
Posted by Chris Wailes – Senior Software program Engineer

The efficiency, security, and developer productiveness supplied by Rust has led to fast adoption within the Android Platform. Since slower construct occasions are a priority when utilizing Rust, notably inside an enormous challenge like Android, we have labored to ship the quickest model of the Rust toolchain that we are able to. To do that we leverage a number of types of profiling and optimization, in addition to tuning C/C++, linker, and Rust flags. A lot of what I’m about to explain is much like the construct course of for the official releases of the Rust toolchain, however tailor-made for the particular wants of the Android codebase. I hope that this publish can be usually informative and, in case you are a maintainer of a Rust toolchain, could make your life simpler.
Android’s Compilers
Whereas Android is definitely not distinctive in its want for a performant cross-compiling toolchain this reality, mixed with the big variety of day by day Android construct invocations, signifies that we should fastidiously stability tradeoffs between the time it takes to construct a toolchain, the toolchain’s dimension, and the produced compiler’s efficiency.
Our Construct Course of
To be clear, the optimizations listed under are additionally current within the variations of rustc which might be obtained utilizing rustup. What differentiates the Android toolchain from the official releases, in addition to the provenance, are the cross-compilation targets out there and the codebase used for profiling. All efficiency numbers listed under are the time it takes to construct the Rust elements of an Android picture and might not be reflective of the speedup when compiling different codebases with our toolchain.
Codegen Items (CGU1)
When Rust compiles a crate it’ll break it into some variety of code era items. Every unbiased chunk of code is generated and optimized concurrently after which later re-combined. This method permits LLVM to course of every code era unit individually and improves compile time however can cut back the efficiency of the generated code. A few of this efficiency may be recovered by way of the usage of Hyperlink Time Optimization (LTO), however this isn’t assured to attain the identical efficiency as if the crate had been compiled in a single codegen unit.
To reveal as many alternatives for optimization as doable and guarantee reproducible builds we add the -C codegen-units=1 choice to the RUSTFLAGS atmosphere variable. This reduces the scale of the toolchain by ~5.5% whereas rising efficiency by ~1.8%.
Remember that setting this selection will decelerate the time it takes to construct the toolchain by ~2x (measured on our workstations).
GC Sections
Many tasks, together with the Rust toolchain, have features, lessons, and even complete namespaces that aren’t wanted in sure contexts. The most secure and best possibility is to depart these code objects within the ultimate product. This may enhance code dimension and should lower efficiency (as a result of caching and structure points), however it ought to by no means produce a miscompiled or mislinked binary.
It’s doable, nevertheless, to ask the linker to take away code objects that aren’t transitively referenced from the major()operate utilizing the –gc-sections linker argument. The linker can solely function on a section-basis, so, if any object in a piece is referenced, the complete part have to be retained. Because of this additionally it is widespread to cross the -ffunction-sections and -fdata-sections choices to the compiler or code era backend. This may be certain that every code object is given an unbiased part, thus permitting the linker’s rubbish assortment cross to gather objects individually.
This is among the first optimizations we applied and, on the time, it produced important dimension financial savings (on the order of 100s of MiBs). Nonetheless, most of those good points have been subsumed by these comprised of setting -C codegen-units=1 when they’re utilized in mixture and there’s now no distinction between the 2 produced toolchains in dimension or efficiency. Nonetheless, as a result of further overhead, we don’t at all times use CGU1 when constructing the toolchain. When testing for correctness the ultimate pace of the compiler is much less essential and, as such, we enable the toolchain to be constructed with the default variety of codegen items. In these conditions we nonetheless run part GC throughout linking because it yields some efficiency and dimension advantages at a really low value.
Hyperlink-Time Optimization (LTO)
A compiler can solely optimize the features and knowledge it may see. Constructing a library or executable from unbiased object information or libraries can pace up compilation however at the price of optimizations that rely upon info that’s solely out there when the ultimate binary is assembled. Hyperlink-Time Optimization offers the compiler one other alternative to investigate and modify the binary throughout linking.
For the Android Rust toolchain we carry out skinny LTO on each the C++ code in LLVM and the Rust code that makes up the Rust compiler and instruments. As a result of the IR emitted by our clang is likely to be a distinct model than the IR emitted by rustc we are able to’t carry out cross-language LTO or statically hyperlink in opposition to libLLVM. The efficiency good points from utilizing an LTO optimized shared library are larger than these from utilizing a non-LTO optimized static library nevertheless, so we’ve opted to make use of shared linking.
Utilizing CGU1, GC sections, and LTO produces a speedup of ~7.7% and dimension enchancment of ~5.4% over the baseline. This works out to a speedup of ~6% over the earlier stage within the pipeline due solely to LTO.
Profile-Guided Optimization (PGO)
Command line arguments, atmosphere variables, and the contents of information can all affect how a program executes. Some blocks of code is likely to be used incessantly whereas different branches and features could solely be used when an error happens. By profiling an utility because it executes we are able to acquire knowledge on how typically these code blocks are executed. This knowledge can then be used to information optimizations when recompiling this system.
We use instrumented binaries to gather profiles from each constructing the Rust toolchain itself and from constructing the Rust elements of Android pictures for x86_64, aarch64, and riscv64. These 4 profiles are then mixed and the toolchain is recompiled with profile-guided optimizations.
In consequence, the toolchain achieves a ~19.8% speedup and 5.3% discount in dimension over the baseline compiler. This can be a 13.2% speedup over the earlier stage within the compiler.
BOLT: Binary Optimization and Structure Device
Even with LTO enabled the linker remains to be accountable for the structure of the ultimate binary. As a result of it isn’t being guided by any profiling info the linker may unintentionally place a operate that’s incessantly known as (sizzling) subsequent to a operate that’s not often known as (chilly). When the recent operate is later known as all features on the identical reminiscence web page can be loaded. The chilly features are actually taking on area that may very well be allotted to different sizzling features, thus forcing the extra pages that do comprise these features to be loaded.
