{kind=link}
The robots.txt file of the private weblog of Google’s John Mueller grew to become a spotlight of curiosity when somebody on Reddit claimed that Mueller’s weblog had been hit by the Useful Content material system and subsequently deindexed. The reality turned out to be much less dramatic than that however it was nonetheless a bit of bizarre.
website positioning Subreddit Put up
The saga of John Mueller’s robots.txt began when a Redditor posted that John Mueller’s web site was deindexed, posting that it fell afoul of Google’s algorithm. However as ironic as that will be that was by no means going to be the case as a result of all it took was a number of seconds to get a load of the web site’s robots.txt to see that one thing unusual was happening.
Right here’s the highest a part of Mueller’s robots.txt which encompasses a commented Easter egg for these taking a peek.
The primary bit that’s not seen daily is a disallow on the robots.txt. Who makes use of their robots.txt to inform Google to not crawl their robots.txt?
Now we all know.
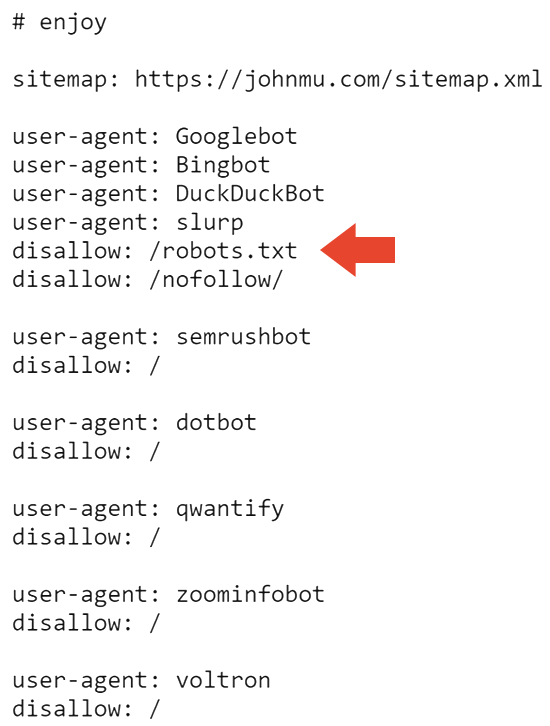
The subsequent a part of the robots.txt blocks all engines like google from crawling the web site and the robots.txt.
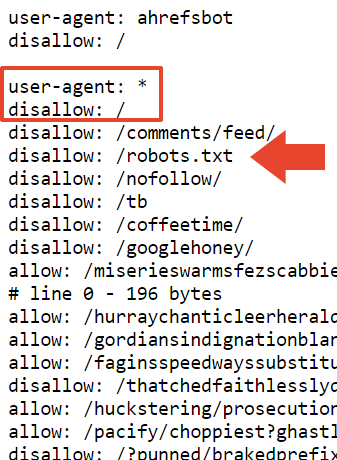
In order that most likely explains why the positioning is deindexed in Google. Nevertheless it doesn’t clarify why it’s nonetheless listed by Bing.
I requested round and Adam Humphreys, an internet developer and website positioning(LinkedIn profile), advised that it is perhaps that Bingbot hasn’t been round Mueller’s website as a result of it’s a largely inactive web site.
Adam messaged me his ideas:
“Consumer-agent: *
Disallow: /topsy/
Disallow: /crets/
Disallow: /hidden/file.htmlIn these examples the folders and that file in that folder wouldn’t be discovered.
He’s saying to disallow the robots file which Bing ignores however Google listens to.
Bing would ignore improperly applied robots as a result of many don’t know tips on how to do it. “
Adam additionally advised that perhaps Bing disregarded the robots.txt file altogether.
He defined it to me this manner:
“Sure or it chooses to disregard a directive to not learn an directions file.
Improperly applied robots instructions at Bing are possible ignored. That is essentially the most logical reply for them. It’s a instructions file.”
The robots.txt was final up to date someday between July and November of 2023 so it might be that Bingbot hasn’t seen the newest robots.txt. That is sensible as a result of Microsoft’s IndexNow net crawling system prioritizes environment friendly crawling.
Considered one of directories blocked by Mueller’s robots.txt is /nofollow/ (which is a bizarre title for a folder).
There’s principally nothing on that web page besides some website navigation and the phrase, Redirector.
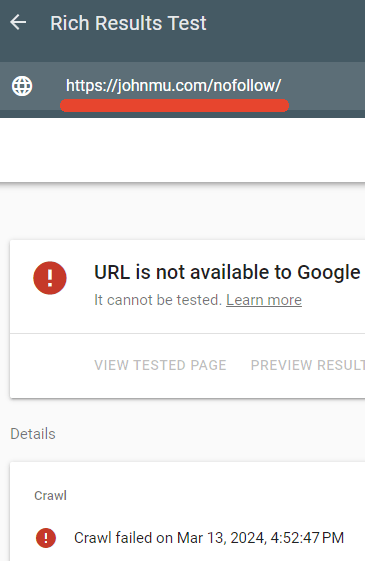
I examined to see if the robots.txt was certainly blocking that web page and it was.
Google’s Wealthy Outcomes tester did not crawl the /nofollow/ webpage.
John Mueller’s Clarification
Mueller seemed to be amused that a lot consideration was being paid to his robots.txt and he revealed a proof on LinkedIn of what was happening.
He wrote:
“However, what’s up with the file? And why is your website deindexed?
Somebody advised it is perhaps due to the hyperlinks to Google+. It’s attainable. And again to the robots.txt… it’s high-quality – I imply, it’s how I need it, and crawlers can cope with it. Or, they need to be capable of, in the event that they comply with RFC9309.”
Subsequent he mentioned that the nofollow on the robots.txt was merely to cease it from being listed as an HTML file.
He defined:
“”disallow: /robots.txt” – does this make robots spin in circles? Does this deindex your website? No.
My robots.txt file simply has numerous stuff in it, and it’s cleaner if it doesn’t get listed with its content material. This purely blocks the robots.txt file from being crawled for indexing functions.
I might additionally use the x-robots-tag HTTP header with noindex, however this manner I’ve it within the robots.txt file too.”
Mueller additionally mentioned this concerning the file measurement:
“The scale comes from assessments of the assorted robots.txt testing instruments that my workforce & I’ve labored on. The RFC says a crawler ought to parse at the very least 500 kibibytes (bonus likes to the primary one who explains what sort of snack that’s). It’s a must to cease someplace, you can make pages which can be infinitely lengthy (and I’ve, and many individuals have, some even on goal). In observe what occurs is that the system that checks the robots.txt file (the parser) will make a lower someplace.”
He additionally mentioned that he added a disallow on prime of that part within the hopes that it will get picked up as a “blanket disallow” however I’m unsure what disallow he’s speaking about. His robots.txt file has precisely 22,433 disallows in it.
He wrote:
“I added a “disallow: /” on prime of that part, so hopefully that will get picked up as a blanket disallow. It’s attainable that the parser will lower off in a clumsy place, like a line that has “enable: /cheeseisbest” and it stops proper on the “/”, which might put the parser at an deadlock (and, trivia! the enable rule will override when you’ve got each “enable: /” and “disallow: /”). This appears impossible although.”
And there it’s. John Mueller’s bizarre robots.txt.
Robots.txt viewable right here: