{kind=link}

|
Right now, we introduced the final availability of Amazon SageMaker Lakehouse and Amazon Redshift assist for zero-ETL integrations from functions. Amazon SageMaker Lakehouse unifies all of your knowledge throughout Amazon Easy Storage Service (Amazon S3) knowledge lakes and Amazon Redshift knowledge warehouses, serving to you construct highly effective analytics and AI/ML functions on a single copy of information. SageMaker Lakehouse provides you the pliability to entry and question your knowledge in-place with all Apache Iceberg appropriate instruments and engines. Zero-ETL is a set of absolutely managed integrations by AWS that minimizes the necessity to construct ETL knowledge pipelines for frequent ingestion and replication use instances. With zero-ETL integrations from functions resembling Salesforce, SAP, and Zendesk, you possibly can scale back time spent constructing knowledge pipelines and concentrate on working unified analytics on all of your knowledge in Amazon SageMaker Lakehouse and Amazon Redshift.
As organizations depend on an more and more various array of digital methods, knowledge fragmentation has develop into a big problem. Invaluable info is usually scattered throughout a number of repositories, together with databases, functions, and different platforms. To harness the complete potential of their knowledge, companies should allow entry and consolidation from these different sources. In response to this problem, customers construct knowledge pipelines to extract and cargo (EL) from a number of functions into centralized knowledge lakes and knowledge warehouses. Utilizing zero-ETL, you possibly can efficiently replicate precious knowledge out of your buyer assist, relationship administration, and enterprise useful resource planning (ERP) functions for analytics and AI/ML to datalakes and knowledge warehouses, saving you weeks of engineering effort wanted to design, construct, and take a look at knowledge pipelines.
Conditions
- An Amazon SageMaker Lakehouse catalog configured by means of AWS Glue Knowledge Catalog and AWS Lake Formation.
- An AWS Glue database that’s configured for Amazon S3 the place the information will probably be saved.
- A secret in AWS Secret Supervisor to make use of for the connection to the information supply. The credentials should include the username and password that you simply use to register to your software.
- An AWS Id and Entry Administration (IAM) function for the Amazon SageMaker Lakehouse or Amazon Redshift job to make use of. The function should grant entry to all assets utilized by the job, together with Amazon S3 and AWS Secrets and techniques Supervisor.
- A legitimate AWS Glue connection to the specified software.
The way it works – making a Glue connection prerequisite
I begin by making a connection utilizing the AWS Glue console. I go for a Salesforce integration as the information supply.

Subsequent, I present the placement of the Salesforce occasion for use for the connection, along with the remainder of the required info. Remember to use the .salesforce.com area as an alternative of .power.com. Customers can select between two authentication strategies, JSON Internet Token (JWT), which is obtained by means of Salesforce entry tokens, or OAuth login by means of the browser.

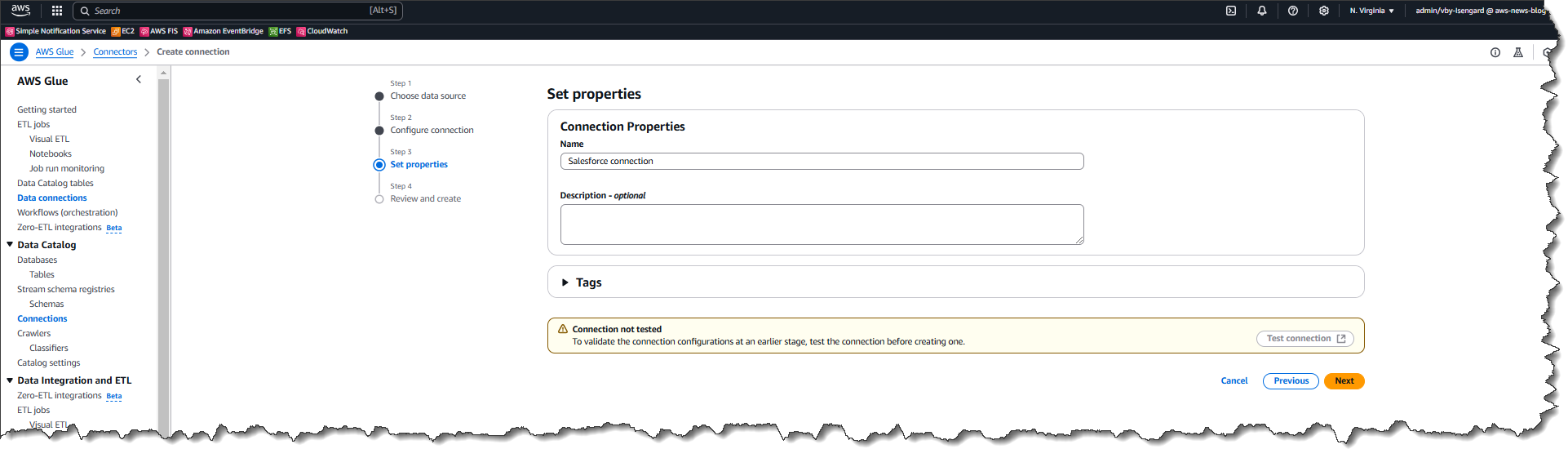
I evaluation all the data after which select Create connection.

After I signal into the Salesforce occasion by means of a popup (not proven right here), the connection is efficiently created.

The way it works – making a zero-ETL integration
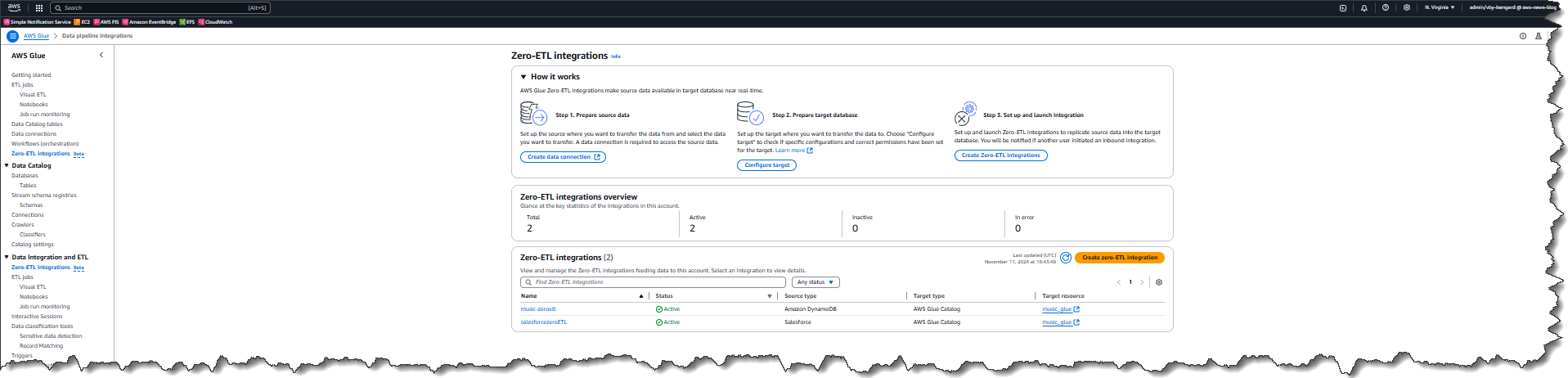
Now that I’ve a connection, I select zero-ETL integrations from the left navigation panel, then select Create zero-ETL integration.
