We not too long ago made important enhancements to the underlying algorithms supporting AI-generated feedback in Unity Catalog and we’re excited to share our outcomes. By way of DatabricksIQ, the Information Intelligence Engine for Databricks, AI-generated feedback are already producing the overwhelming majority of latest documentation for patrons’ Unity Catalog tables, and up to date enhancements assist to make this wildly standard function extra highly effective.
On this weblog we’ll focus on how we’re utilizing an up to date open-source LLM for synthesizing coaching knowledge, heuristic filters for cleansing coaching knowledge, an up to date base mannequin for fine-tuning, and an expanded analysis set utilized in an automatic benchmark. With minimal effort, these modifications have resulted in a twofold improve in desire charges over the beforehand deployed mannequin in offline benchmarks. Extra broadly, this work has made DatabricksIQ much more highly effective at serving the gamut of our prospects’ Utilized AI use circumstances.
Why you want AI-generated feedback
Including feedback and documentation to your enterprise knowledge is a thankless process however when your group’s tables are sparsely documented, each people and AI brokers battle to search out the proper knowledge for precisely answering your knowledge questions. AI-generated feedback handle this by automating the guide means of including descriptions to tables and columns by the magic of generative AI.
Final fall we wrote how two engineers spent one month coaching a bespoke LLM to sort out the issue of routinely producing documentation on your tables in Unity Catalog. The mannequin’s process, in a nutshell, is to generate desk descriptions and column feedback when introduced with a desk schema. This earlier work concerned fine-tuning a modestly sized MPT-7B mannequin on about 3600 synthesized examples after which benchmarking this mannequin by a double-blind analysis utilizing 62 pattern tables. With this context, let’s stroll by what we modified to make our mannequin even higher.
Enhancing the coaching knowledge
The identical week that Mistral AI made their mixture-of-experts mannequin publicly out there, we began producing artificial datasets with Mixtral 8x7B Instruct. Just like the earlier strategy, we began with use circumstances outlined in NAICS codes and a Databricks inside taxonomy. Utilizing Mixtral we then generated a number of CREATE TABLE statements for every use case, after which used Mixtral once more to generate desk descriptions and column feedback for every generated schema. As a result of Mixtral 8x7B has a decrease inference latency than different LLMs of its dimension, we might generate 9K artificial coaching samples in slightly below 2 hours.
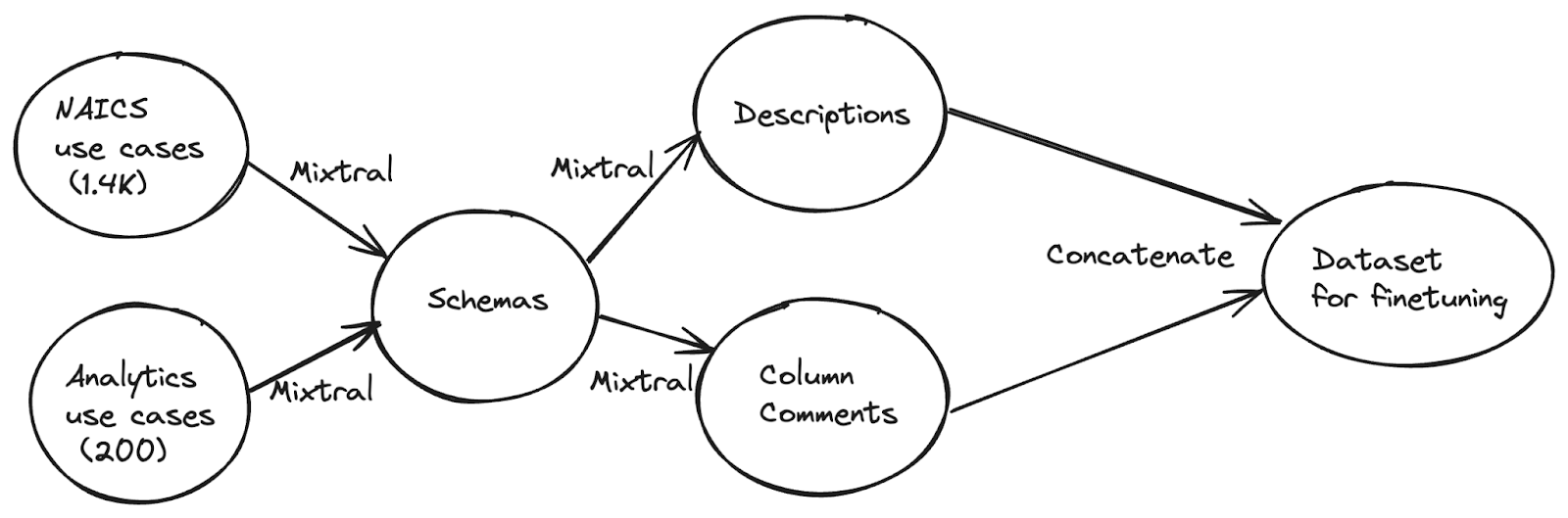
