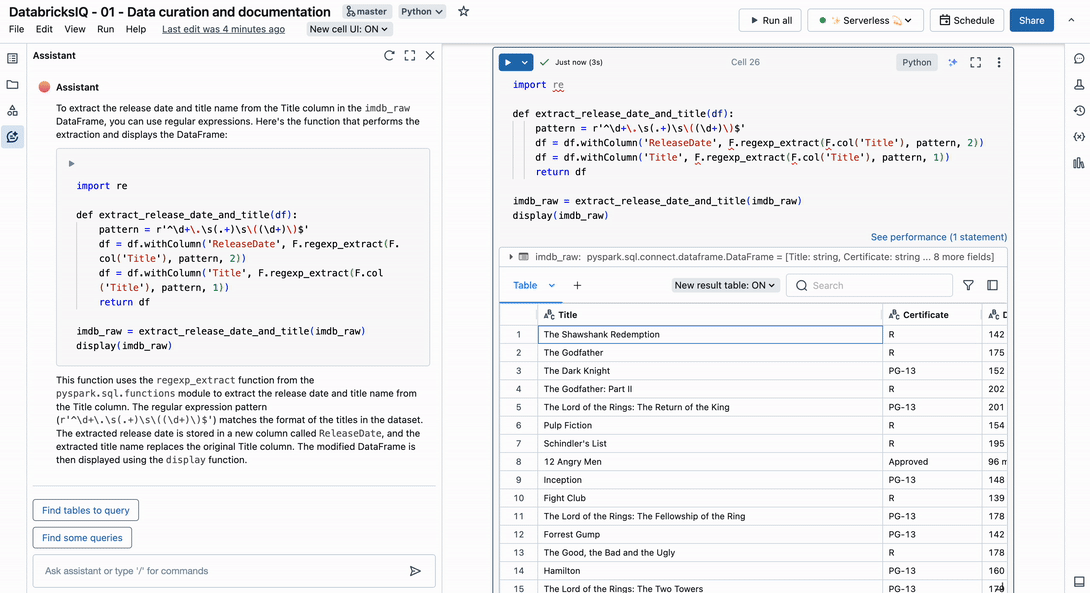
Offering an instance of the string in our immediate helps the Assistant discover the right outcome. In case you are working with delicate knowledge, we suggest making a pretend instance that follows the identical sample. In any case, now you could have one much less drawback to fret about in your knowledge engineering work.
Nested Structs, Arrays (JSON, XML, and so on)
When ingesting knowledge by way of API, JSON information in storage, or noSQL databases, the ensuing Spark DataFrames might be deeply nested and difficult to flatten appropriately. Check out this mock gross sales knowledge in JSON format:
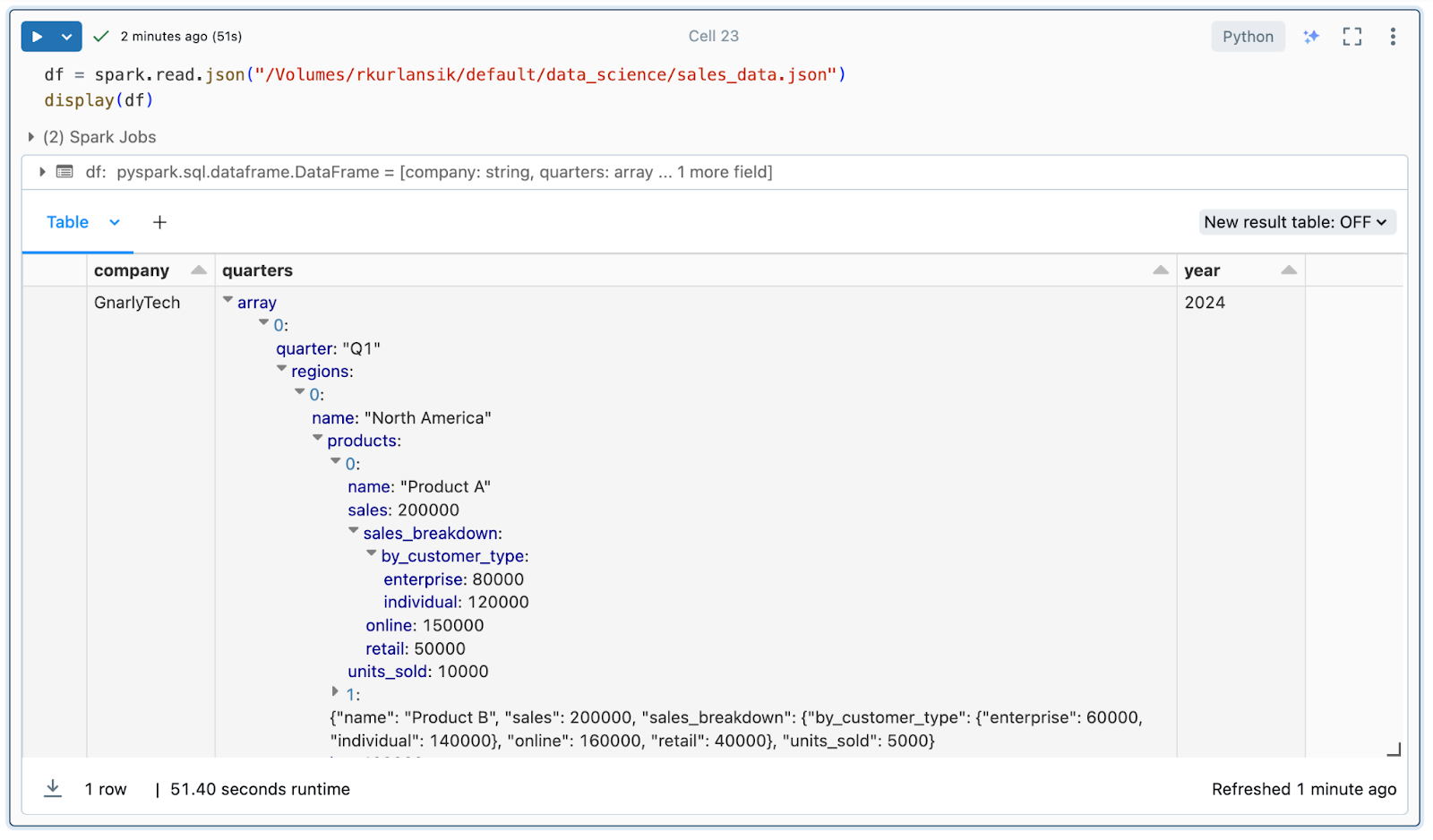
Information engineers could also be requested to flatten the nested array and extract income metrics for every product. Usually this job would take vital trial and error – even in a case the place the info is comparatively simple. The Assistant, nevertheless, being context-aware of the schemas of DataFrames you could have in reminiscence, generates code to get the job executed. Utilizing a easy immediate, we get the outcomes we’re in search of in seconds.
Write PySpark code to flatten the df and extract income for every product and buyer

Refactoring, debugging and optimization
One other situation knowledge engineers face is rewriting code authored by different staff members, both ones which may be extra junior or have left the corporate. In these circumstances, the Assistant can analyze and clarify poorly written code by understanding its context and intent. It could actually recommend extra environment friendly algorithms, refactor code for higher readability, and add feedback.
Enhancing documentation and maintainability
This Python code calculates the entire price of things in a web based procuring cart.
def calculate_total(cart_items):
complete = 0
for i in vary(len(cart_items)):
if cart_items[i]['type'] == 'e book':
low cost = cart_items[i]['price'] * 0.05
complete += cart_items[i]['price'] - low cost
else:
complete += cart_items[i]['price']
return complete
cart_items = [{'name': 'Python Programming', 'type': 'book', 'price': 50},
