{kind=link}


Companies usually have to mixture matters as a result of it’s important for organizing, simplifying, and optimizing the processing of streaming information. It allows environment friendly evaluation, facilitates modular improvement, and enhances the general effectiveness of streaming functions. For instance, if there are separate clusters, and there are matters with the identical goal within the totally different clusters, then it’s helpful to mixture the content material into one subject.
This weblog publish walks you thru how you should utilize prefixless replication with Streams Replication Supervisor (SRM) to mixture Kafka matters from a number of sources. To be particular, we can be diving deep right into a prefixless replication situation that includes the aggregation of two matters from two separate Kafka clusters into a 3rd cluster.
This tutorial demonstrates methods to arrange the SRM service for prefixless replication, methods to create and replicate matters with Kafka and SRM command line (CLI) instruments, and methods to confirm your setup utilizing Streams Messaging Manger (SMM). Safety setup and different superior configurations are usually not mentioned.
Earlier than you start
The next tutorial assumes that you’re acquainted with SRM ideas like replications and replication flows, replication insurance policies, the essential service structure of SRM, in addition to prefixless replication. If not, you may take a look at this associated weblog publish. Alternatively, you may examine these ideas in our SRM Overview.
State of affairs overview
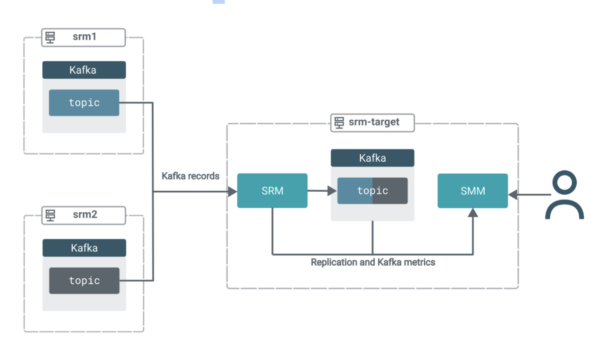
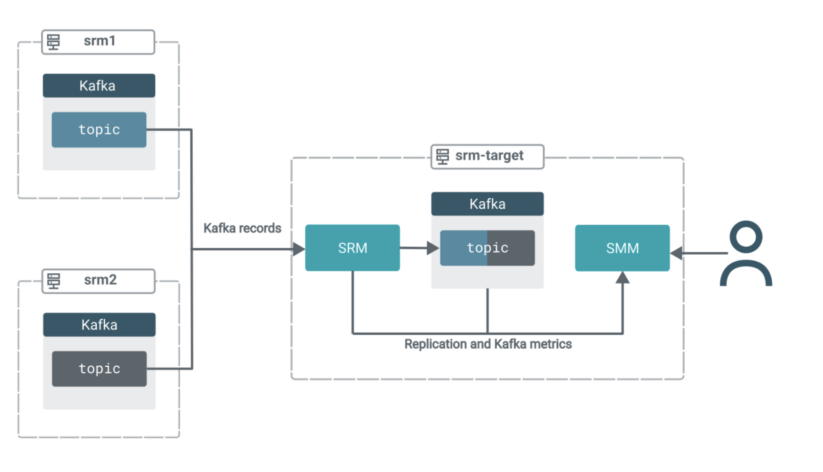
On this situation you will have three clusters. All clusters comprise Kafka. Moreover, the goal cluster (srm-target) has SRM and SMM deployed on it.
The SRM service on srm-target is used to tug Kafka information from the opposite two clusters. That’s, this replication setup can be working in pull mode, which is the Cloudera-recommended structure for SRM deployments.
In pull mode, the SRM service (particularly the SRM driver function cases) replicates information by pulling from their sources. So somewhat than having SRM on supply clusters pushing the info to focus on clusters, you employ SRM positioned on the goal cluster to tug the info into its co-located Kafka cluster.Pull mode is really helpful as it’s the deployment kind that was discovered to offer the very best quantity of resilience in opposition to numerous timeout and community instability points. You’ll find a extra in-depth rationalization of pull mode in the official docs.
The information from each supply matters can be aggregated right into a single subject on the goal cluster. All of the whereas, it is possible for you to to make use of SMM’s highly effective UI options to observe and confirm what’s occurring.