Throughout this train, we discovered that for those who simply craft a immediate and begin producing plenty of artificial knowledge with an LLM, among the knowledge generated may not have fairly the proper format, both stylistically or syntactically. For instance, in order for you all desk descriptions to have between 2 and 4 sentences, simply stating that within the immediate will not be sufficient on your LLM to persistently obey. That is why, throughout technology, we introduced few-shot examples in a chat format to show Mixtral our desired output format (e.g. a sound CREATE TABLE assertion once we are producing schemas). We used this system to reap the benefits of Mixtral’s instruction-tuning to create a dataset with coherent examples.
Higher filtering
Even with few-shot examples and instruction tuning, the output is commonly lower than fascinating. For instance, among the schemas generated could not have sufficient columns to be sensible or instructional. Descriptions usually simply regurgitate the names of the columns relatively than summarize them, or they could include hyperbolic language we don’t need our fine-tuned mannequin to repeat. Beneath are some examples of our filters in motion:
The next generated schema was rejected because it doesn’t observe the `CREATE TABLE …` syntax.
CREATE TYPE agritech.climate.windDirection AS ENUM ('N', 'NNE', 'NE', 'ENE', 'E', 'ESE', 'SE', 'SSE', 'S', 'SSW', 'SW', 'WSW', 'W', 'WNW', 'NW', 'NNW')
The next artificial description for a desk about gear upkeep was rejected as a result of it simply lists out the tables columns. This can be a filter on the stylistic content material of the coaching knowledge, since we wouldn’t need a mannequin that regurgitates no matter schema we give it.
The ‘EquipmentRepair’ desk tracks restore data for all gear, detailing the shopper who requested the restore, the gear mannequin in query, the date of the restore, the technician who carried out it, the standing of the repaired gear, the wait time for the restore, the price of the restore, and any buyer evaluations associated to the restore expertise. This knowledge can be utilized to establish tendencies in restore prices, gear reliability, and buyer satisfaction. It is usually helpful for managing gear upkeep schedules and discovering out probably the most generally reported points with particular gear fashions.
To extend the general high quality of our artificial dataset, we outlined a number of heuristic filters to take away any schemas, descriptions, or column feedback that had been undesirable for coaching. After this course of, we had been left with about 7K of our unique 9K samples.
Wonderful-tuning
With this filtered artificial dataset of 7K samples for each desk description and column feedback, we fine-tuned a Mistral-7B v1 Instruct mannequin, which has roughly the identical dimension and latency as our earlier manufacturing mannequin (MPT-7B). Ultimately, we opted for Mistral-7B over MPT-7B because it was the highest-ranking 7B parameter mannequin on the time within the chatbot area. We ran parameter-efficient fine-tuning for 2 epochs on our coaching dataset, which took about 45 minutes to finish, and our mannequin was prepared for analysis.
