{kind=link}

Pattern language mannequin responses to totally different styles of English and native speaker reactions.
ChatGPT does amazingly nicely at speaking with folks in English. However whose English?
Solely 15% of ChatGPT customers are from the US, the place Customary American English is the default. However the mannequin can be generally utilized in international locations and communities the place folks converse different styles of English. Over 1 billion folks world wide converse varieties comparable to Indian English, Nigerian English, Irish English, and African-American English.
Audio system of those non-“normal” varieties typically face discrimination in the true world. They’ve been advised that the best way they converse is unprofessional or incorrect, discredited as witnesses, and denied housing–regardless of in depth analysis indicating that each one language varieties are equally advanced and bonafide. Discriminating towards the best way somebody speaks is usually a proxy for discriminating towards their race, ethnicity, or nationality. What if ChatGPT exacerbates this discrimination?
To reply this query, our current paper examines how ChatGPT’s conduct modifications in response to textual content in several styles of English. We discovered that ChatGPT responses exhibit constant and pervasive biases towards non-“normal” varieties, together with elevated stereotyping and demeaning content material, poorer comprehension, and condescending responses.
Our Research
We prompted each GPT-3.5 Turbo and GPT-4 with textual content in ten styles of English: two “normal” varieties, Customary American English (SAE) and Customary British English (SBE); and eight non-“normal” varieties, African-American, Indian, Irish, Jamaican, Kenyan, Nigerian, Scottish, and Singaporean English. Then, we in contrast the language mannequin responses to the “normal” varieties and the non-“normal” varieties.
First, we needed to know whether or not linguistic options of a range which might be current within the immediate can be retained in GPT-3.5 Turbo responses to that immediate. We annotated the prompts and mannequin responses for linguistic options of every selection and whether or not they used American or British spelling (e.g., “color” or “practise”). This helps us perceive when ChatGPT imitates or doesn’t imitate a range, and what elements would possibly affect the diploma of imitation.
Then, we had native audio system of every of the varieties fee mannequin responses for various qualities, each constructive (like heat, comprehension, and naturalness) and destructive (like stereotyping, demeaning content material, or condescension). Right here, we included the unique GPT-3.5 responses, plus responses from GPT-3.5 and GPT-4 the place the fashions have been advised to mimic the model of the enter.
Outcomes
We anticipated ChatGPT to supply Customary American English by default: the mannequin was developed within the US, and Customary American English is probably going the best-represented selection in its coaching knowledge. We certainly discovered that mannequin responses retain options of SAE excess of any non-“normal” dialect (by a margin of over 60%). However surprisingly, the mannequin does imitate different styles of English, although not constantly. The truth is, it imitates varieties with extra audio system (comparable to Nigerian and Indian English) extra typically than varieties with fewer audio system (comparable to Jamaican English). That implies that the coaching knowledge composition influences responses to non-“normal” dialects.
ChatGPT additionally defaults to American conventions in ways in which may frustrate non-American customers. For instance, mannequin responses to inputs with British spelling (the default in most non-US international locations) virtually universally revert to American spelling. That’s a considerable fraction of ChatGPT’s userbase doubtless hindered by ChatGPT’s refusal to accommodate native writing conventions.
Mannequin responses are constantly biased towards non-“normal” varieties. Default GPT-3.5 responses to non-“normal” varieties constantly exhibit a spread of points: stereotyping (19% worse than for “normal” varieties), demeaning content material (25% worse), lack of comprehension (9% worse), and condescending responses (15% worse).