Arrange SRM
First, you want to arrange the SRM service positioned on the goal cluster.
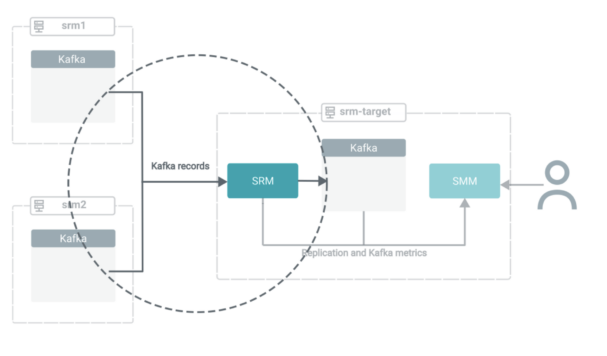
SRM must know which Kafka clusters (or Kafka companies) are targets and which of them are sources, the place they’re positioned, the way it can join and talk with them, and the way it ought to replicate the info. That is configured in Cloudera Supervisor and is a two-part course of. First, you outline Kafka credentials, then you definately configure the SRM service.
Outline Kafka credentials
You outline your supply (exterior) clusters utilizing Kafka Credentials. A Kafka Credential is an merchandise that comprises the properties required by SRM to ascertain a reference to a cluster. You may consider a Kafka credential because the definition of a single cluster. It comprises the title (alias), handle (bootstrap servers), and credentials that SRM can use to entry a particular cluster.
- In Cloudera supervisor, go to the Administration > Exterior Accounts > Kafka Credentials web page.
- Click on “Add Kafka Credentials.”
- Configure the credential.
The setup on this tutorial is minimal and unsecure, so that you solely have to configure Identify, Bootstrap Servers, and Safety Protocol traces. The safety protocol on this case is PLAINTEXT.
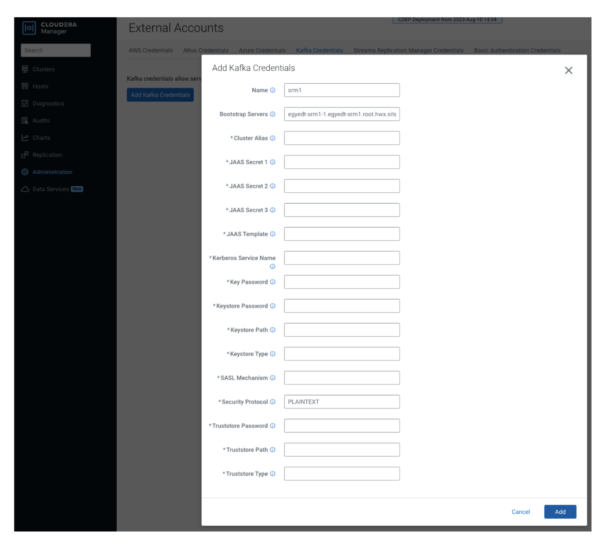
4. Click on “Add” when you’re performed, and repeat the earlier step for the opposite cluster (srm2).
Configure the SRM service
After the credentials are arrange, you’ll have to configure numerous SRM service properties. These properties specify the goal (co-located) cluster, inform SRM what replications ought to be enabled, and that replication ought to occur in prefixless mode. All of that is performed on the configuration web page of the SRM service.
1. From the Cloudera Supervisor house web page, choose the “Streams Replication Supervisor” service.
2. Go to “Configuration.”
3. Specify the co-located cluster alias with “Streams Replication Supervisor Co-located Kafka Cluster Alias.”
The co-located cluster alias is the alias (quick title) of the Kafka cluster that SRM is deployed along with. All clusters in an SRM deployment have aliases. You employ the aliases to confer with clusters when configuring properties and when operating the srm-control software. Set this to:
Discover that you just solely have to specify the alias of the co-located Kafka cluster, coming into connection info such as you did for the exterior clusters isn’t ended. It is because Cloudera Supervisor passes this info routinely to SRM.
4. Specify Exterior Kafka Accounts.
This property should comprise the names of the Kafka credentials that you just created in a earlier step. This tells SRM which Kafka credentials it ought to import to its configuration. Set this to:

5. Specify all cluster aliases with “Streams Replication Supervisor Cluster” alias.
The property comprises a comma-delimited checklist of all cluster aliases. That’s, all aliases you beforehand added to the Streams Replication Supervisor Co-located Kafka Cluster Alias and Exterior Kafka Accounts properties. Set this to:

6. Specify the motive force function goal with Streams Replication Supervisor Driver Goal Cluster.
The property comprises a comma-delimited checklist of all cluster aliases. That’s, all aliases you beforehand added to the Streams Replication Supervisor Co-located Kafka Cluster Alias and Exterior Kafka Accounts properties. Set this to:

7. Specify service function targets with Streams Replication Supervisor Service Goal Cluster.
This property specifies the cluster that the SRM service function will collect replication metrics from (i.e. monitor). In pull mode, the service roles should at all times goal their co-located cluster. Set this to:
8. Specify replications with Streams Replication Supervisor’s Replication Configs.
This property is a jack-of-all-trades and is used to set many SRM properties that aren’t immediately obtainable in Cloudera Supervisor. However most significantly, it’s used to specify your replications. Take away the default worth and add the next:

9. Choose “Allow Prefixless Replication”
This property allows prefixless replication and tells SRM to make use of the IdentityReplicationPolicy, which is the ReplicationPolicy that replicates with out prefixes.
10. Assessment your configuration, it ought to appear to be this:
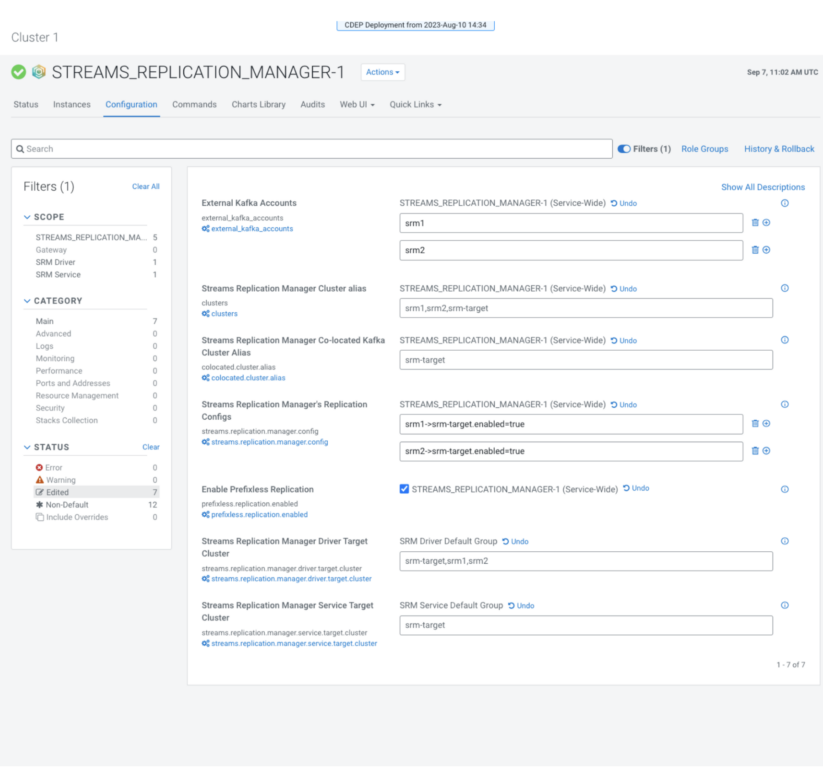
13. Click on “Save Adjustments” and restart SRM.
Create a subject, produce some information
Now that SRM setup is full, you want to create one in all your supply matters and produce some information. This may be performed utilizing the kafka-producer-perf-test CLI software.
This software creates the subject and produces the info in a single go. The software is on the market by default on all CDP clusters, and may be referred to as immediately by typing its title. No have to specify full paths.
- Utilizing SSH, log in to one in all your supply cluster hosts.
- Create a subject and produce some information.
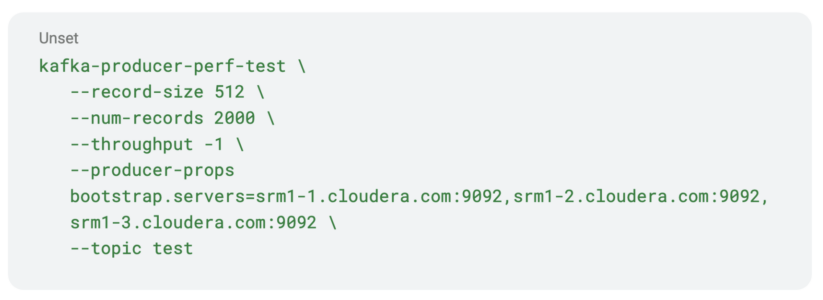
Discover that the software will produce 2000 information. This can be vital in a while once we confirm replication on the SMM UI.
Replicate the subject
So, you will have SRM arrange, and your subject is prepared. Let’s replicate.
Though your replications are arrange, SRM and the supply clusters are linked, information isn’t flowing, the replication is inactive. To activate replication, you want to use the srm-control CLI software to specify what matters ought to be replicated.
Utilizing the software you may manipulate the replication to permit and deny lists (or subject filters), which management what matters are replicated. By default, no subject is replicated, however you may change this with a couple of easy instructions.
- Utilizing SSH, log in to the goal cluster (srm-target).
- Run the next instructions to start out replication.