Improved mannequin analysis
Our earlier strategy bootstrapped an analysis set of 62 schemas which was a combination consisting of artificial (beforehand unseen) tables and actual tables we curated from our personal Databricks workspace. Utilizing artificial samples for analysis is nice when knowledge is tough to search out, nevertheless it usually lacks real-world traits. To deal with this we sampled 500 of probably the most used tables in our Databricks workspace to type an analysis set that’s far more consultant of precise utilization.
To validate this new mannequin earlier than launch, we generated desk descriptions with each the earlier mannequin and our new mannequin over all 500 analysis tables. We used our double-blind analysis framework to measure which generated descriptions are most popular by our evaluator. As a result of it will be costly to have people annotate 500 such samples throughout our improvement cycle, we up to date our framework in order that it will leverage one other LLM because the evaluator, with a immediate crafted to obviously outline the analysis process. There are just a few notable options of our automated analysis to focus on:
- Reasonably than requiring the mannequin to select the most effective amongst two outputs, we allowed ties. Once we ourselves carried out the analysis process we typically discovered that the 2 outputs had been too near name, so it was essential to offer the mannequin this flexibility as nicely.
- The mannequin was required to supply an evidence behind its reply. This method has been present in analysis and trade to result in extra correct outcomes. We logged all these explanations, giving us the chance to verify its work and make sure the mannequin is making a selection primarily based on appropriate reasoning.
- We generated a number of scores for every pattern and selected the ultimate ranking utilizing a majority vote.
The mannequin’s explanations gave us insights into the place the immediate defining the duty for analysis may very well be improved, resulting in scores that had been far more per human judgment. As soon as we completed tweaking the knobs in our strategy, we requested two human evaluators to evaluate 100 random analysis samples. Though our human evaluators are much less more likely to have an equal desire than the LLM evaluator, each evaluators present a transparent desire for the brand new mannequin. In truth, human evaluators most popular the brand new mannequin output roughly twice as usually as they most popular the earlier manufacturing fashions output.
|
Evaluator |
Choice for the earlier mannequin |
Equal desire |
Choice for brand spanking new mannequin |
|---|---|---|---|
|
LLM |
6.0% |
73.8% |
20.2% |
|
People |
17.0% |
47.0% |
36.0% |
Utilizing simply LLM analysis for efficiency causes, we additionally repeated the identical analysis course of for the duty of producing column feedback. Our LLM evaluator most popular the brand new mannequin almost thrice as usually because the earlier mannequin.
|
Evaluator |
Choice for the earlier mannequin |
Equal desire |
Choice for brand spanking new mannequin |
|---|---|---|---|
|
LLM |
11.8% |
59.0% |
29.2% |
Deploying the brand new LLM
After analyzing offline evaluations, it was time to deploy our new mannequin. Following the identical steps as earlier than, we registered the mannequin in Unity Catalog (UC), leveraged Delta Sharing to show it in all manufacturing areas, after which served it through Databricks’ optimized LLM serving.
Key takeaways
By way of the methods mentioned on this weblog, we considerably improved DatabricksIQ’s skill to routinely generate desk and column feedback with AI. To do that we leveraged an open supply LLM to supply a big coaching dataset. Then, utilizing human instinct and expertise we cleaned up the dataset utilizing heuristic filters. Lastly, we fine-tuned one other smaller LLM to supersede the present mannequin. By enhancing our analysis set by together with plenty of sensible samples, we had been extra assured that our positive factors in an offline setting would translate into higher-quality outcomes for patrons.
We hope these learnings are useful to anybody who needs to leverage open supply LLMs to sort out a concrete process at hand. Though every step of the method requires care and evaluation, it has by no means been simpler to leverage LLMs with instruments just like the Databricks Foundational Mannequin API and optimized LLM serving.
Prepared to make use of AI-generated feedback?
AI-generated feedback could be accessed by opening Catalog Explorer and deciding on a desk managed by Unity Catalog. From there you will note the choice to generate and settle for AI-comments.
