Introduction
Discover the facility of TensorFlow Keras preprocessing layers! This text will present you the instruments that TensorFlow Keras provides you to get your information prepared for neural networks rapidly and simply. Keras’s versatile preprocessing layers are extraordinarily useful when working with textual content, numbers, or photos. We’ll look at the significance of those layers and the way they simplify the method of making ready information, together with encoding, normalization, resizing, and augmentation.
Studying Aims
- Understanding the function and significance of TF-Keras preprocessing layers in information preparation for neural networks.
- Exploring varied preprocessing layers for textual content and picture information.
- Studying methods to apply totally different preprocessing methods equivalent to normalization, encoding, resizing, and augmentation.
- Gaining proficiency in using TF-Keras preprocessing layers to streamline the information preprocessing pipeline.
- Lastly study to preprocess numerous forms of information in a easy method for improved mannequin efficiency in neural community purposes.
What are TF-Keras Preprocessing Layers ?
The TensorFlow-Keras preprocessing layers API permits builders to assemble enter processing pipelines that seamlessly combine with Keras fashions. These pipelines are adaptable to be used each inside Keras workflows and as standalone preprocessing routines in different frameworks. They are often effortlessly mixed with Keras fashions, making certain environment friendly and unified information dealing with. Moreover, these preprocessing pipelines could be saved and exported as a part of a Keras SavedModel, facilitating straightforward deployment and sharing of fashions.
What’s the Want of TF-Keras?
Previous to the information being fed into the neural community mannequin, it performs a vital function within the information preparation pipeline. Chances are you’ll assemble end-to-end mannequin pipelines that incorporate phases for each information preparation and mannequin coaching utilizing Keras preprocessing layers. By combining your entire workflow right into a single Keras mannequin, this characteristic simplifies the event course of and promotes reproducibility.
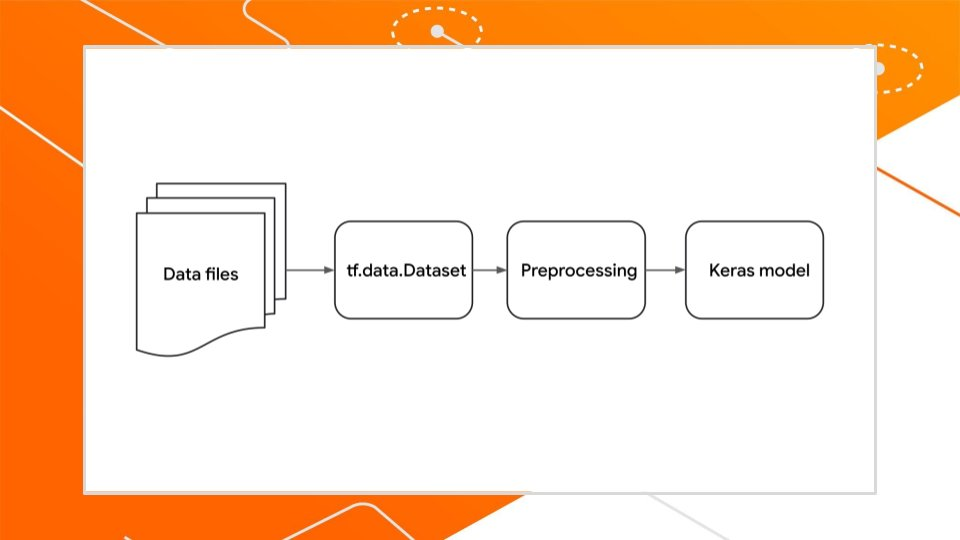
Methods to Use Preprocessing Layers
We have now two approaches to make use of these preprocessing layers. Allow us to discover them.
Strategy 1
Incorporating preprocessing layers instantly into the mannequin structure. This entails integrating preprocessing steps as a part of the mannequin’s computational graph, making certain that information transformations happen synchronously with the remainder of the mannequin execution. This strategy leverages the computational energy of gadgets, equivalent to GPUs, enabling environment friendly preprocessing alongside mannequin coaching. Notably advantageous for operations like normalization, picture preprocessing, and information augmentation, this methodology maximizes the advantages of GPU acceleration.