BOLT mitigates this downside through the use of a further set of layout-focused profiling info to re-organize features and knowledge. For the needs of rushing up rustc we profiled libLLVM, libstd, and librustc_driver, that are the compiler’s major dependencies. These libraries are then BOLT optimized utilizing the next choices:
--peepholes=all
--data=<path-to-profile>
--reorder-blocks=ext-tsp
–-reorder-functions=hfsort
--split-functions
--split-all-cold
--split-eh
--dyno-stats
Any extra libraries matching lib/*.so are optimized with out profiles utilizing solely –peepholes=all.
Making use of BOLT to our toolchain produces a speedup over the baseline compiler of ~24.7% at a dimension enhance of ~10.9%. This can be a speedup of ~6.1% over the PGOed compiler with out BOLT.
In case you are concerned with utilizing BOLT in your personal challenge/construct I supply these two bits of recommendation: 1) you’ll have to emit extra relocation info into your binaries utilizing the -Wl,–emit-relocs linker argument and a pair of) use the identical enter library when invoking BOLT to supply the instrumented and the optimized variations.
Conclusion
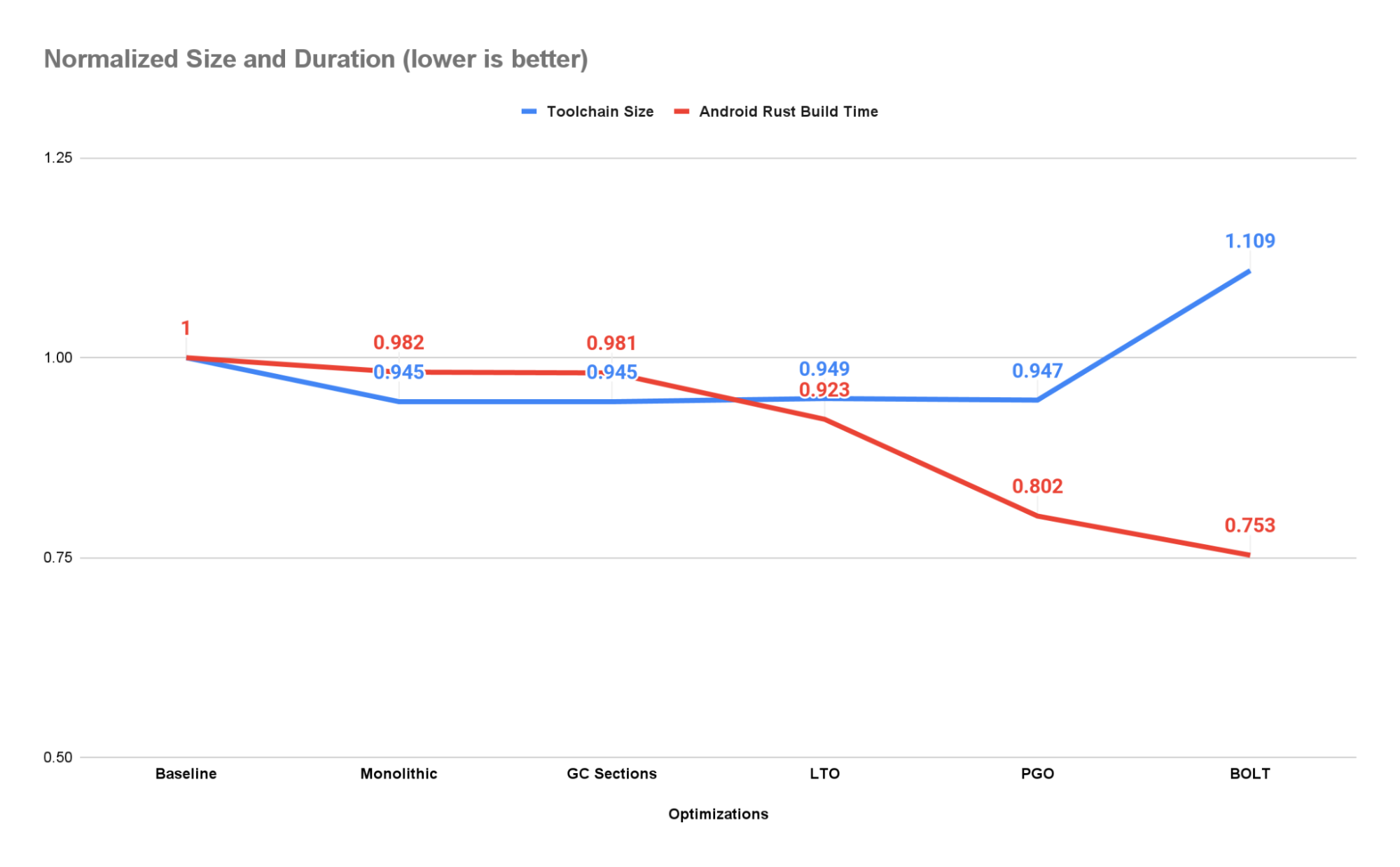
By compiling as a single code era unit, rubbish gathering our knowledge objects, performing each link-time and profile-guided optimizations, and leveraging the BOLT software we had been in a position to pace up the time it takes to compile the Rust elements of Android by 24.8%. For each 50k Android builds per day run in our CI infrastructure we save ~10K hours of serial execution.
Our business isn’t one to face nonetheless and there’ll absolutely be one other software and one other set of profiles in want of gathering within the close to future. Till then we’ll proceed making incremental enhancements looking for extra efficiency. Glad coding!