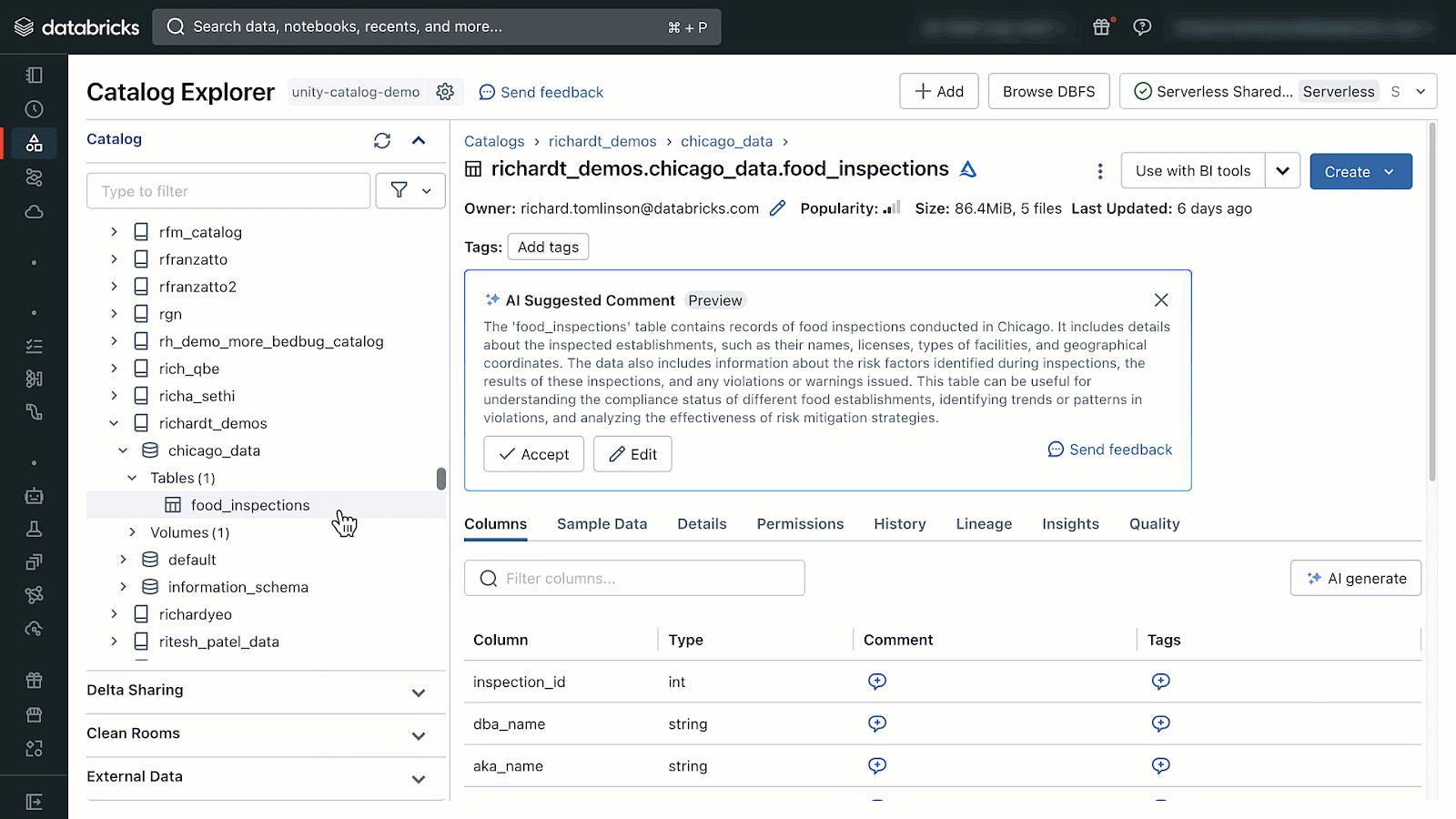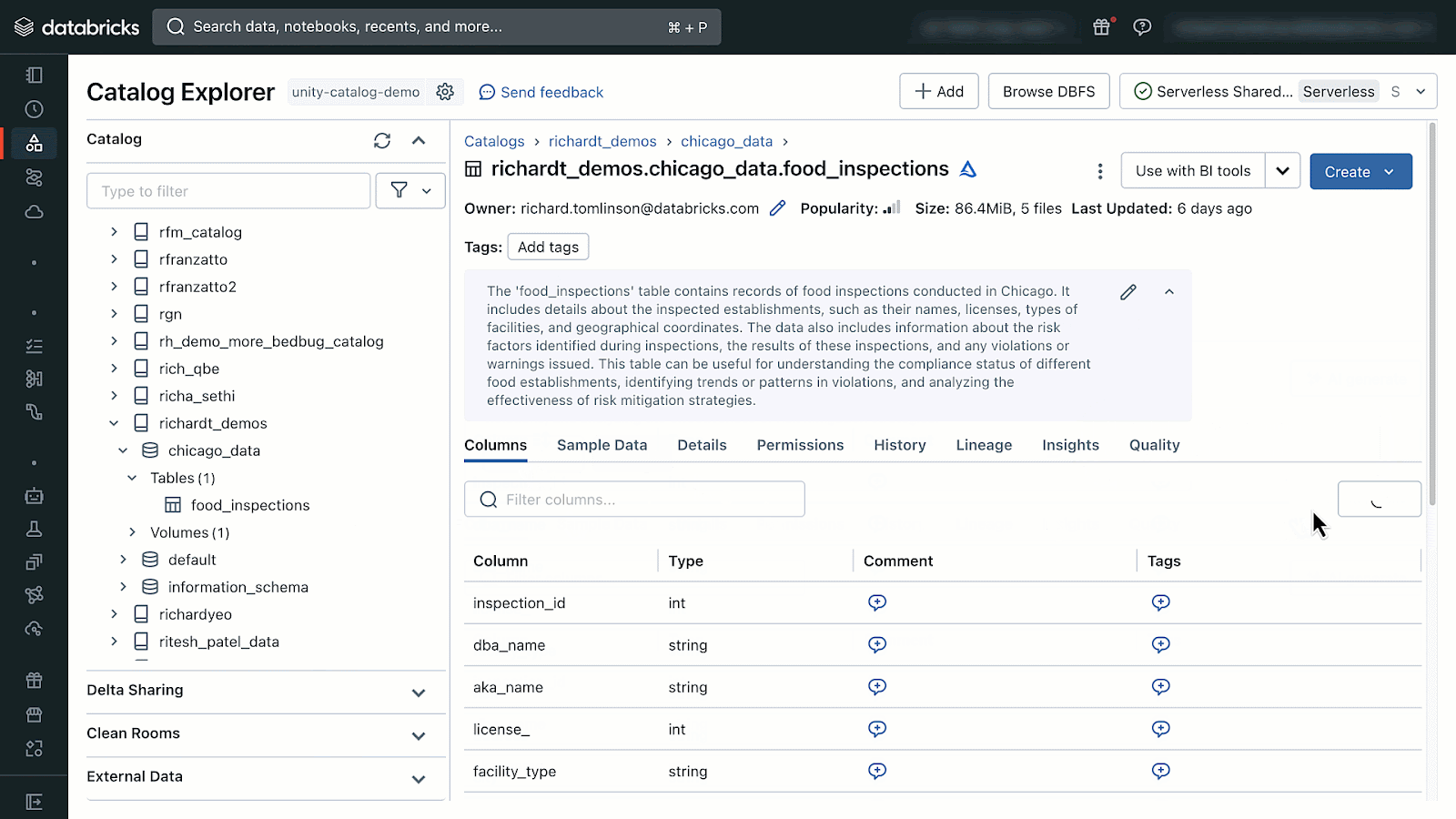