{'name': 'Laptop', 'type': 'electronics', 'price': 800}]
total_price = calculate_total(cart_items)The usage of conditional blocks on this code makes it onerous to learn and inefficient at scale. Moreover, there are not any feedback to clarify what is occurring. A very good place to start is to ask the Assistant to clarify the code step-by-step. As soon as the info engineer understands the code, the Assistant can rework it, making it extra performant and readable with the next immediate:
Rewrite this code in a manner that’s extra performant, commented correctly, and documented in keeping with Python operate documentation requirements
The generated instance beneath correctly paperwork the code, and makes use of generator expressions as an alternative of conditional blocks to enhance reminiscence utilization on bigger datasets.
def calculate_total(cart_items):
"""
Calculate the entire value of things within the procuring cart.
Apply a 5% low cost to e book gadgets. The whole is calculated by summing
the costs, making an allowance for the low cost for books.
Parameters:
cart_items (checklist of dict): An inventory of dictionaries, the place every dictionary
represents an merchandise within the cart with keys 'identify',
'kind', and 'value'.
Returns:
float: The whole value of all gadgets within the cart after reductions.
"""
# Use a generator expression to iterate over cart gadgets, making use of a 5% low cost to books.
return sum(merchandise['price'] * 0.95 if merchandise['type'] == 'e book' else merchandise['price'] for merchandise in cart_items)
# Instance utilization
cart_items = [{'name': 'Python Programming', 'type': 'book', 'price': 50},
{'name': 'Laptop', 'type': 'electronics', 'price': 800}]
total_price = calculate_total(cart_items)Diagnosing errors
Inevitably, knowledge engineers might want to debug. The Assistant eliminates the necessity to open a number of browser tabs or swap contexts as a way to establish the reason for errors in code, and staying targeted is an incredible productiveness increase. To grasp how this works with the Assistant, let’s create a easy PySpark DataFrame and set off an error.