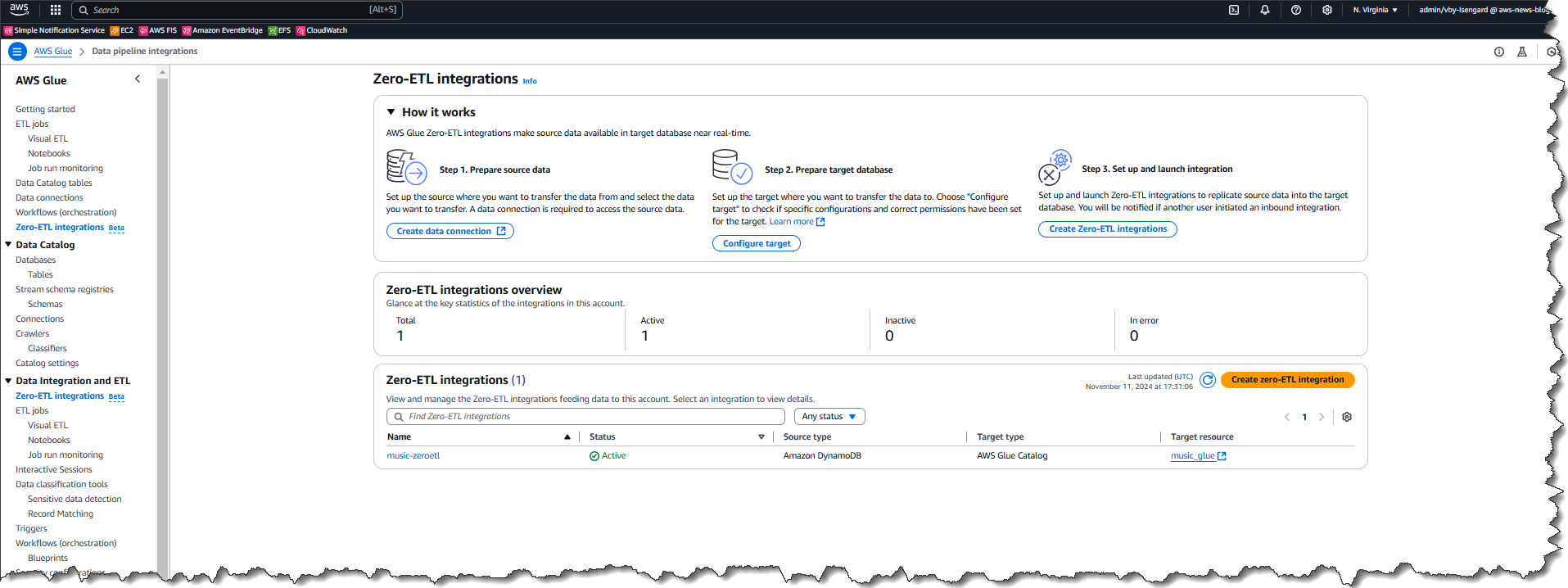
First I select the supply kind for my integration – on this case Salesforce so I can use my lately created connection.

Subsequent, I choose objects from the information supply that I need to replicate to the goal database in AWS Glue.
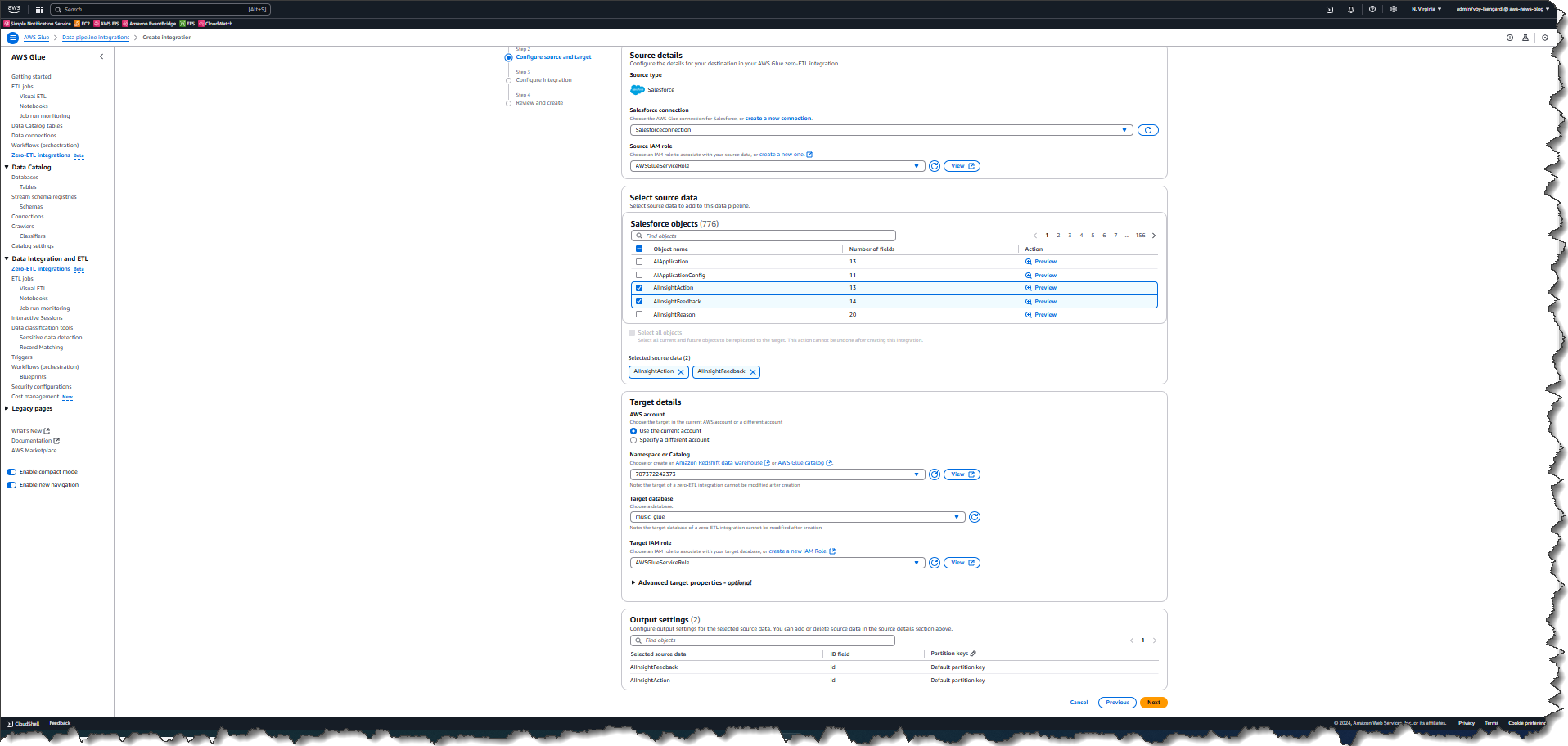