Strategy 2
Making use of preprocessing to the enter information pipeline, right here the preprocessing is carried out on the CPU asynchronously, with the preprocessed information buffered earlier than being fed into the mannequin. By using methods equivalent to dataset mapping and prefetching, preprocessing can happen effectively in parallel with mannequin coaching, optimizing total efficiency. This can be utilized for TextVectorization.
Dealing with Picture Information Utilizing Picture Preprocessing and Augmentation Layers
Picture preprocessing layers, equivalent to tf.keras.layers.Resizing, tf.keras.layers.Rescaling, and tf.keras.layers.CenterCrop, put together picture inputs by resizing, rescaling, and cropping them to standardized dimensions and ranges.
- tf.keras.layers.Resizing adjusts picture dimensions to a specified measurement.
- tf.keras.layers.Rescaling transforms pixel values, e.g., from [0, 255] to [0, 1].
Picture information augmentation layers, like tf.keras.layers.RandomCrop, tf.keras.layers.RandomFlip, tf.keras.layers.RandomTranslation, tf.keras.layers.RandomRotation, tf.keras.layers.RandomZoom, and tf.keras.layers.RandomContrast, introduce random transformations to enhance the coaching information, enhancing the mannequin’s robustness and generalization.
Allow us to use these layers on the emergency classification dataset from kaggle to learn the way they are often applied (be aware that right here label 1 means presence of an emergency automobile).
import pandas as pd
import numpy as np
import cv2
from skimage.io import imread, imshow
information=pd.read_csv('/kaggle/enter/emergency-vehicles-identification/Emergency_Vehicles/prepare.csv')
information.head()
x=[]
for i in information.image_names:
img=cv2.imread('/kaggle/enter/emergency-vehicles-identification/Emergency_Vehicles/prepare/'+i)
x.append(img)
x=np.array(x)
y=information['emergency_or_not']
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras import Sequential, Mannequin
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
target_size = (224, 224)
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip("horizontal"),
tf.keras.layers.RandomTranslation(height_factor=0.1, width_factor=0.1),
tf.keras.layers.RandomRotation(factor=0.2),
tf.keras.layers.RandomZoom(height_factor=0.2, width_factor=0.2),
tf.keras.layers.RandomContrast(factor=0.2)
])
# Outline the mannequin
mannequin = Sequential([
Input(shape=(target_size[0], target_size[1], 3)), # Outline enter form
Resizing(*target_size),
Rescaling(1./255),
data_augmentation,
Conv2D(32, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')
])
# Compile the mannequin
mannequin.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=['accuracy'])
# Show mannequin abstract
mannequin.abstract()
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=45,test_size=0.3,shuffle=True,stratify=y)
mannequin.match(x_train,y_train,validation_data=(x_test,y_test),epochs=10)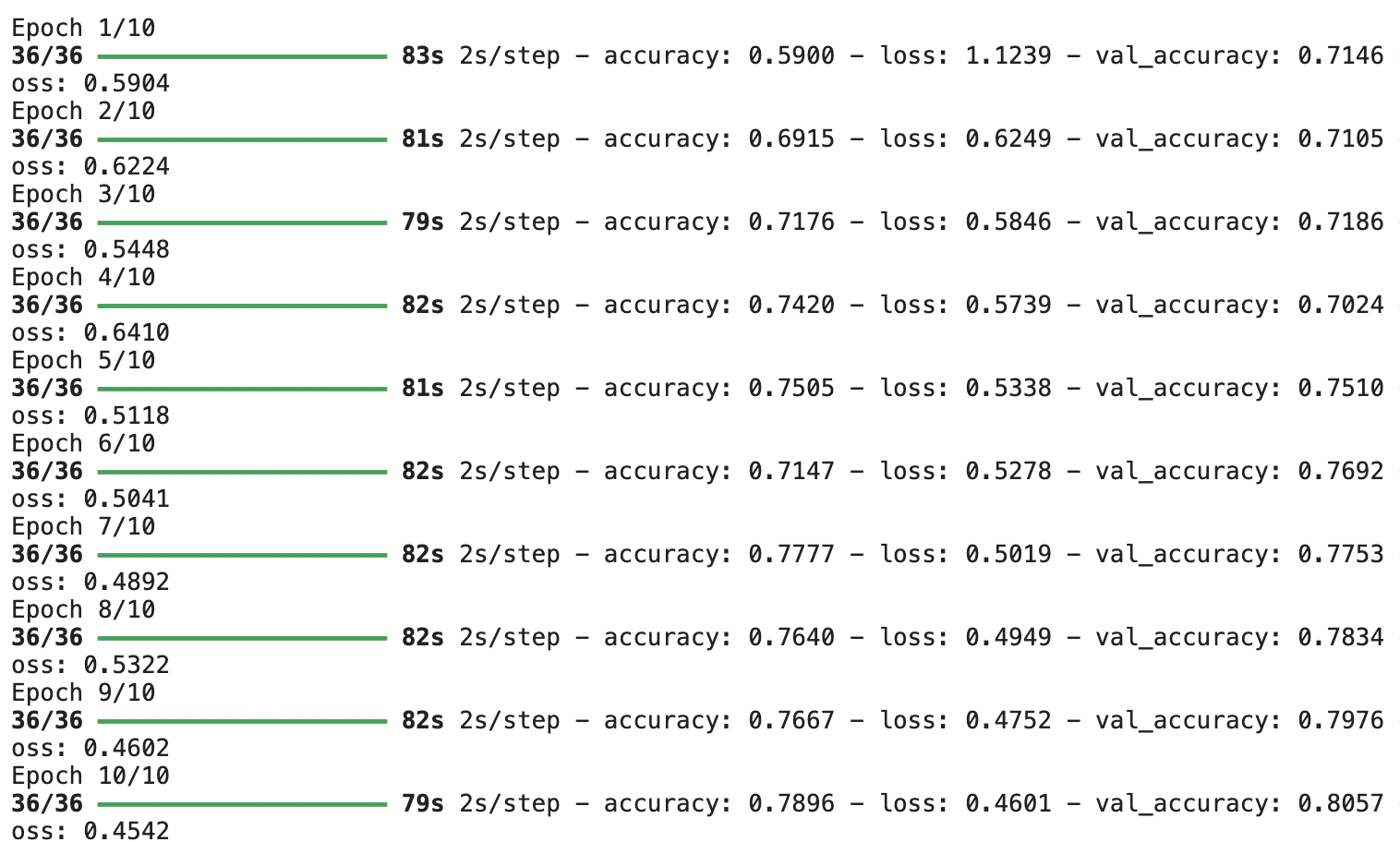
information=pd.read_csv('/kaggle/enter/emergency-vehicles-identification/Emergency_Vehicles/check.csv')
x_test=[]
for i in information.image_names:
img=cv2.imread('/kaggle/enter/emergency-vehicles-identification/Emergency_Vehicles/check/'+i)
x_test.append(img)
x_test=np.array(x_test)
y_preds=mannequin.predict(x_test)
y_predictions = [1 if x > 0.5 else 0 for x in y_preds]
import matplotlib.pyplot as plt
# Create a determine and axis outdoors the loop
fig, axes = plt.subplots(2, 2, figsize=(12, 6))
for i, ax in enumerate(axes.flatten()):
ax.imshow(x_test[i])
if y_predictions[i]==1:
ax.set_title(f"Emergency")
else:
ax.set_title(f"Non-Emergency")
ax.axis('off')
plt.tight_layout()
plt.present()
Observations
- Discover that we didn’t must learn about what preprocessing we wanted to carry out and we instantly fed the check information to the mannequin.
- On this situation, we apply preprocessing methods like resizing, rescaling, cropping, and augmentation to picture information utilizing varied layers from TensorFlow’s Keras API. These methods assist put together the pictures for mannequin coaching by standardizing their sizes and introducing variations for improved generalization. Coaching the mannequin on the preprocessed photos permits it to study and make predictions based mostly on the options extracted from the pictures.
- By incorporating these preprocessing layers instantly into the neural community mannequin, your entire preprocessing turns into a part of the mannequin structure
- Furthermore, by encapsulating the preprocessing steps inside the mannequin, the mannequin turns into extra transportable and reusable. It permits for simple deployment and inference on new information with out the necessity to manually preprocess the information externally.
Dealing with Textual content Information utilizing Preprocessing Layers
For textual content preprocessing we use tf.keras.layers.TextVectorization, this turns the textual content into an encoded illustration that may be simply fed to an Embedding layer or a Dense layer.
Let me reveal using the TextVectorizer utilizing Tweets dataset from kaggle:
import pandas as pd
import tensorflow as tf
import re
# Learn the CSV file right into a pandas DataFrame
information = pd.read_csv('prepare.csv')
# Outline a perform to take away particular characters from textual content
def remove_special_characters(textual content):
sample = r'[^a-zA-Z0-9s]'
cleaned_text = re.sub(sample, '', textual content)
return cleaned_text
# Apply the remove_special_characters perform to the 'tweet' column
information['tweet'] = information['tweet'].apply(remove_special_characters)
# Drop the 'id' column
information.drop(['id'], axis=1, inplace=True)
# Outline the TextVectorization layer
preprocessing_layer = tf.keras.layers.TextVectorization(
max_tokens=100, # Regulate the variety of tokens as wanted
output_mode="int", # Output integers representing tokens
output_sequence_length=10 # Regulate the sequence size as wanted
)
# Adapt the TextVectorization layer to the information after which match to it
preprocessing_layer.adapt(information['tweet'].values)
# Convert pandas DataFrame to TensorFlow Dataset
dataset = tf.information.Dataset.from_tensor_slices((information['tweet'].values, information['label'].values))
# Apply the preprocessing layer to the dataset
dataset = dataset.map(lambda x, y: (preprocessing_layer(x), tf.expand_dims(y, -1)))
# Prefetch the information for environment friendly processing
dataset = dataset.prefetch(tf.information.AUTOTUNE)
train_size = int(0.8 * information.form[0])
train_dataset = dataset.take(train_size)
val_dataset = dataset.skip(train_size)
# Prefetch the information for environment friendly processing
train_dataset = train_dataset.prefetch(tf.information.AUTOTUNE)
val_dataset = val_dataset.prefetch(tf.information.AUTOTUNE)
# Construct the mannequin
mannequin = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=len(preprocessing_layer.get_vocabulary()) + 1, output_dim=64, mask_zero=True),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Compile the mannequin
mannequin.compile(optimizer="adam",loss="binary_crossentropy")
historical past = mannequin.match(train_dataset, epochs=10, validation_data=val_dataset)

The TextVectorization layer exposes itself to the coaching information utilizing the adapt() methodology as a result of these are non-trainable layers, and their state have to be set earlier than the mannequin coaching. This permits the layer to research the coaching information and configure its inner state accordingly. As soon as the item is instantiated, it may be reused on the check information in a while.
“tf.information.AUTOTUNE” dynamically adjusts the information processing operations in TensorFlow to maximise CPU utilization. Making use of prefetching to the pipeline permits the system to mechanically tune the variety of parts to prefetch, optimizing efficiency throughout coaching and validation.
Comparability of TextVectorizer with one other module Tokenizer
Let’s examine TextVectorizer with one other module Tokenizer from tf.keras.preprocessing.textual content to transform textual content to numerical values:
import tensorflow as tf
# Outline the pattern textual content information
text_data = [
"The quick brown fox jumps over the lazy dog.",
"The dog barks loudly in the night.",
"A brown cat sleeps peacefully on the windowsill."
]
# Outline TextVectorization layer
vectorizer = tf.keras.layers.TextVectorization(output_mode="int", output_sequence_length=10)
# Adapt the TextVectorization layer to the textual content information
vectorizer.adapt(text_data)
# Vectorize the textual content information
vectorized_text = vectorizer(text_data)
print("Vectorized Textual content (utilizing TextVectorization):")
print(vectorized_text.numpy())
from tensorflow.keras.preprocessing.textual content import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Initialize Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text_data)
# Convert textual content to matrix utilizing texts_to_matrix
matrix = tokenizer.texts_to_matrix(text_data, mode="rely")
print("nMatrix (utilizing texts_to_matrix):")
print(matrix)

On the first look we are able to see that the size from each of them are totally different, let’s take a look at the variations intimately:
Output Content material
- TextVectorization: Outputs a tensor with integer values, representing the indices of tokens within the vocabulary. The output_sequence_length parameter determines the form of the output tensor, padding or truncating the sequences to a hard and fast size.
- texts_to_matrix: Outputs a matrix the place every row corresponds to a textual content pattern, and every column corresponds to a novel phrase within the vocabulary. The values within the matrix characterize phrase counts, decided by the mode parameter.
Information Construction
- TextVectorization: Outputs a tensor.
- texts_to_matrix: Outputs a numpy array.
Dimensionality
- TextVectorization: The output_sequence_length parameter determines the form of the output tensor, leading to fixed-length sequences.
- texts_to_matrix: The variety of textual content samples and the scale of the vocabulary decide the form of the output matrix.
Flexibility
- TextVectorization: Gives extra flexibility when it comes to preprocessing choices, equivalent to tokenization, lowercasing, and padding/truncating sequences.
- texts_to_matrix: Gives choices for various matrix modes (‘binary’, ‘rely’, ‘tfidf’, ‘freq’) however doesn’t provide as a lot management over preprocessing steps.
Different Preprocessing Layers in TensorFlow Keras
Numerical options preprocessing
- tf.keras.layers.Normalization: It performs feature-wise normalization of the enter.
- tf.keras.layers.Discretization: It turns steady numerical options into categorical options (Integer).
These layers can simply be applied within the following approach:
import numpy as np
import tensorflow as tf
import keras
from keras import layers
information = np.array(
[
[0.1, 0.4, 0.8],
[0.8, 0.9, 1.0],
[1.5, 1.6, 1.7],
]
)
layer = layers.Normalization()
layer.adapt(information)
normalized_data = layer(information)
print("Normalized options: ", normalized_data)
print()
print("Options imply: %.2f" % (normalized_data.numpy().imply()))
print("Options std: %.2f" % (normalized_data.numpy().std()))

information = np.array([[-1.5, 1.0, 3.4, .5], [0.0, 3.0, 1.3, 0.0]])
layer = tf.keras.layers.Discretization(num_bins=4, epsilon=0.01)
layer.adapt(information)
print(layer(information))

The Normalization layers make every characteristic to have a imply near 0 and a normal deviation near 1, which is a attribute of standardized information.
It’s value noting that we are able to set the imply and normal deviation of the resultant options to our preferences by using the normalization layer’s hyperparameters.

Coming to the outputs of the latter code, the discretization layer creates equi-width bins. Within the first row, the primary characteristic -1.5 belongs to bin 0, the second characteristic 1.0 belongs to bin 2, the third characteristic 3.4 belongs to bin 3, and the fourth characteristic 0.5 belongs to bin 2.
Categorical Options Preprocessing
- tf.keras.layers.CategoryEncoding transforms integer categorical options into dense representations like one-hot, multi-hot, or rely.
- tf.keras.layers.Hashing executes categorical characteristic hashing, generally known as the “hashing trick”.
- tf.keras.layers.IntegerLookup converts integer categorical values into an encoded illustration appropriate with Embedding or Dense layers.
- tf.keras.layers.StringLookup converts string categorical values into an encoded illustration appropriate with Embedding or Dense layers.
Let’s discover methods to preprocess categorical options:
import tensorflow as tf
# Pattern information
information = [3,2,0,1]
# Class encoding
encoder_layer = tf.keras.layers.CategoryEncoding(num_tokens=4, output_mode="one_hot")
class=encoder_layer(information)
print("Class Encoding:")
print(class)

hashing_layer = tf.keras.layers.Hashing(num_bins=3)
information = [['A'], ['B'], ['C'], ['D'], ['E']]
hash=hashing_layer(information)
print(hash)

{kind=link}
Within the Class Encoding
The weather within the matrix are float values representing the one-hot encoding of every class.