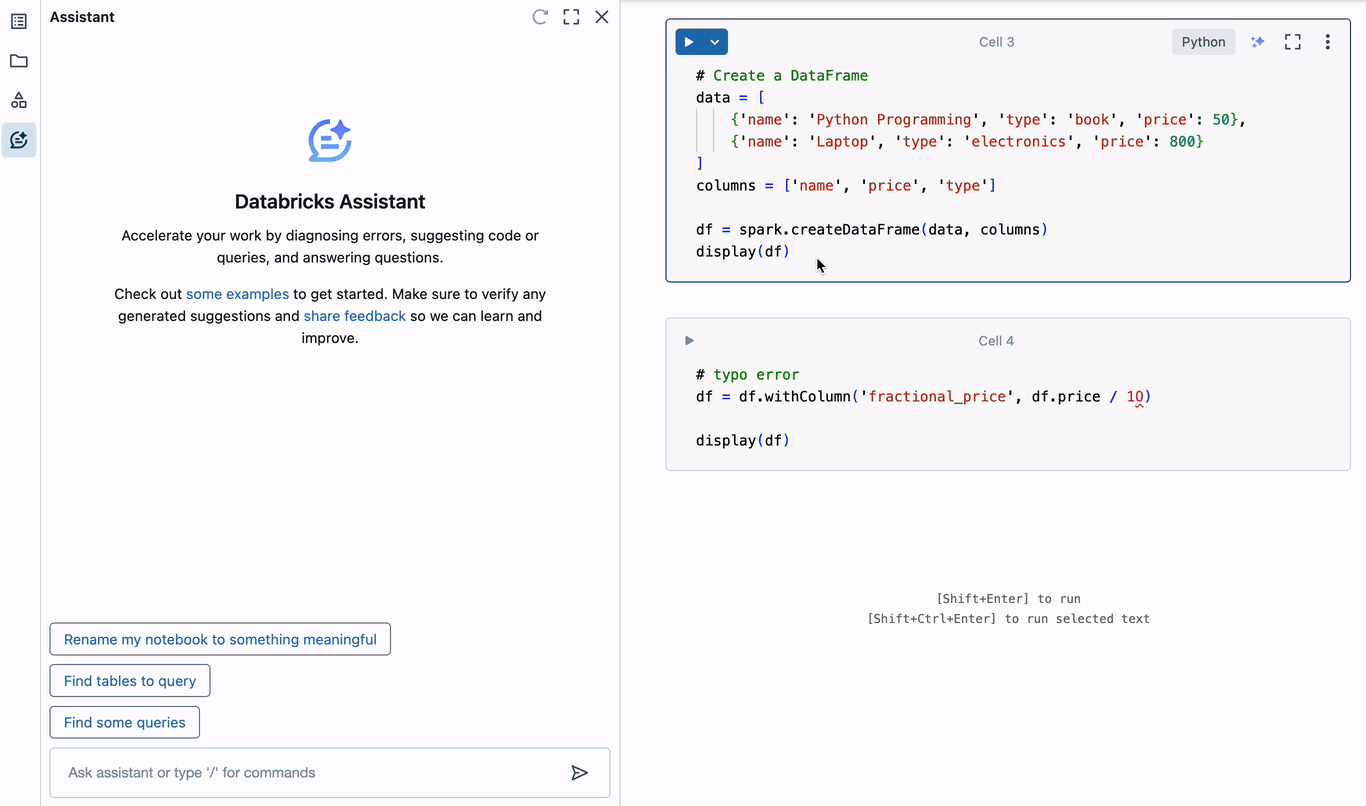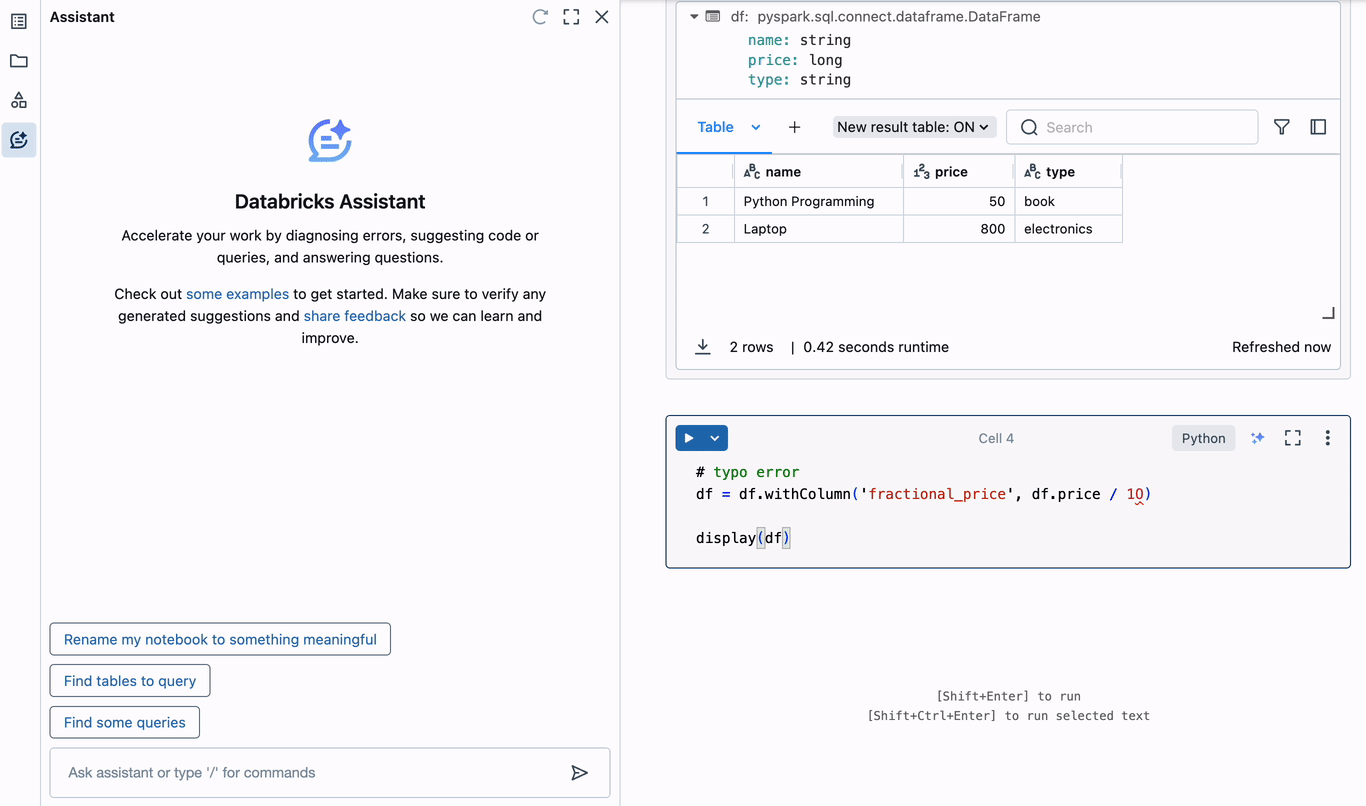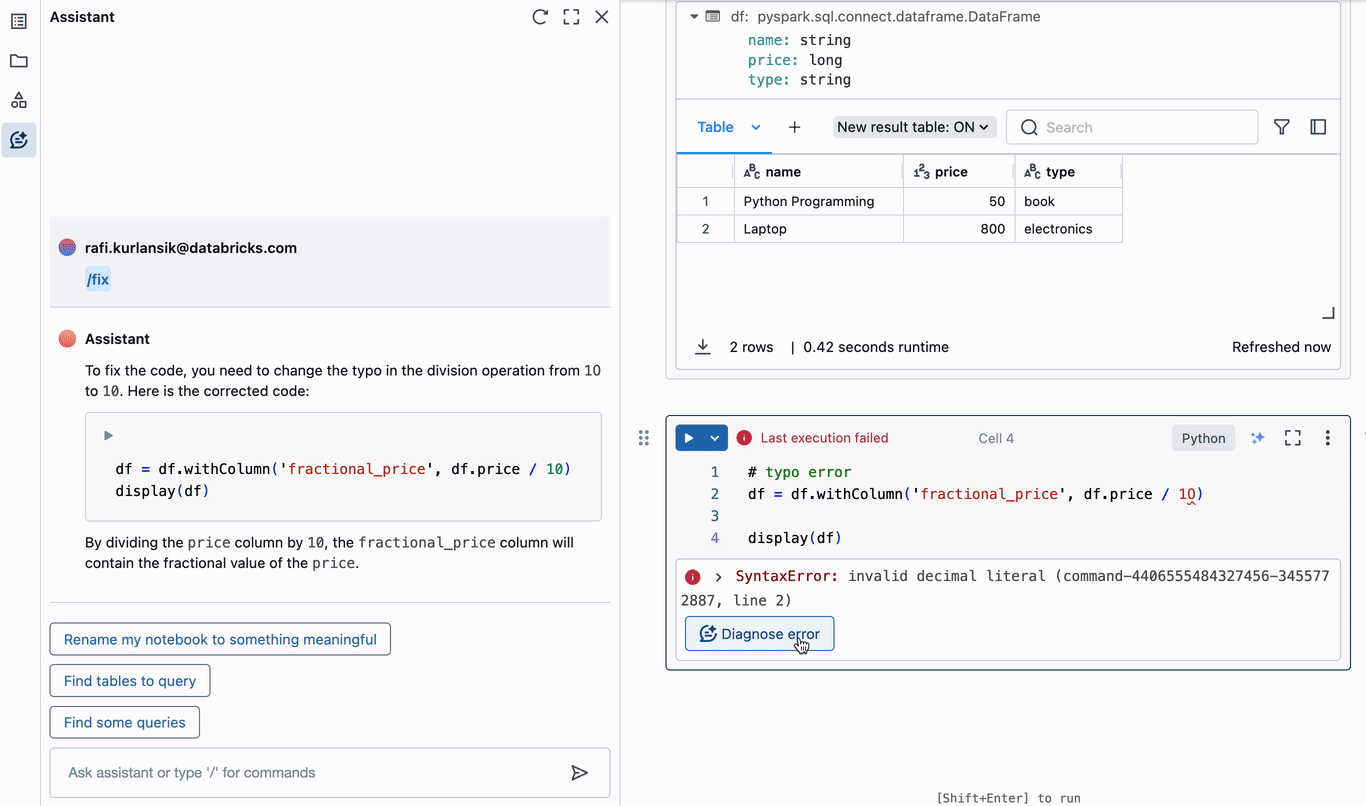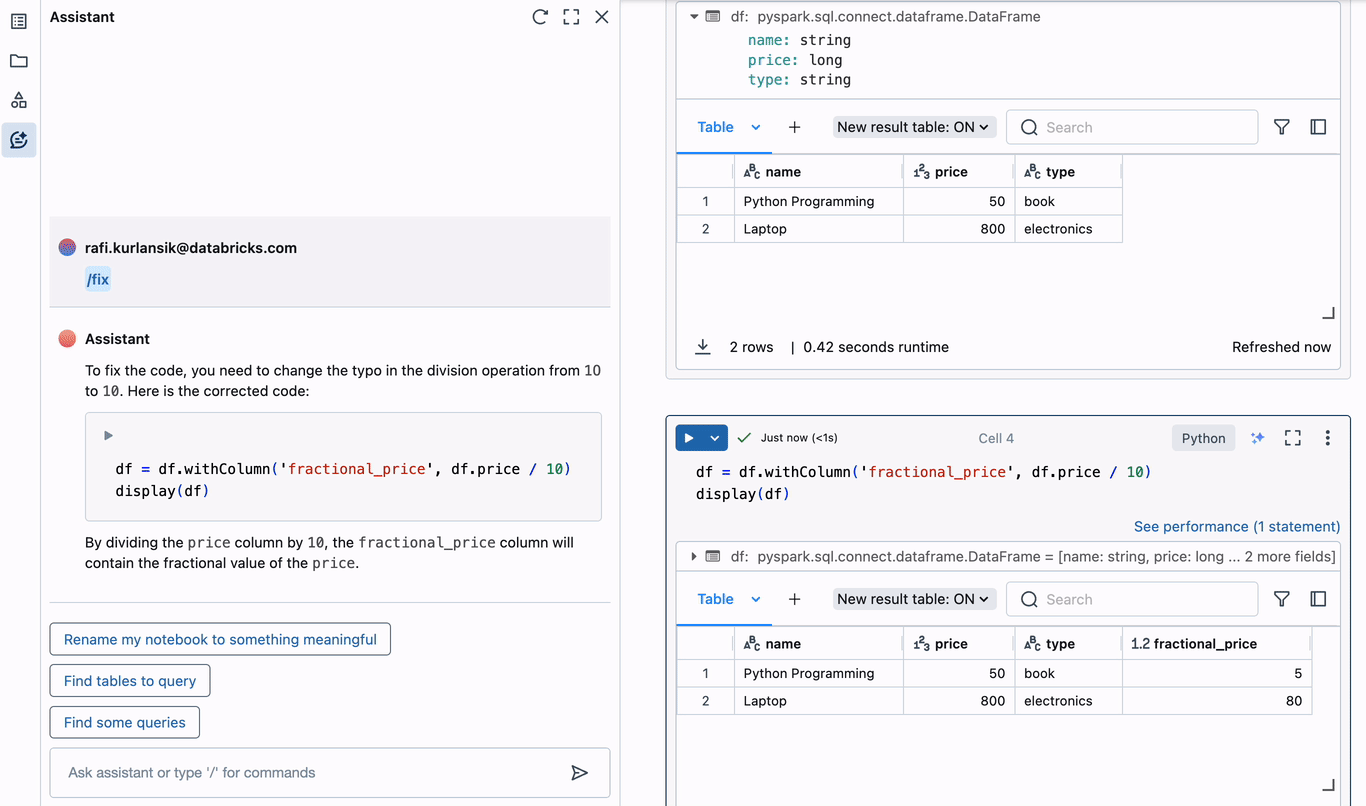
Within the above instance, a typo is launched when including a brand new column to the DataFrame. The zero in “10” is definitely the letter “O”, resulting in an invalid decimal literal syntax error. The Assistant instantly provides to diagnose the error. It appropriately identifies the typo, and suggests corrected code that may be inserted into the editor within the present cell. Diagnosing and correcting errors this manner can save hours of time spent debugging.