Discover that despite the fact that the subject on srm2 doesn’t exist but, we added the subject to the replication permit checklist as effectively. The subject can be created later. On this case, we’re activating its replication forward of time.
Insights with SMM
Now that replication is activated, the deployment is within the following state:
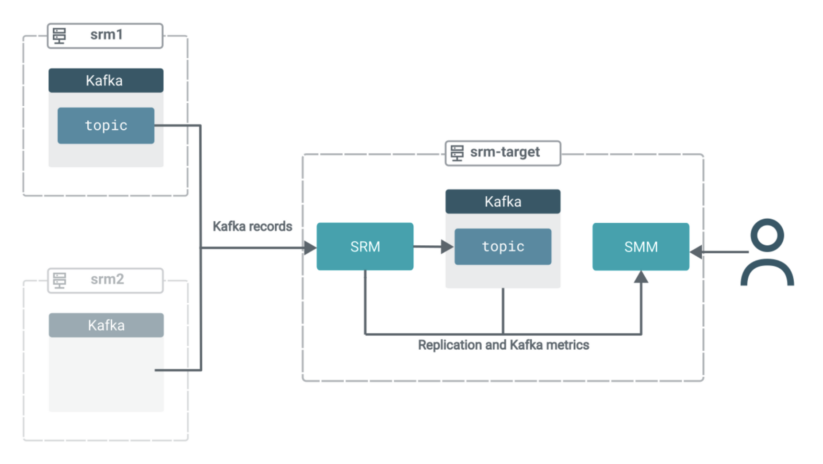
Within the subsequent few steps, we are going to shift the main target to SMM to display how one can leverage its UI to achieve insights into what is definitely occurring in your goal cluster.

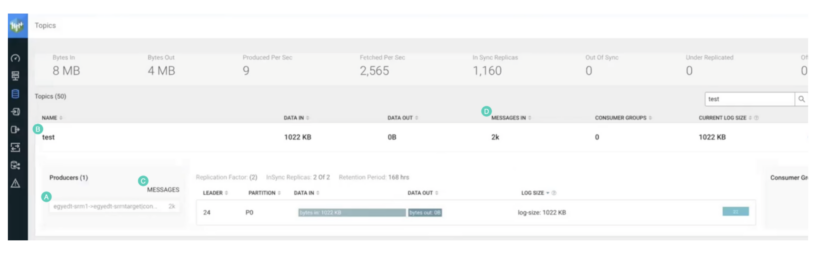
Discover the next:
- The title of the replication is included within the title of the producer that created the subject. The -> notation means replication. Due to this fact, the subject was created with replication.
- The subject title is similar as on the supply cluster. Due to this fact, it was replicated with prefixless replication. It doesn’t have the supply cluster alias as a prefix.
- The producer wrote 2,000 information. This is similar quantity of information that you just produced within the supply subject with kafka-producer-perf-test.
- “MESSAGES IN” exhibits 2,000 information. Once more, the identical quantity that was initially produced.
On to aggregation
After efficiently replicating information in a prefixless vogue, its time transfer ahead and mixture the info from the opposite supply cluster. First you’ll have to arrange the take a look at subject within the second supply cluster (srm2), because it doesn’t exist but. This subject should have the very same title and configurations because the one on the primary supply cluster (srm1).
To do that, you want to run kafka-producer-perf-test once more, however this time on a number of the srm2 cluster. Moreover, for bootstrap you’ll have to specify srm2 hosts.

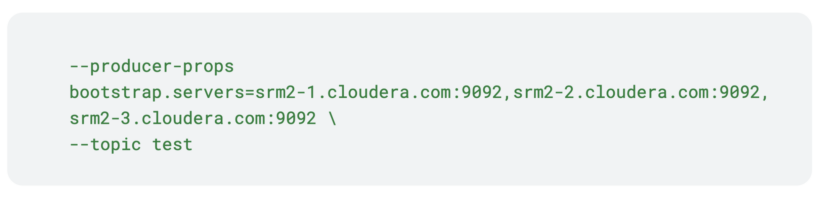
Discover how solely the bootstraps are totally different from the primary command. That is essential, the matters on the 2 clusters should be similar in title and configuration. In any other case, the subject on the goal cluster will continually swap between two configuration states. Moreover, if the names don’t match, aggregation is not going to occur.
After the producer is completed with creating the subject and producing the 2000 information, the subject is instantly replicated. It is because we preactivated replication of the take a look at subject in a earlier step. Moreover, the subject information are routinely aggregated into the take a look at subject on srm-target.
You may confirm that aggregation has occurred by taking a look on the subject within the SMM UI.
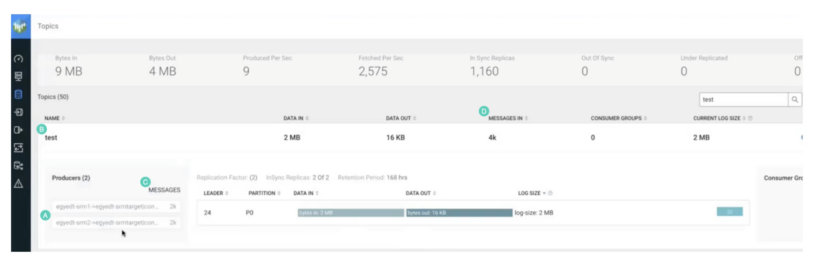
The next signifies that aggregation has occurred:
- There are actually two producers as a substitute of 1. Each comprise the title of the replication. Due to this fact, the subject is getting information from two replication sources.
- The subject title remains to be the identical. Due to this fact, perfixless replication remains to be working.
- Each producers wrote 2,000 information every.
- “MESSAGES IN” exhibits 4,000 information.

 Abstract
Abstract
On this weblog publish we checked out how you should utilize SRM’s prefixless replication function to mixture Kafka matters from a number of clusters right into a single goal cluster.
Though aggregation was in focus, be aware that prefixless replication can be utilized for non-aggregation kind replication eventualities as effectively. For instance, it’s the good software emigrate that previous Kafka deployment operating on CDH, HDP, or HDF to CDP.
If you wish to be taught extra about SRM and Kafka in CDP Personal Cloud Base, jump over to Cloudera’s doc portal and see Streams Messaging Ideas, Streams Messaging How Tos, and/or the Streams Messaging Migration Information.
To get arms on with SRM, obtain Cloudera Stream Processing Neighborhood version right here.
All for becoming a member of Cloudera?
At Cloudera, we’re engaged on fine-tuning huge information associated software program bundles (based mostly on Apache open-source initiatives) to offer our prospects a seamless expertise whereas they’re operating their analytics or machine studying initiatives on petabyte-scale datasets. Examine our web site for a take a look at drive!
In case you are serious about huge information, want to know extra about Cloudera, or are simply open to a dialogue with techies, go to our fancy Budapest workplace at our upcoming meetups.
Or, simply go to our careers web page, and develop into a Clouderan!