Whereas within the technique of including objects, I can shortly preview each knowledge and metadata to verify that I’m deciding on the proper object.
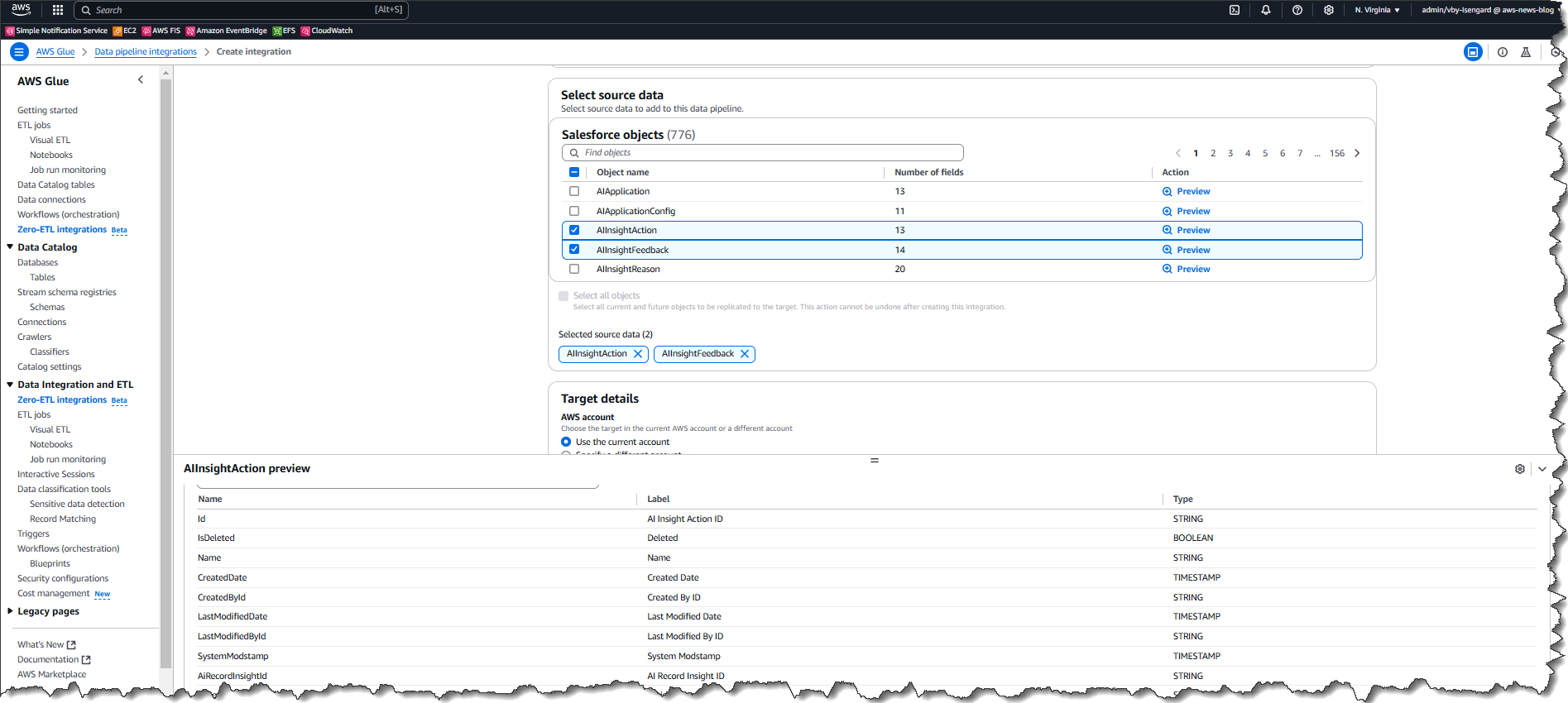
By default, zero-ETL integration will synchronize knowledge from the supply to the goal each 60 minutes. Nevertheless, you possibly can change this interval to scale back the price of