Transpiling pandas to PySpark
Pandas is among the most profitable data-wrangling libraries in Python and is utilized by knowledge scientists in all places. Sticking with our JSON gross sales knowledge, let’s think about a scenario the place a novice knowledge scientist has executed their greatest to flatten the info utilizing pandas. It isn’t fairly, it doesn’t comply with greatest practices, however it produces the right output:
import pandas as pd
import json
with open("/Volumes/rkurlansik/default/data_science/sales_data.json") as file:
knowledge = json.load(file)
# Unhealthy observe: Manually initializing an empty DataFrame and utilizing a deeply nested for-loop to populate it.
df = pd.DataFrame(columns=['company', 'year', 'quarter', 'region_name', 'product_name', 'units_sold', 'product_sales'])
for quarter in knowledge['quarters']:
for area in quarter['regions']:
for product in area['products']:
df = df.append({
'firm': knowledge['company'],
'12 months': knowledge['year'],
'quarter': quarter['quarter'],
'region_name': area['name'],
'product_name': product['name'],
'units_sold': product['units_sold'],
'product_sales': product['sales']
}, ignore_index=True)
# Inefficient conversion of columns after knowledge has been appended
df['year'] = df['year'].astype(int)
df['units_sold'] = df['units_sold'].astype(int)
df['product_sales'] = df['product_sales'].astype(int)
# Mixing entry types and modifying the dataframe in-place in an inconsistent method
df['company'] = df.firm.apply(lambda x: x.higher())
df['product_name'] = df['product_name'].str.higher()By default, Pandas is proscribed to operating on a single machine. The info engineer shouldn’t put this code into manufacturing and run it on billions of rows of knowledge till it’s transformed to PySpark. This conversion course of contains guaranteeing the info engineer understands the code and rewrites it in a manner that’s maintainable, testable, and performant. The Assistant as soon as once more comes up with a greater answer in seconds.
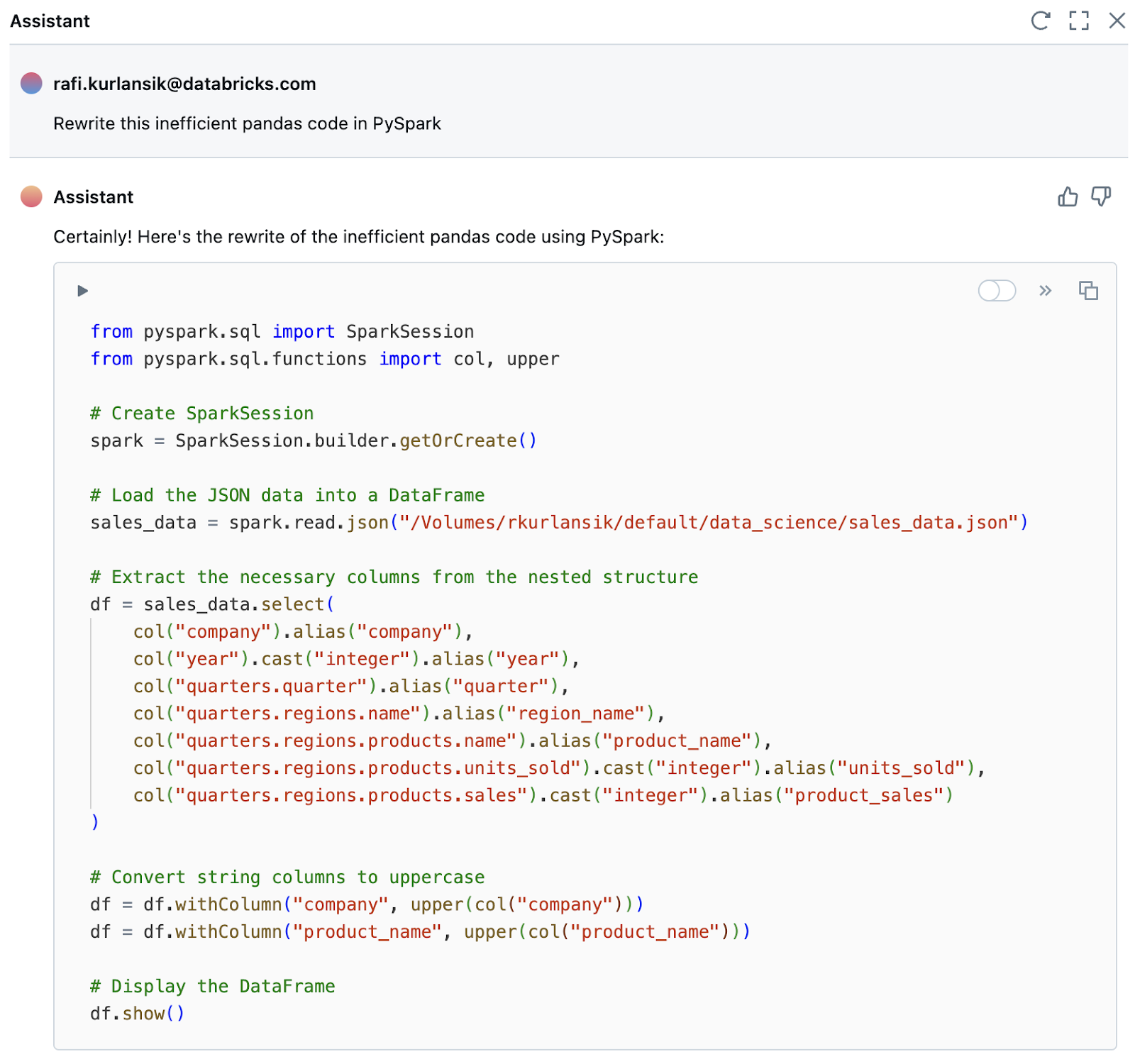
Be aware the generated code contains making a SparkSession, which isn’t required in Databricks. Generally the Assistant, like all LLM, might be unsuitable or hallucinate. You, the info engineer, are the last word creator of your code and it is very important evaluate and perceive any code generated earlier than continuing to the subsequent job. If you happen to discover one of these habits, alter your immediate accordingly.