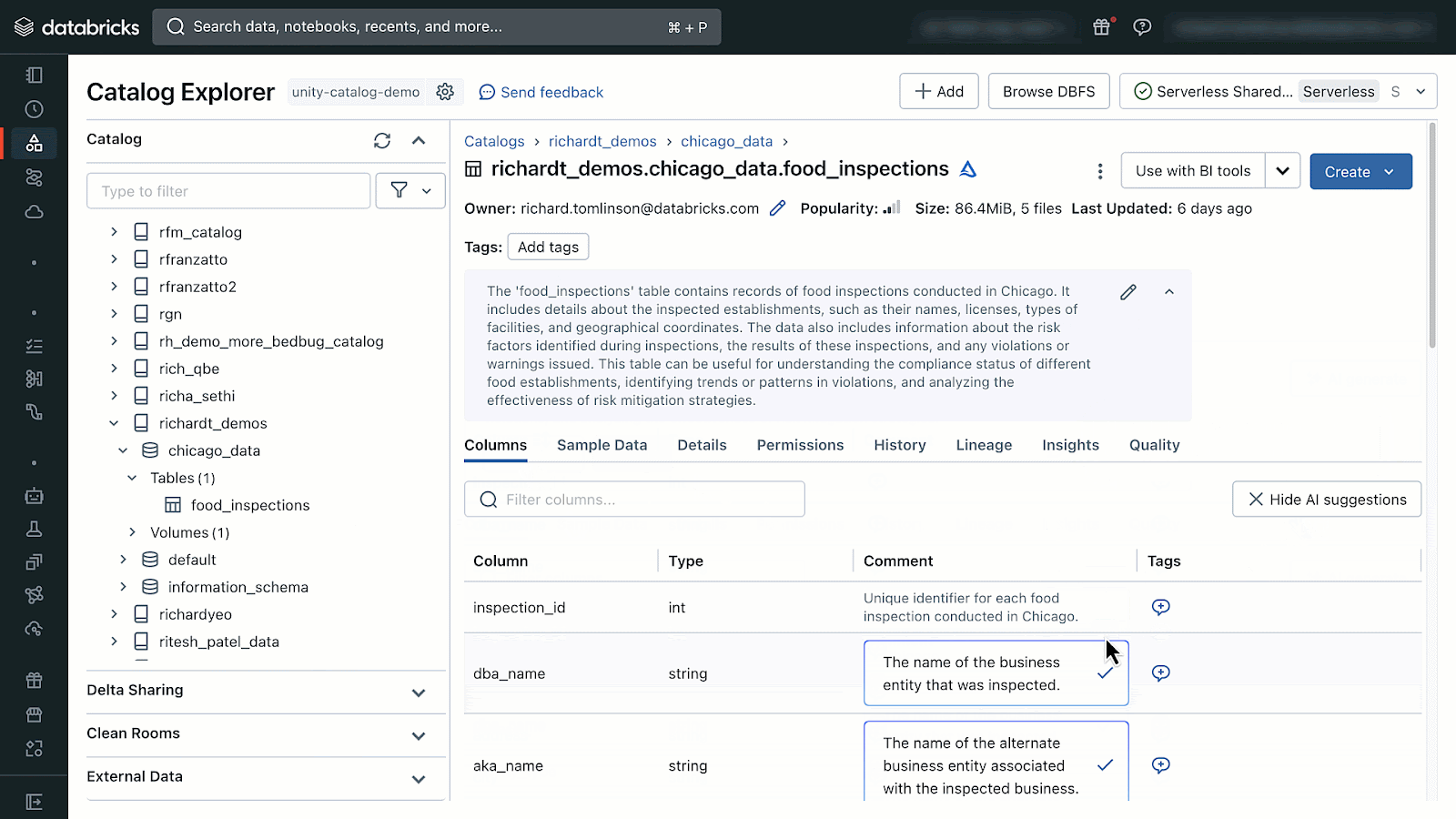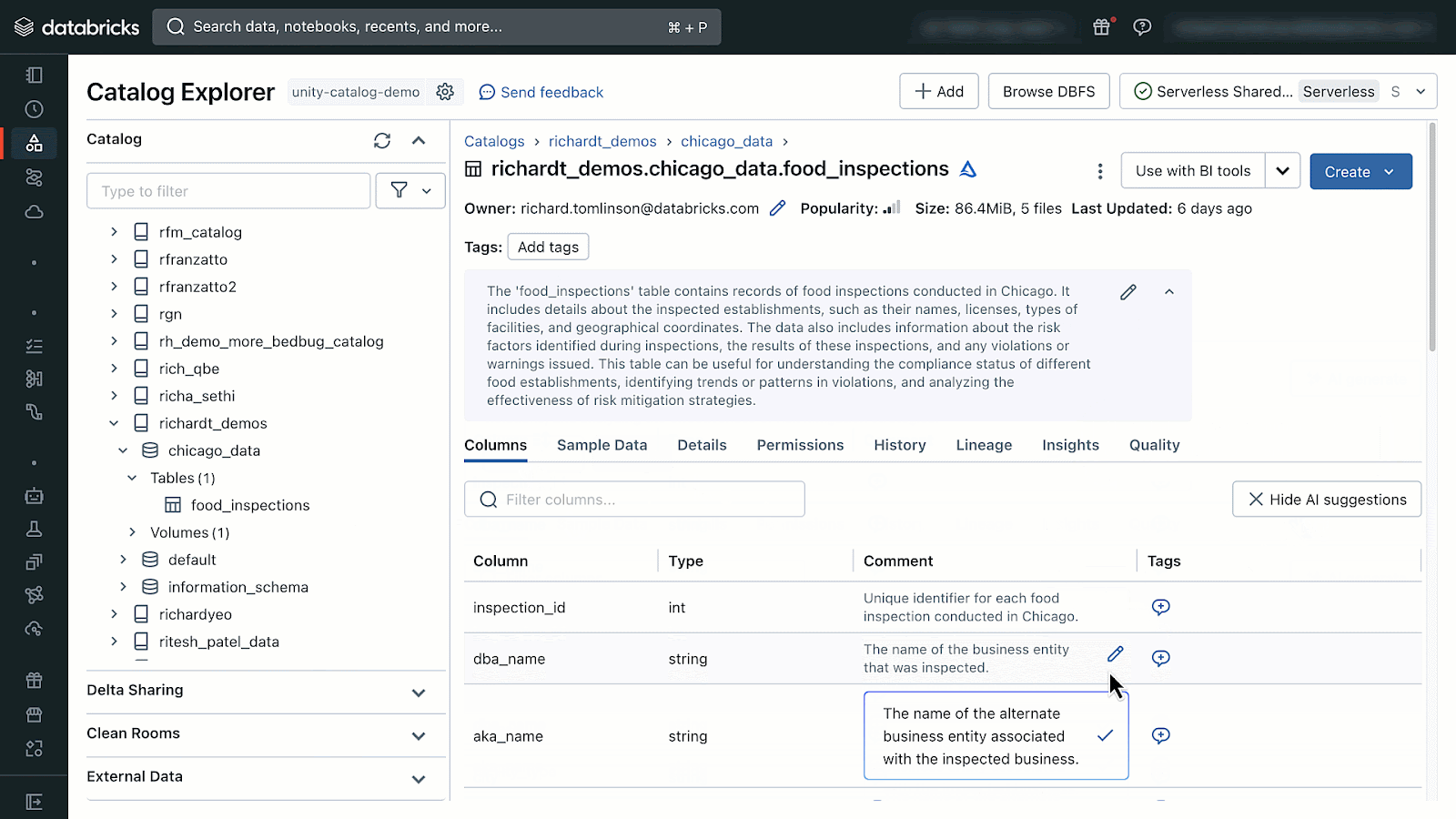
{kind=link}
If you happen to don’t see the AI-generated feedback icons your administrator can observe the directions documented right here to allow DatabricksIQ options in your Databricks Account and workspaces.