replication for instances that don’t require frequent updates.
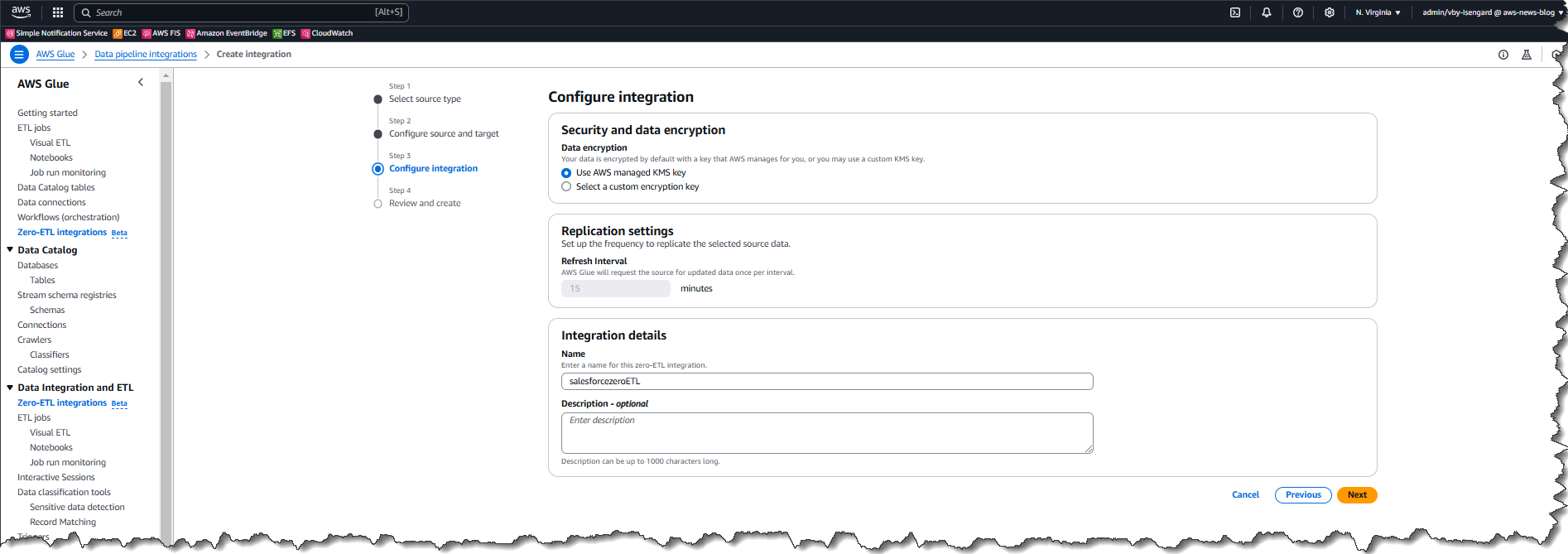
I evaluation after which select Create and launch integration.
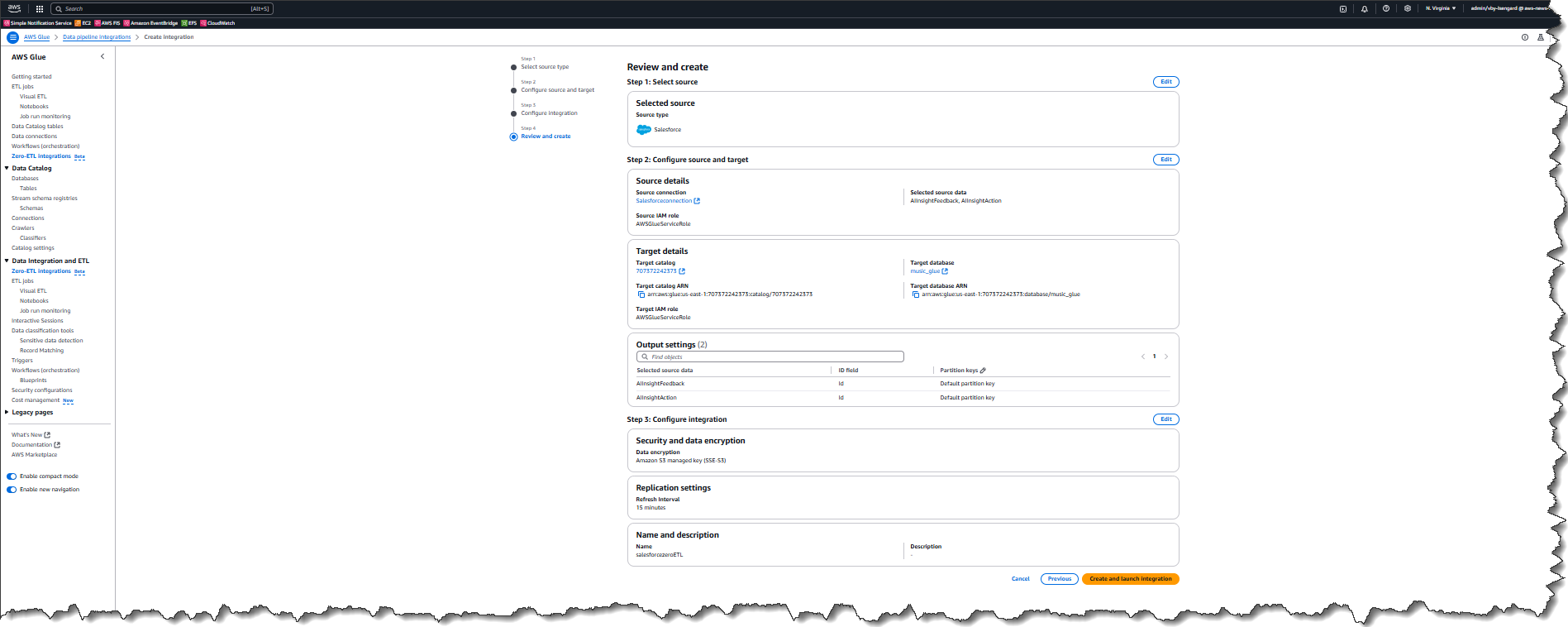
The info within the supply (Salesforce occasion) has now been replicated to the goal database salesforcezeroETL in my AWS account. This integration has two phases. Part 1: preliminary load will ingest all the information for the chosen objects and will take between 15 min to a couple hours relying on the dimensions of the information in these objects. Part 2: incremental load will detect any modifications (resembling new data, up to date data, or deleted data) and apply these to the goal.