Writing exams
Some of the essential steps in knowledge engineering is to write down exams to make sure your DataFrame transformation logic is appropriate, and to doubtlessly catch any corrupted knowledge flowing by way of your pipeline. Persevering with with our instance from the JSON gross sales knowledge, the Assistant makes it a breeze to check if any of the income columns are damaging – so long as values within the income columns are usually not lower than zero, we might be assured that our knowledge and transformations on this case are appropriate.

Write a check utilizing assertDataFrameEqual from pyspark.testing.utils to test that an empty DataFrame has the identical variety of rows as our damaging income DataFrame.
The Assistant obliges, offering working code to bootstrap our testing efforts.
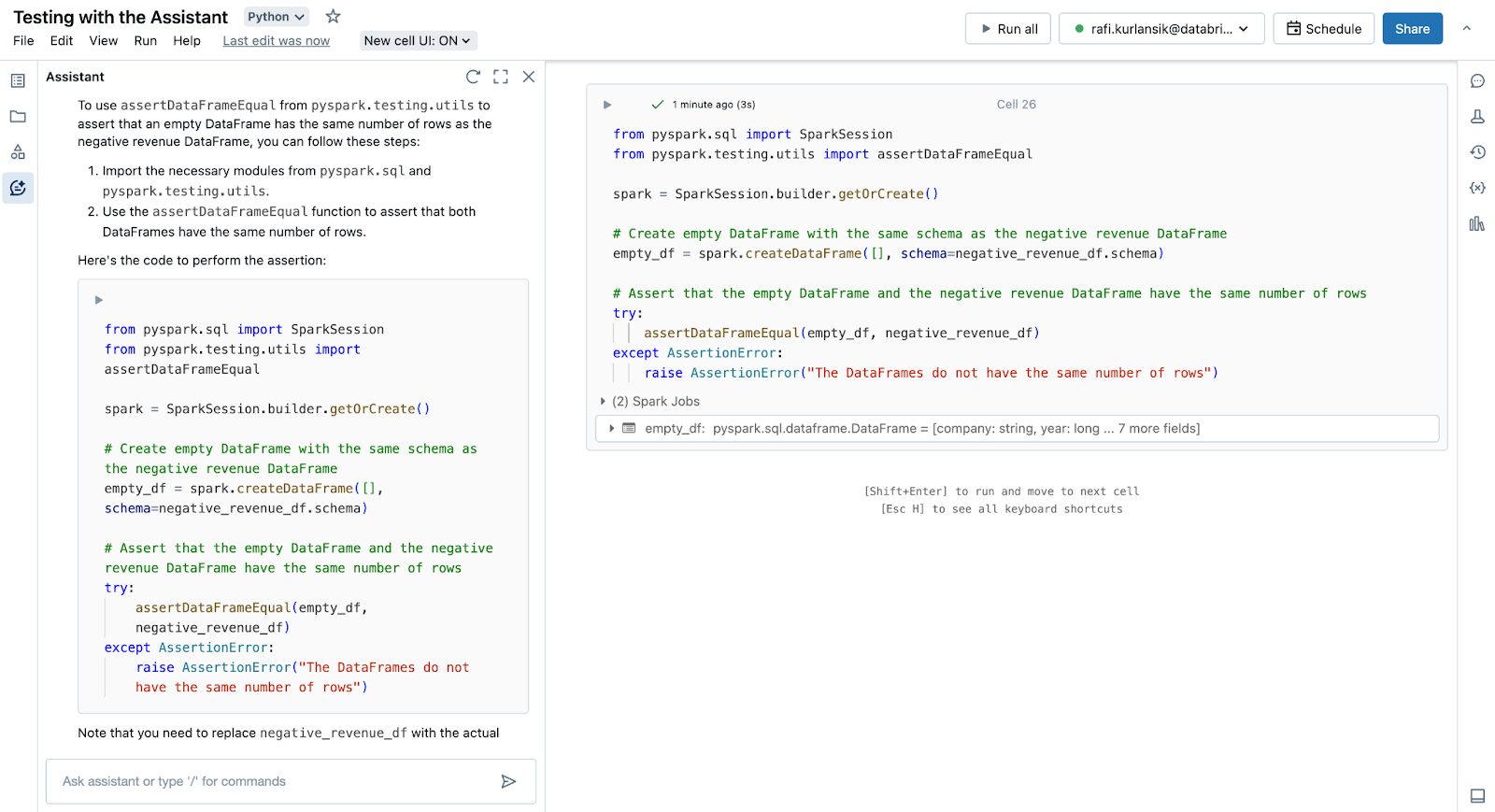
This instance highlights the truth that being particular and including element to your immediate yields higher outcomes. If we merely ask the Assistant to write down exams for us with none element, our outcomes will exhibit extra variability in high quality. Being particular and clear in what we’re in search of – a check utilizing PySpark modules that builds off the logic it wrote – typically will carry out higher than assuming the Assistant can appropriately guess at our intentions.