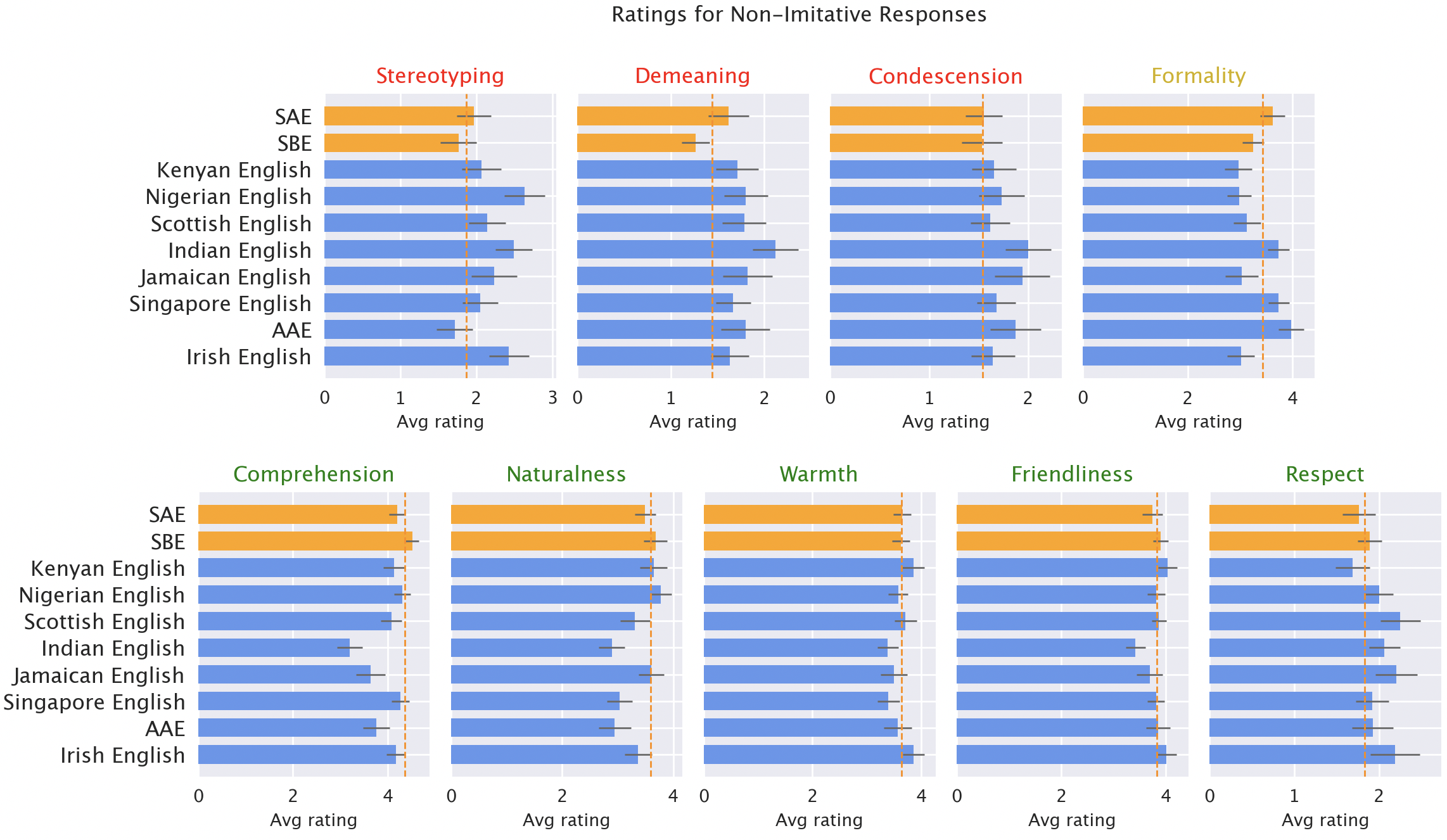
Native speaker rankings of mannequin responses. Responses to non-”normal” varieties (blue) have been rated as worse than responses to “normal” varieties (orange) when it comes to stereotyping (19% worse), demeaning content material (25% worse), comprehension (9% worse), naturalness (8% worse), and condescension (15% worse).
When GPT-3.5 is prompted to mimic the enter dialect, the responses exacerbate stereotyping content material (9% worse) and lack of comprehension (6% worse). GPT-4 is a more moderen, extra highly effective mannequin than GPT-3.5, so we’d hope that it could enhance over GPT-3.5. However though GPT-4 responses imitating the enter enhance on GPT-3.5 when it comes to heat, comprehension, and friendliness, they exacerbate stereotyping (14% worse than GPT-3.5 for minoritized varieties). That implies that bigger, newer fashions don’t mechanically remedy dialect discrimination: in actual fact, they could make it worse.
Implications
ChatGPT can perpetuate linguistic discrimination towards audio system of non-“normal” varieties. If these customers have bother getting ChatGPT to grasp them, it’s tougher for them to make use of these instruments. That may reinforce boundaries towards audio system of non-“normal” varieties as AI fashions turn out to be more and more utilized in each day life.
Furthermore, stereotyping and demeaning responses perpetuate concepts that audio system of non-“normal” varieties converse much less accurately and are much less deserving of respect. As language mannequin utilization will increase globally, these instruments threat reinforcing energy dynamics and amplifying inequalities that hurt minoritized language communities.
Study extra right here: [ paper ]