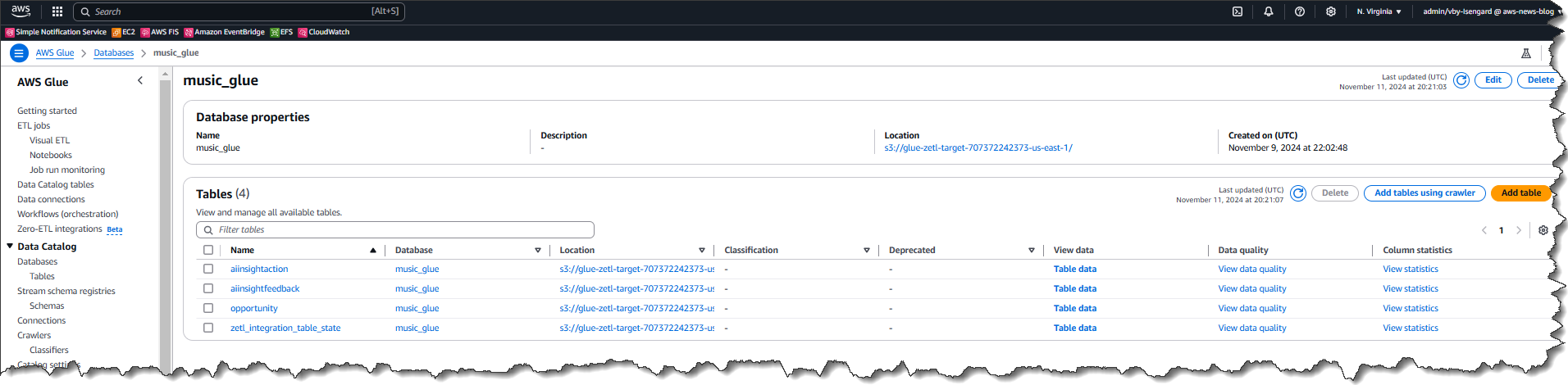
Every of the objects that I chosen earlier has been saved in its respective desk inside the database. From right here I can view the Desk knowledge for every of the objects which were replicated from the information supply.

Lastly, right here’s a view of the information in Salesforce. As new entities are created, or present entities are up to date or modified in Salesforce, the information modifications will synchronize to the goal in AWS Glue robotically.

Now out there
Amazon SageMaker Lakehouse and Amazon Redshift assist for zero-ETL integrations from functions is now out there in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Eire), and Europe (Stockholm) AWS Areas. For pricing info, go to the AWS Glue pricing web page.
To study extra, go to our AWS Glue Person Information. Ship suggestions to AWS re:Submit for AWS Glue or by means of your regular AWS Help contacts. Get began by creating a brand new zero-ETL integration in the present day.
– Veliswa