Getting assist
Past a common functionality to enhance and perceive code, the Assistant possesses data of your entire Databricks documentation and Data Base. This data is listed regularly and made out there as extra context for the Assistant by way of a RAG structure. This enables customers to seek for product performance and configurations with out leaving the Databricks Platform.
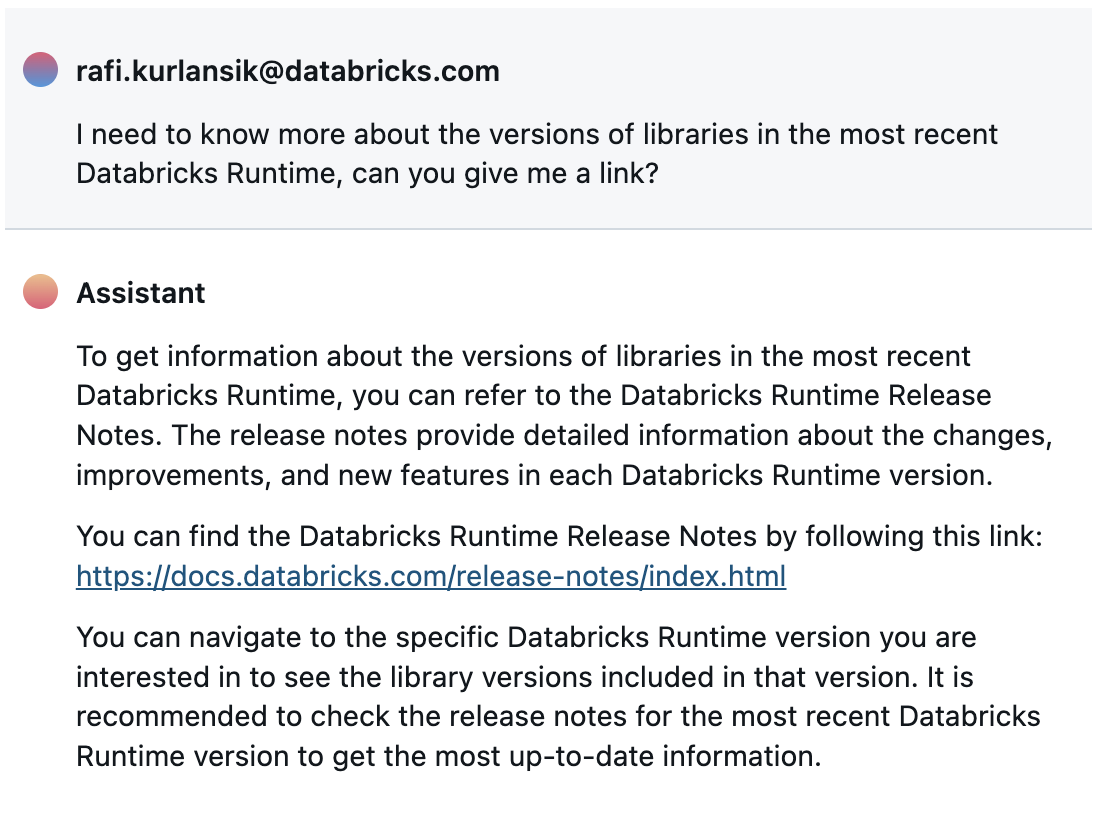
For instance, if you wish to know particulars concerning the system surroundings for the model of Databricks Runtime you might be utilizing, the Assistant can direct you to the suitable web page within the Databricks documentation.
.png?v=1714611480&description=Databricks+Assistant+Suggestions+%26+Methods+for+Information+Engineers){kind=link}
The Assistant can deal with easy, descriptive, and conversational questions, enhancing the consumer expertise in navigating Databricks’ options and resolving points. It could actually even assist information customers in submitting assist tickets! For extra particulars, learn the announcement article.
Conclusion
The barrier to entry for high quality knowledge engineering has been lowered because of the facility of generative AI with the Databricks Assistant. Whether or not you’re a newcomer in search of assistance on find out how to work with complicated knowledge buildings or a seasoned veteran who desires common expressions written for them, the Assistant will enhance your high quality of life. Its core competency of understanding, producing, and documenting code boosts productiveness for knowledge engineers of all talent ranges. To be taught extra, see the Databricks documentation on find out how to get began with the Databricks Assistant at present, and take a look at our latest weblog 5 tricks to get probably the most out of your Databricks Assistant. You may also watch this video to see Databricks Assistant in motion.