For instance, the primary row [0. 0. 0. 1.] corresponds to the class 3 (as indexing begins from 0), indicating that the unique information merchandise was 3.
In Hashing
Every ingredient represents the hash worth assigned to the corresponding merchandise.
For instance, the primary row [1] signifies that the hashing algorithm assigned the primary merchandise to the worth 1.
Equally, the second row [0] signifies that the hashing algorithm assigned the second merchandise to the worth 0.
Functions of TF_Keras
There are a number of purposes of TF-Keras. Allow us to look into few of a very powerful ones:
Portability and Diminished Coaching/Serving Skew
By integrating preprocessing layers into the mannequin itself, it turns into simpler to export an inference-only end-to-end mannequin. This ensures that every one the required preprocessing steps are encapsulated inside the mannequin, making it transportable.
Customers of the mannequin don’t want to fret concerning the particulars of how every characteristic is preprocessed, encoded, or normalized. Whether or not it’s uncooked photos or structured information, the inference mannequin can deal with them seamlessly with out requiring customers to grasp the preprocessing pipelines.
Ease of Exporting to Different Runtimes
Exporting fashions to different runtimes, equivalent to TensorFlow.js, turns into extra easy when the mannequin contains preprocessing layers inside it. There’s no must reimplement the preprocessing pipeline within the goal language or framework.
Inference Mannequin that Processes Uncooked Information
With preprocessing layers built-in into the mannequin, the inference mannequin can instantly course of uncooked information. That is advantageous because it simplifies the deployment course of and eliminates the necessity for customers to preprocess information individually earlier than feeding it into the mannequin.
Multi-Employee Coaching with Preprocessing Layers
Preprocessing layers are appropriate with the tf.distribute API, enabling coaching throughout a number of machines or employees. For optimum efficiency, place these layers inside a tf.distribute.Technique.scope().
Textual content Preprocessing
The textual content could be encoded utilizing totally different schemes equivalent to multi-hot encoding or TF-IDF weighting. These preprocessing steps could be included inside the mannequin, simplifying the deployment course of.
Issues to think about:
- Whereas working with very massive vocabularies in lookup layers (e.g., TextVectorization, StringLookup) might influence efficiency. For such instances, it’s really helpful to pre-compute the vocabulary and retailer it in a file relatively than utilizing adapt().
- The TensorFlow workforce is slated to repair recognized points with utilizing lookup layers on TPUs or with ParameterServerStrategy in TensorFlow 2.7.
Conclusion
The TensorFlow Keras preprocessing layers API empowers builders to create Keras-native enter processing pipelines. It facilitates constructing end-to-end fashions that deal with uncooked information, carry out characteristic normalization, and apply categorical characteristic encoding or hashing. You may combine these preprocessing layers, adaptable to coaching information, instantly into Keras fashions or make use of them independently. Whether or not processed inside the mannequin or as a part of the dataset, these functionalities improve mannequin portability and mitigate coaching/serving discrepancies, providing flexibility and effectivity in mannequin deployment throughout numerous environments.
Ceaselessly Requested Questions
A. To make the most of TensorFlow preprocessing layers, you possibly can make use of the tensorflow.keras.layers module. First, import the required layers on your preprocessing duties equivalent to Normalization, TextVectorization ..and so forth.
A. Sure, you possibly can outline customized layers in Keras by subclassing tf.keras.layers.Layer and implementing the __init__ and name strategies to specify the layer’s configuration and computation, respectively.
A. TensorFlow Keras preprocessing layers assist a variety of preprocessing duties, together with:
-Normalization and standardization of numerical options.
-Encoding categorical options utilizing one-hot encoding, integer encoding, or embeddings.
-Textual content vectorization for pure language processing duties.
-Dealing with lacking values and have scaling.
-Function discretization and bucketization.
-Picture preprocessing equivalent to resizing, cropping, and information augmentation.